计算机的三大原则
硬件和软件的区别是什么?
硬件是看得见摸得着的设备,比如计算机主机、显示器、键盘等。而软件是计算机所执行的程序,即指令和数据。软件本身是看不见的。
存储字符串“中国”需要几个字节?
在GBK字符编码下,一个汉字占用2个字节。而在UTF-8字符编码下,一个汉字占用3个字节。
什么是编码(Code)?
通常将为了便于计算机处理而经过数字化处理的信息称作编码。
输入、运算、输出是硬件的基础
计算机的硬件由大量的IC(Integrated Circuit,集成电路)组成(如 图1.1所示)。每块IC上都带有许多引脚。这些引脚有的用于输入,有的用于输出。IC会在其内部对外部输入的信息进行运算,并把运算结果输出到外部。
计算机只会输入、运算、输出
软件是指令和数据的集合
所谓指令,就是控制计算机进行输入、运算、输出的命令。把向计算机发出的指令一条条列出来,就得到了程序。
试着制造一台计算机
CPU 是 Central Processing Unit(中央处理器)的缩写。
Hz(赫兹)是频率的单位
Z80 CPU 是 8 比特的 CPU
制作微型计算机所必需的元件
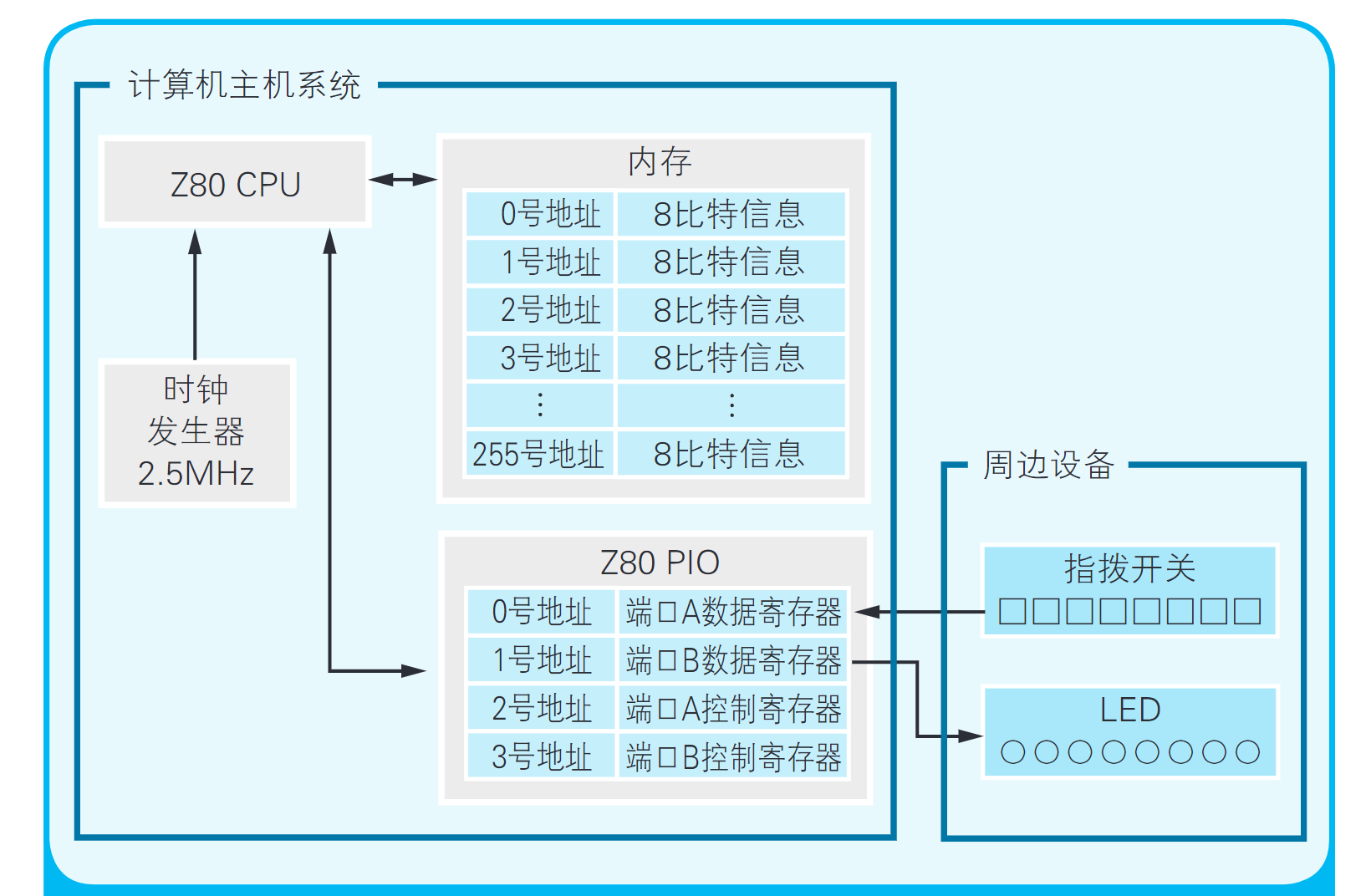
首先让我们来收集元件吧。制作微型计算机所需的基础元件只有3个,CPU、内存和I/O。CPU是计算机的大脑,负责解释、执行程序。内存负责存储程序和数据。I/O是Input/Output(输入/输出)的缩写,负责将计算机和外部设备(周边设备)连接在一起。
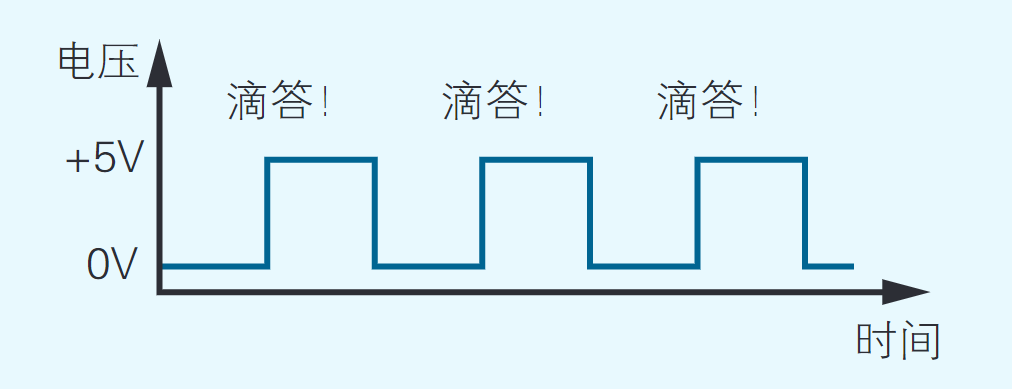
为了驱动CPU运转,称为“时 钟信号”的电信号必不可少。这种电信号就好像带有一个时钟,滴答滴答地每隔一定时间就变换一次电压的高低(如 图2.2所示)。输出时钟信号的元件叫作“时 钟发生器”。时钟发生器中带有晶振,根据其自身的频率(振 动的次数)产生时钟信号。时钟信号的频率可以衡量CPU的运转速度。这里使用的是2.5MHz(兆赫兹)的时钟发生器。
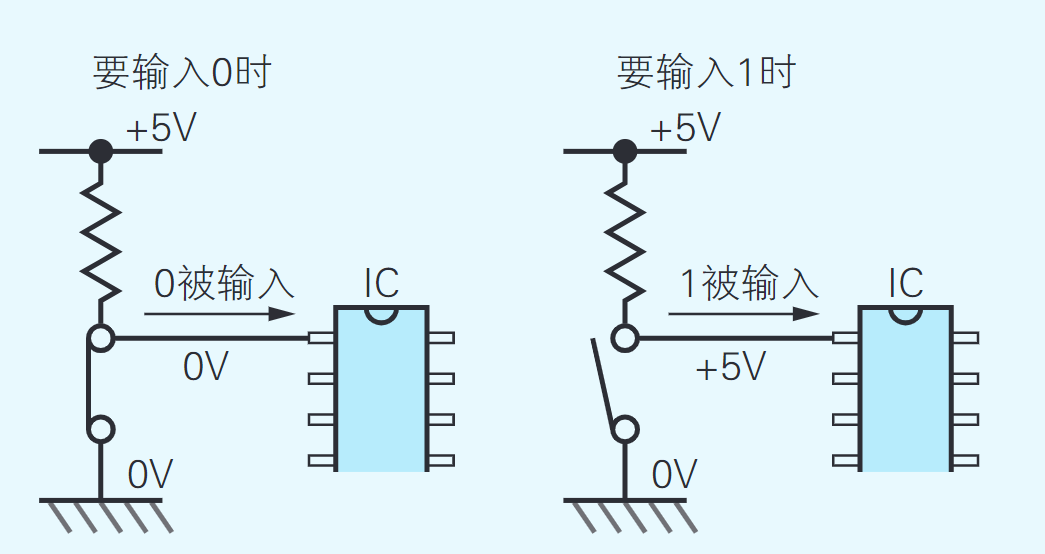
用于输入程序的装置也是必不可少的。在这里我们通过拨动指拨开关来输入程序,指拨开关是一种由8个开关并排连在一起构成的元件(如 照片2.1(a)所示)。输出程序执行结果的装置是8个LED(发 光二极管)
电路图的读法
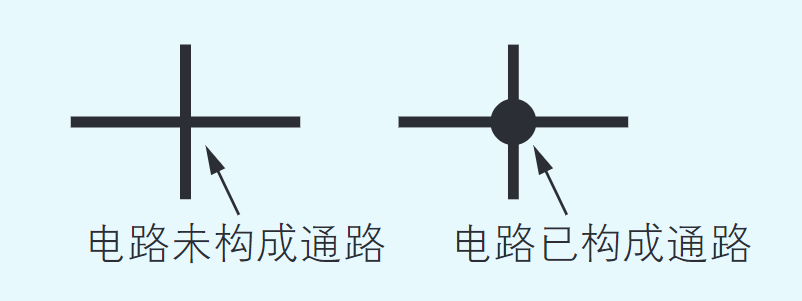
在电路图中,用连接着各种元件符号的直线表示如何布线。电路中有些地方有交叉,但若只是交叉在一起的话,并不表示电路在交叉处构成通路。只有在交叉处再画上一个小黑点才表示构成通路。
IC的引脚(所 谓引脚就是IC边缘露出的像蜈蚣腿一样的部分)按照逆时针方向依次带有一个从1开始递增的序号。数引脚序号时,要先把表示正方向的标志,比如半圆形的缺口,朝向左侧。举例来说,带有14个引脚的7404,其引脚序号就如图2.5所示。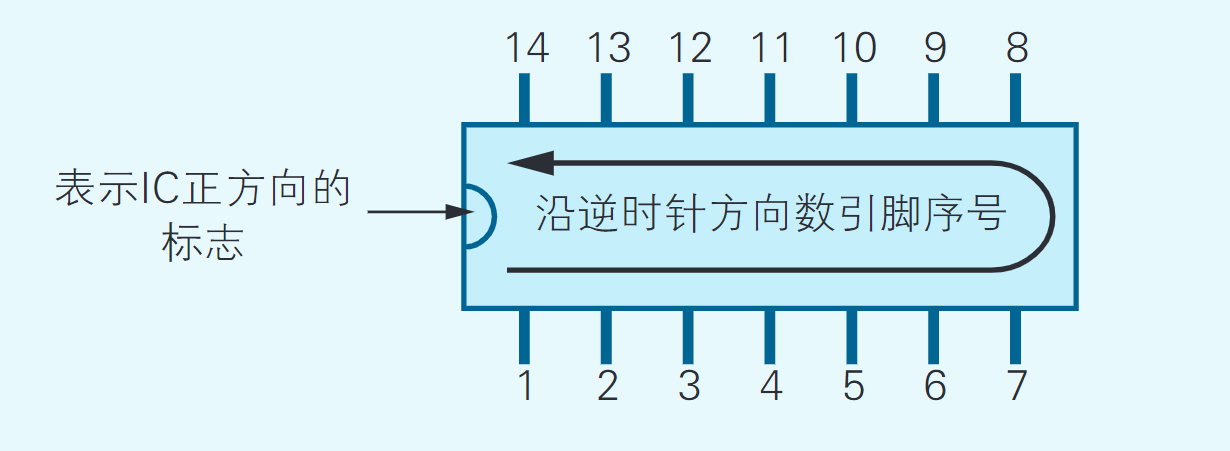
连接电源、数据和地址总线
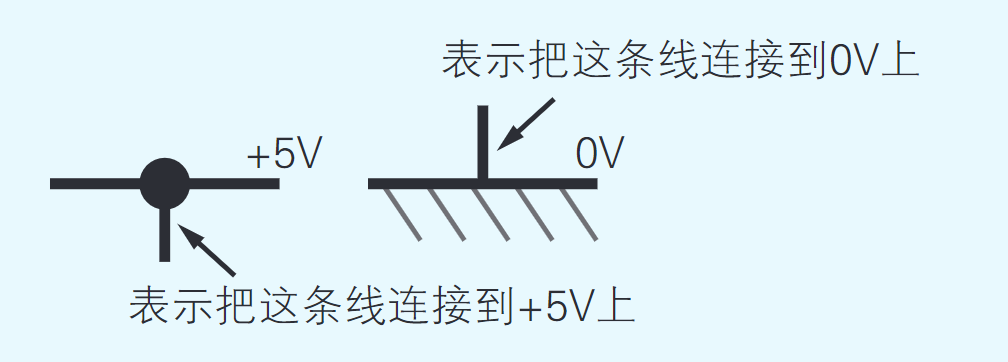
首先连接电源。IC与普通的电器一样,只有接通了电源才能工作。Z80 CPU、TC5517和Z80 PIO上都分别带有Vcc引脚和GND引脚。Vcc和GND这一对儿引脚用于为IC供电。
将+5V电源连接到各个IC的Vcc引脚上,然后将0V电源连接到各个IC的GND引脚上。接下来还需要将+5V和0V连接到时钟发生器上。接通电源后这些IC和时钟发生器就可以工作了。
微型计算机所使用的IC属于数字IC。在数字IC中,每个引脚上的电压要么是0V、要么是+5V,通过这两个电压与其他的IC进行电信号的收发。用于给IC供电的Vcc引脚和GND引脚上的电压是恒定不变的+5V和0V,但是其他引脚上的电压,会随着计算机的操作在+5V和0V之间不断地变化。
只要想成0V表示数字0、+5V表示数字1,那么数字IC就是在用二进制数的形式收发信息。
地址总线引脚
CPU可以与内存或I/O进行数据的输入输出。为了指定输入输出数据时的源头或目的地,CPU上备有“地址总线引脚”。Z80 CPU的地址总线引脚共有16个,用代号A0~A15表示,其中的A表示Address(地址)。后面的数字0~15表示一个16位的二进制数中各个数字的位置,0对应最后一位、15对应第一位。16个地址总线引脚所能指定的地址共有65536个,用二进制数表示的话就是0000000000000000~1111111111111111。因此Z80 CPU可以指定65536个数据存取单元(内 存存储单元或I/O地址),进行信息的输入输出。
数据总线引脚
一旦指定了存取数据的地址,就可以使用数据总线引脚进行数据的输入输出了。Z80 CPU的数据总线引脚共有8个,用代号D0~D7表示。其中的D表示Data(数据),后面的数字0~7与地址总线引脚代号的规则相同,也表示二进制数中各个数字的位置。Z80 CPU可以一次性地输入输出8比特的数据,这就意味着如果想要输入输出位数(比特数)大于8比特的数据,就要以8比特为单位切分这个数据。
作为内存的TC5517上也有地址总线引脚(A0~A10)和数据总线引脚(D0~D7) 。这些引脚需要同Z80 CPU上带有相同代号的引脚相连。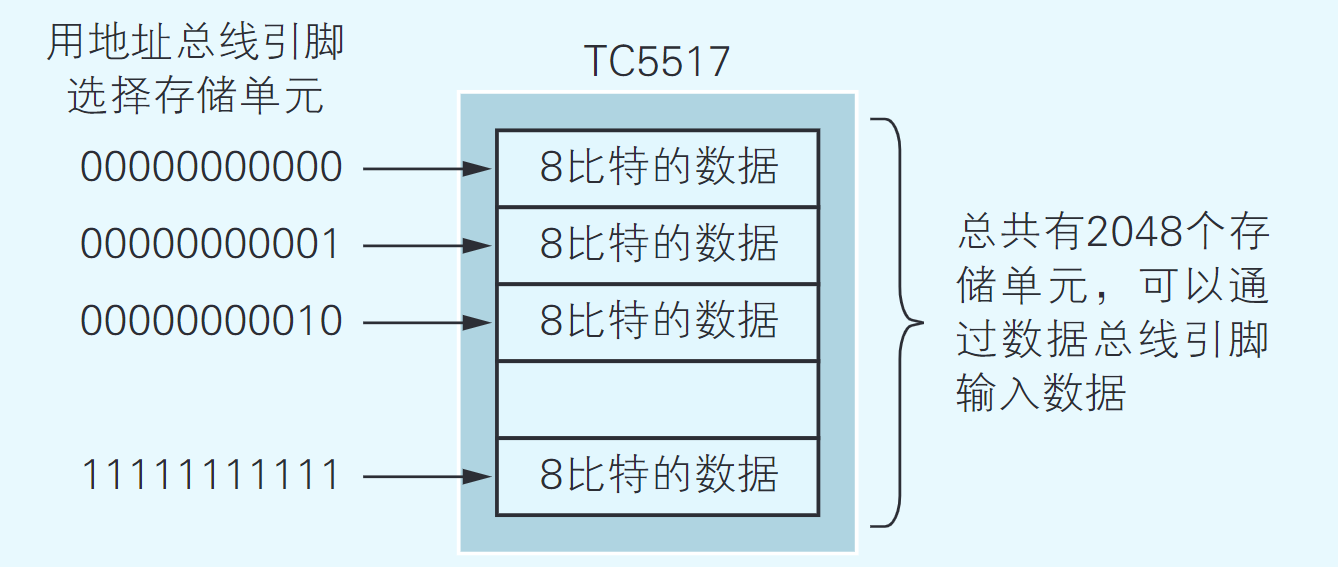
连接 I/O
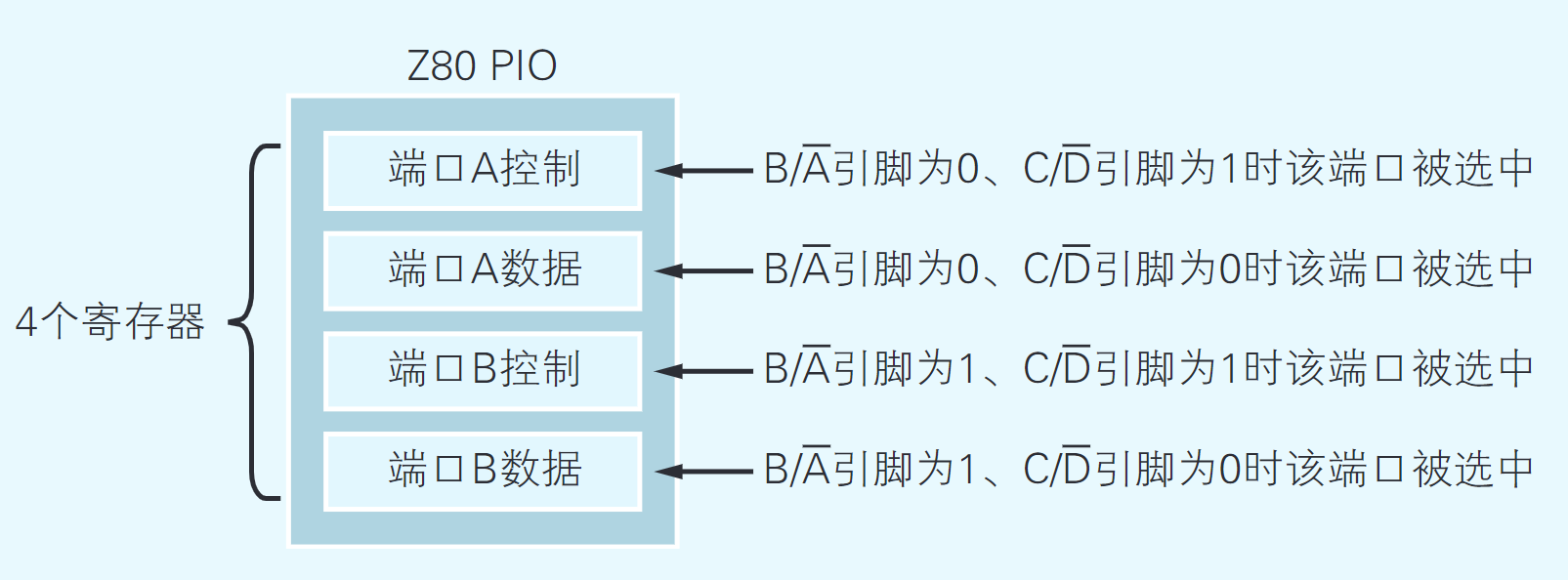
寄存器是位于CPU和I/O中的数据存储器。Z80 PIO上共有4个寄存器。2个用于设定PIO本身的功能,2个用于存储与外部设备进行输入输出的数据。
这4个寄存器分别叫作端口A控制、端口A数据、端口B控制和端口B数据。所谓端口就是I/O与外部设备之间输入输出数据的场所,可以把端口(Port)想象成是轮船装卸货物的港口。Z80 PIO有2个端口,端口A和端口B,最多可以连接2个用于输入输出8比特数据的外部设备(如图2.7所示)
下面就开始布线吧。因为Z80 PIO上也有D0~D7的数据总线引脚,所以先把它们和Z80 CPU中带有同样代号的引脚连接起来。这样CPU和PIO就能使用这8个引脚交换数据了。
连接时钟信号
Z80 CPU和Z80 PIO的运转离不开时钟信号。为了传输时钟信号,就需要把时钟发生器的8号引脚和Z80 CPU的CLK(CLK即Clock,时钟)引脚、Z80 PIO的CLK引脚分别连接起来。时钟发生器的8号引脚与+5V之间的电阻用于清理时钟信号。
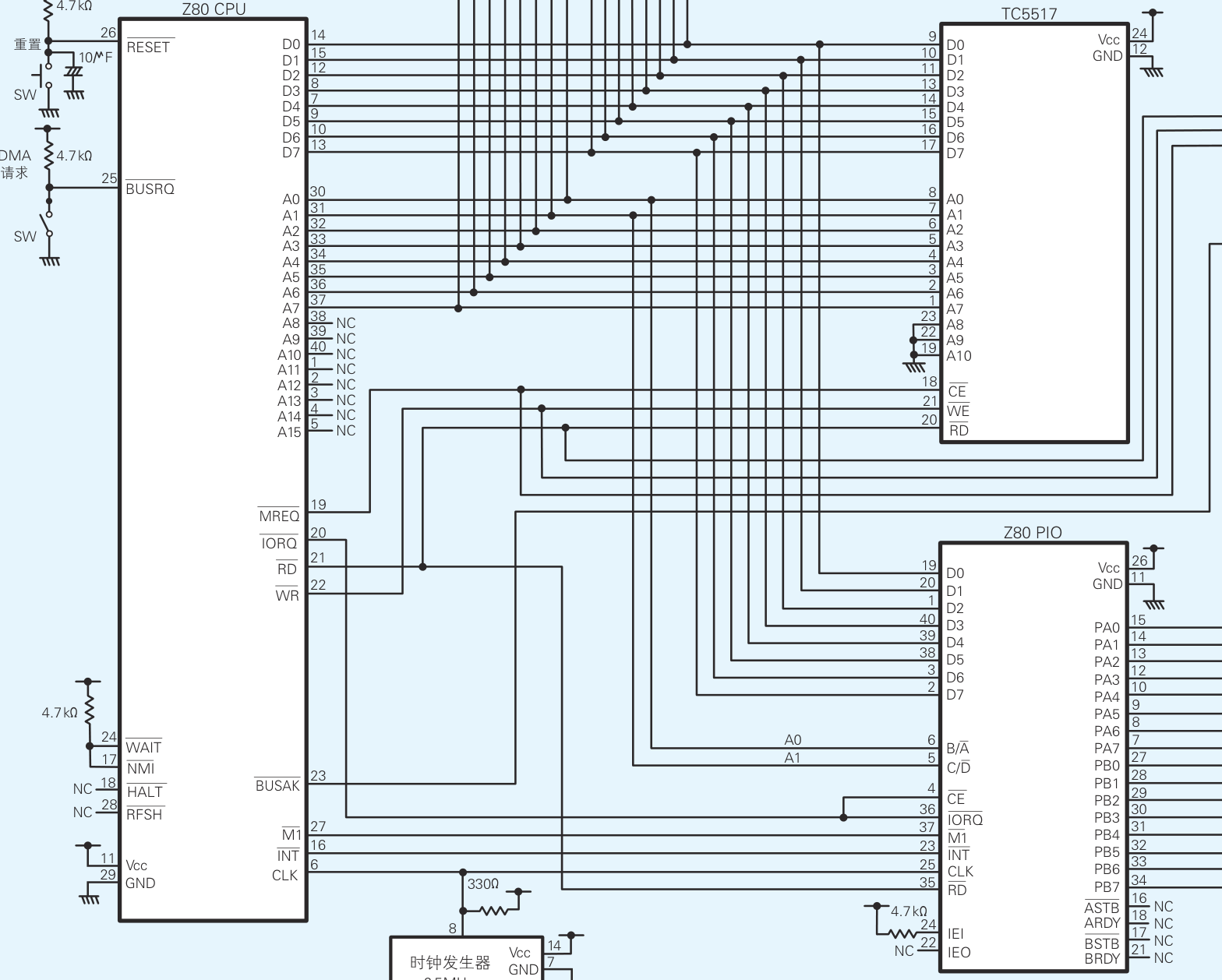
连接用于区分读写对象是内存还是 I/O 的引脚
至此,我们已经先后把Z80 CPU连接到了TC5517和Z80 PIO上,这两次连接都使用了地址总线引脚A0和A1。如果仅仅这样连接,就会导致一个问题,当地址的最后两位是00、01、10和11时,CPU就无法区分访问的是TC5517中的存储单元,还是Z80 PIO中的寄存器了。
Z80 CPU上的MREQ(即Memory Request,内存请求)引脚和IORQ(即I/O Request,I/O请求)引脚解决了这个问题。当Z80 CPU和内存之间有数据输入输出时,MREQ引脚上的值是0,反之则是1。当Z80 CPU和I/O之间有数据输入输出时,IORQ引脚上的值是0,反之则是1。
对内存和I/O而言,还必须要分清CPU是要输入数据还是输出数据。为此就要用到Z80 CPU的RD引脚(即Read,表示输入,为0时执行输入操作)和WR引脚(即Write,表示输出,为0时执行输出操作)了。请把这两个引脚与TC5517上同名的引脚连接起来。Z80 PIO虽然只有RD引脚,但由于数字IC引脚上的值要么是0要么是1,所以只用1个RD引脚也能区分是输入还是输出,0的话是输入,1的话就是输出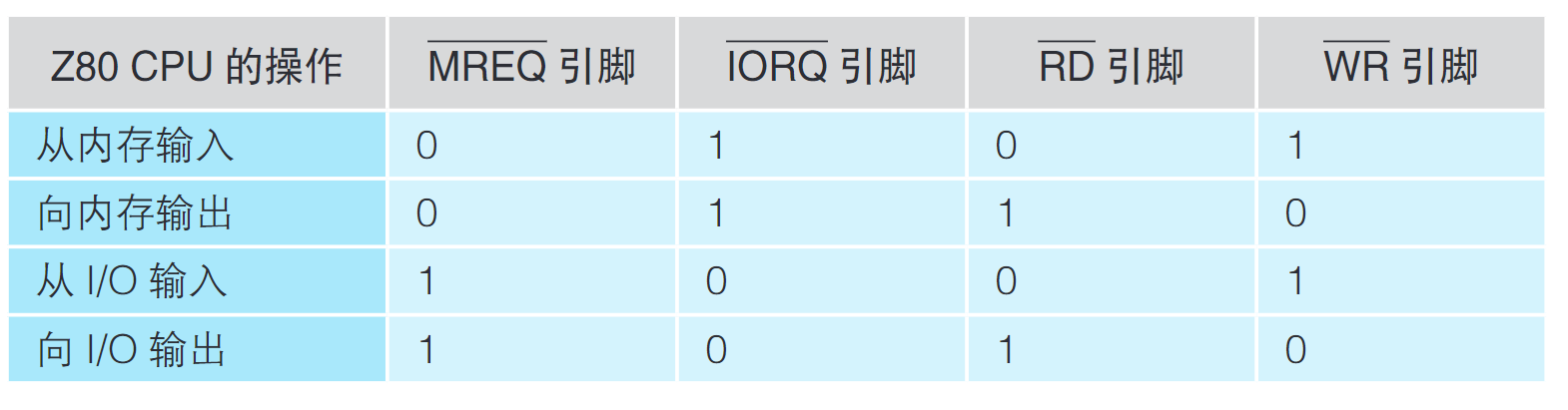
连接剩余的控制引脚
CPU、内存、I/O中不但有地址总线引脚、数据总线引脚,还有其他引脚,通常把这些引脚统称为“控 制引脚”。之所以这样命名是因为这些引脚上输入输出的电信号具有控制IC的功能。
首先把Z80 CPU的M1引脚(即Machine Cycle 1,机器周期1)和INT引脚(即Interrupt,中断)与Z80 PIO上标有相同代号的引脚连接起来。M1是用于同步的引脚,INT引脚是用于从Z80 PIO向Z80 CPU发出中断请求的引脚。所谓中断就是让CPU根据外部输入的数据执行特定的程序。
一旦把Z80 CPU的RESET引脚(即Reset,重置)上的值先设成0再还原成1,CPU就会被重置,重新从内存0号地址上的指令开始顺序往下执行。重置CPU可以通过按键开关完成。
总线是连接到CPU中数据引脚、地址引脚、控制引脚上的电路的统称。使用快动开关可以使Z80 CPU的BUSRQ引脚(即Bus Request,总线请求)上的值在0和1之间切换。若将BUSRQ引脚的值设为0,则Z80 CPU从电路中隔离。当处于这种隔离状态时,就可以不通过CPU,手动地向内存写入程序了。像这样不经过CPU而直接从外部设备读写内存的行为叫作DMA(Direct Memory Access,直接存储器访问)。在个人计算机里,硬盘等设备要读写内存时使用的就是DMA。
当Z80 CPU从电路中隔离后,BUSAK引脚(即Bus Acknowledge,响应总线请求)上的值就会变成0。也就是说,把BUSRQ引脚上的值设成0以后,还要确认BUSAK引脚上的值已经变成了0,然后才能进行DMA。
连接外部设备,通过 DMA 输入程序
这次将计算机主机系统和外部设备连接起来。我们要使用2个指拨开关和1个按键开关,向地址总线引脚和数据总线引脚发送电信号,然后通过DMA将数据总线上的数据存储到内存。
手工汇编
什么是机器语言?
由二进制数字构成的程序,CPU 可以直接对其解释、执行。
通常把标识内存或 I/O 中存储单元的数字称作什么?
标识内存或 I/O 中存储单元的数字叫作“地址”。
CPU 中的标志寄存器(Flags Register)有什么作用?
用于在运算指令执行后,存储运算结果的某些状态。
从程序员的角度看硬件
即便是相同的机器语言,例如01010011,只要CPU的种类不同,对它的解释也就不同。有的CPU会把它解释成是执行加法运算,有的CPU会把它解释成是向I/O输出。
所谓时钟信号的频率,就是由时钟发生器发送给CPU的电信号的频率。表示时钟信号频率的单位是MHz(兆赫兹= 100万回/秒)。微型计算机使用的是2.5MHz的时钟信号。时钟信号是在0和1两个数之间反复变换的电信号,就像滴答滴答左右摆动的钟摆一样。通常把发出一次滴答的时间称作一个时钟周期。
所谓I/O的地址空间,是指用于指定I/O寄存器的地址范围。在Z80 PIO上,地址空间为0~3,每一个地址对应一个寄存器。
在内存中,每个地址的功能都一样,既可用于存储指令又可用于存储数据。而I/O则不同,地址编号不同(即 寄存器的类型不同),功能也就不同。在微型计算机中,是这样分配Z80 PIO上的寄存器的:端口A数据寄存器对应0号地址,端口B数据寄存器对应1号地址,端口A控制寄存器对应2号地址,端口B控制寄存器对应3号地址。端口A数据寄存器和端口B数据寄存器存储的是与周边设备进行输入输出时所需的数据。其中,端口A连接用于输入数据的指拨开关,端口B连接用于输出数据的LED。而端口A控制寄存器和端口B控制寄存器则存储的是用于设定Z80 PIO功能的参数。
机器语言和汇编语言
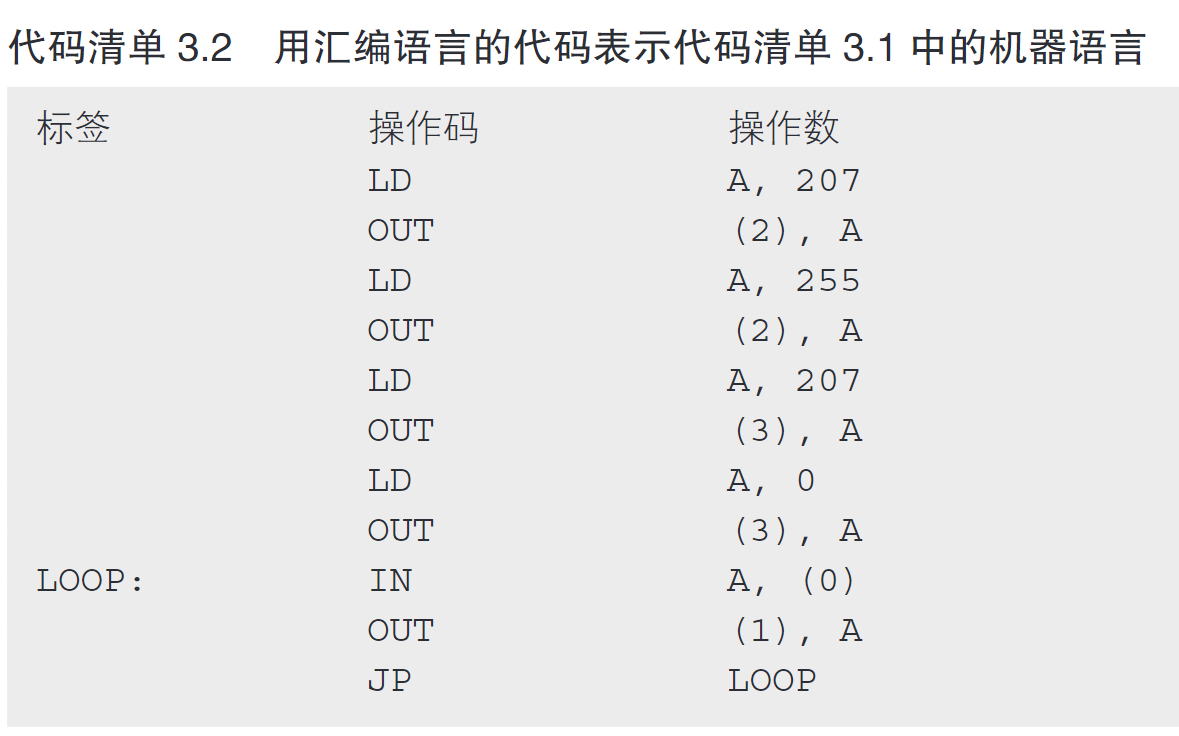
标签的作用是为该行代码对应的内存地址起一个名字。
操作码就是表示“做什么”的指令,比如LD是Load(加载)的缩写。
操作数表示的是指令执行的对象。CPU的寄存器、内存地址、I/O地址或者直接给出的数字都可以作为操作数。
Z80 CPU的MREQ引脚和IORQ引脚实现了一种能区分输入输出对象的机制,可以区分出使用着相同内存地址的内存和I/O。在汇编语言中,读写内存的指令不同于读写I/O的指令。一旦执行了读写内存的指令,比如LD指令,MREQ引脚上的值就会变为0,于是内存被选为输入输出的对象;而一旦执行了读写I/O的指令,比如IN或OUT指令,IORQ引脚上的值就会变为0,于是I/O(这 里用的是Z80 PIO)被选为输入输出的对象。
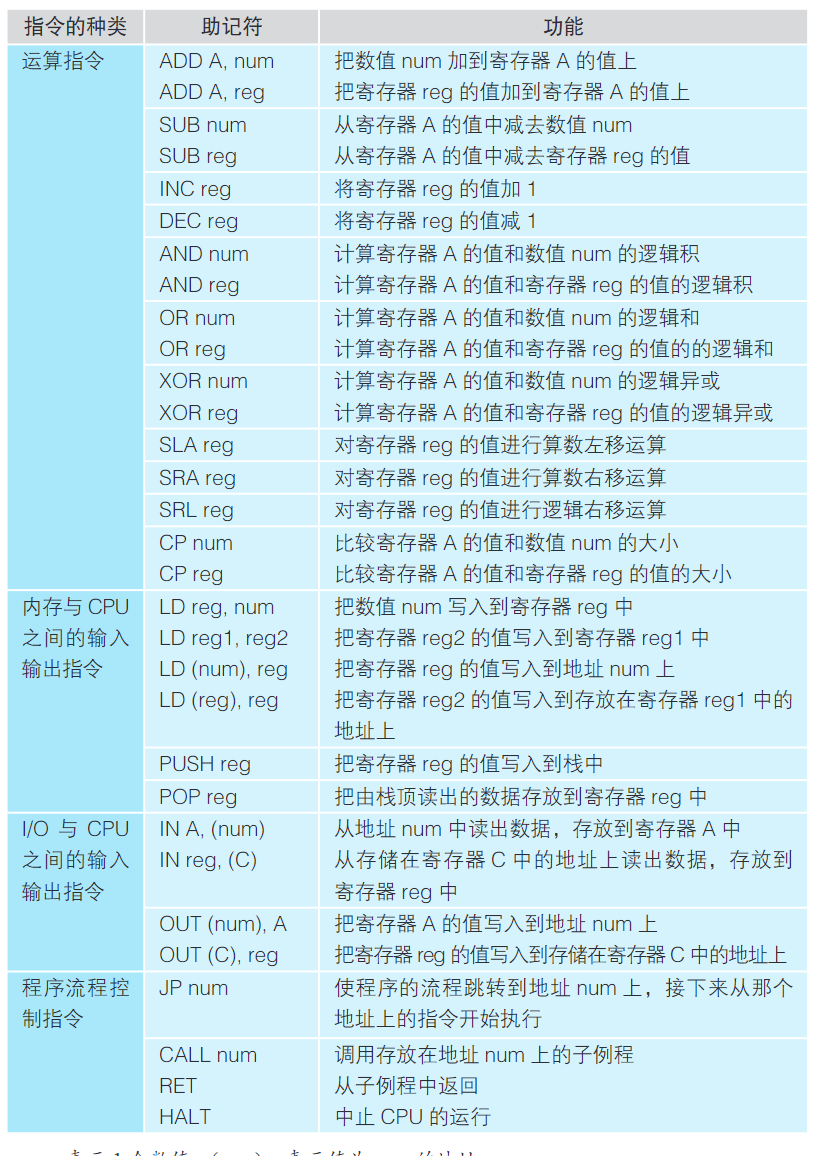
num:表示1个数值,(num):表示值为num的地址reg、reg1、reg2:名为reg、reg1、reg2的寄存器,(reg):存储在名为reg的寄存器中的地址
Z80 CPU 的寄存器结构
既然数据的运算是在CPU中进行的,那么在CPU内部就应该有存储数据的地方。这种存储数据的地方叫作“寄 存器”。虽然也叫寄存器,但是与I/O的寄存器不同,CPU的寄存器不仅能存储数据,还具备对数据进行运算的能力。CPU带有什么样的寄存器取决于CPU的种类。Z80 CPU所带有的寄存器如图3.2所示A。A、B、C、D等字母是寄存器的名字。在汇编语言当中,可以将寄存器的名字指定为操作数。
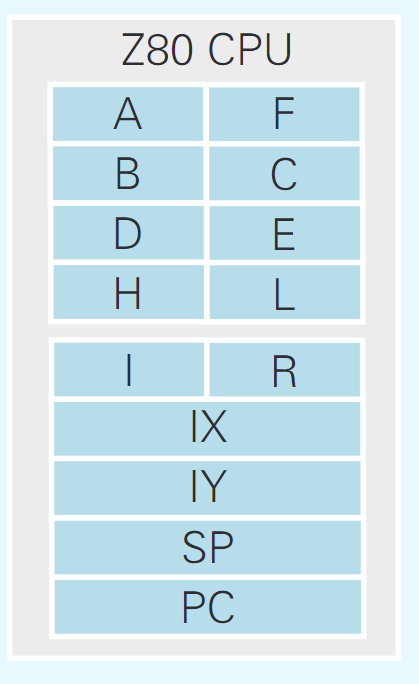
A、B、C、D、E、F、H、L每个寄存器都带有一个辅助寄存器
IX、IY、SP、PC这4个寄存器的大小是16比特,其余寄存器的大小都是8比特。寄存器的用途取决于它的类型。有的指令只能将特定的寄存器指定为操作数。
A寄存器也叫作“累 加器”,是运算的核心。所以连接到它上面的导线也一定会比其他寄存器的多。F寄存器也叫作“标 志寄存器”,用于存储运算结果的状态,比如是否发生了进位,数字大小的比较结果等。PC寄存器也叫作“程 序指针”,存储着指向CPU接下来要执行的指令的地址。PC寄存器的值会随着滴答滴答的时钟信号自动更新,可以说程序就是依靠不断变化的PC寄存器的值运行起来的。SP寄存器也叫作“栈 顶指针”,用于在内存中创建出一块称为“栈”的临时数据存储区域。
1 | LD A, 207 |
这里的207和255是连续向Z80 PIO的端口A控制寄存器(对 应该I/O的地址编号为2)写入的两个数据。虽然使用OUT指令可以向I/O写入数据,但是不能直接把207、255这样的数字作为OUT指令的操作数。操作数必须是已存储在CPU寄存器中的数字,这是汇编语言的规定.
完成了Z80 PIO的设定后,就进入了一段死循环处理,用于把由指拨开关输入的数据输出到LED。为了实现这个功能,需要如下的代码。
1 | LOOP: |
“IN A, (0)”的作用是把数据由端口A数据寄存器(连 接在指拨开关上,对应的I/O地址为0号)输入到CPU的寄存器A。“OUT (1), A的作用是把寄存器A的值输出到端口B数据寄存器上(连 接在LED上,对应的I/O地址为1号)
“JP LOOP”的作用是使程序的流程跳转到LOOP(笔者随意起的一个标签名)标签所标识的指令上。JP是Jump的缩写。 “IN A, (0)”所在行的开头有一个标签“LOOP:” ,代表着这一行的内存地址。
追踪程序的运行过程
用汇编语言编写的程序是不能直接运行的,必须先转换成机器语言。机器语言是唯一一种CPU能直接理解的编程语言。
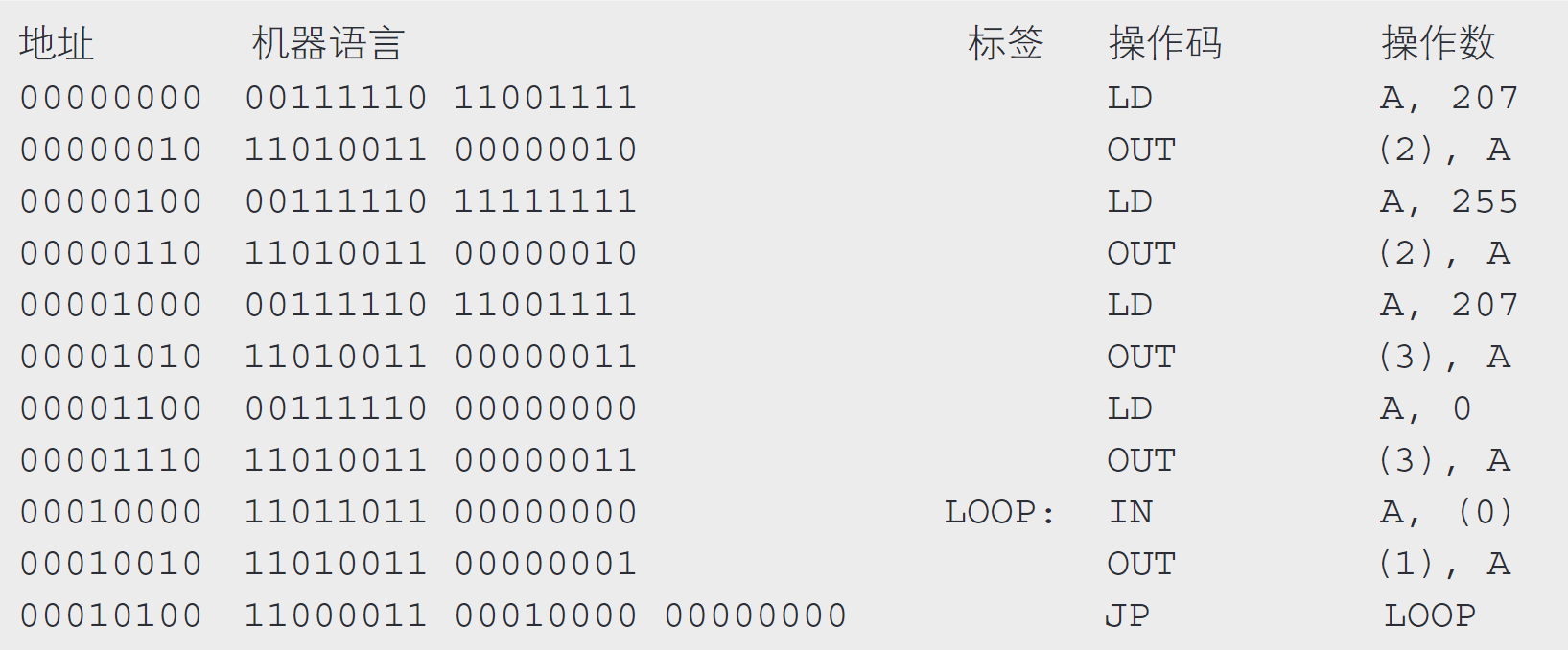
一旦重置了CPU,00000000就会被自动存储到PC寄存器中,这意味着接下来CPU将要从00000000号地址读出程序。首先CPU会从00000000号地址读出指令001 11110,判断出这是一条由2个字节构成的指令,于是接下来会从下一个地址(即00000001,1号地址,代码清单3.3中并没有标记出该地址本身)读出数据11001 111,把这两个数据汇集到一起解释、执行。执行的指令是把数值207写入到寄存器A,用汇编语言表示的话就是“LD A, 207” 。这时,由于刚刚从内存读出了一条2字节的指令(占 用2个内存地址),所以PC寄存器的值要增加2,并接着从00000010号地址读出指令,解释并执行。
接下来的流程与此类似,通过反复进行“读 取指令”“解 释、执行指令”“更 新PC寄存器的值”这3个操作,程序就能运行起来了。一旦执行完最后一行的JP LOOP所对应的机器语言,PC寄存器的值就会被设为标签LOOP对应的地址00010000,这样就可以循环执行同样的操作。请诸位重点观察PC寄存器是如何控制程序流程的。
尝试手工汇编
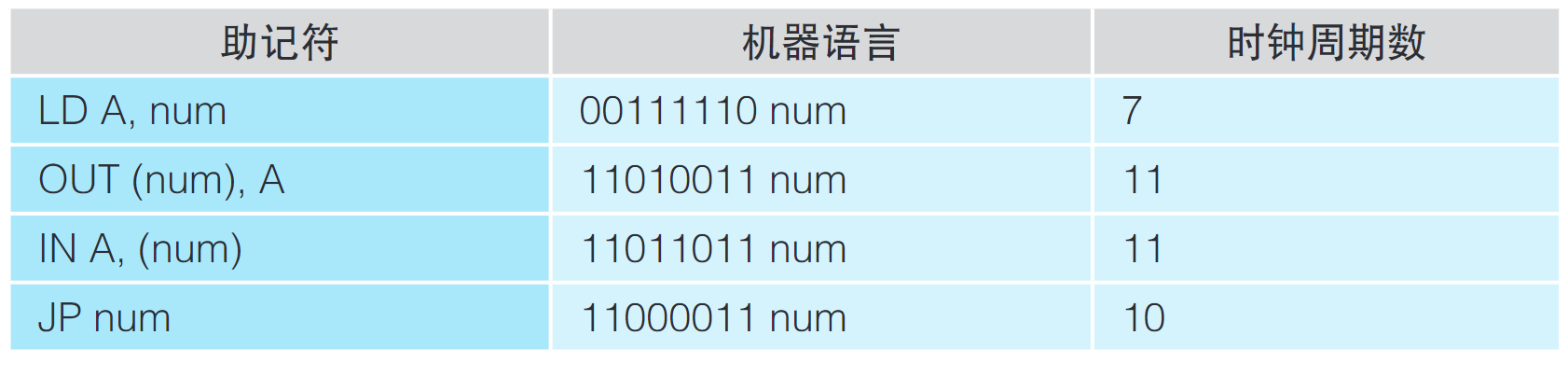
下面就从汇编语言的第1行开始转换。第一行的“LD A, 207”匹配“LD A, num”这个模式,所以可以先转换成“00111110 num” 。然后将十进制数的207转换成8比特的二进制数,用这个二进制数替换num。
第2条指令“OUT (2), A”匹配“OUT (num), A”这个模式,所以可以先转换成“1 1010011 num” 。然后把num的部分替换成00000010,即用8比特的二进制数表示的十进制数2,最终就得到了机器语言“1 1010011 00000010”。因为内存中已经存储了2字节的机器语言,所以这条机器语言要从00000010号地址(用 十进制表示的话就是2号地址)开始记录。

机器语言中每条语句的字节数是多少,内存地址就相应地增加多少。
接下来是“IN A, (0)”匹配“IN A, (num)”这个模式,所以可以先转换成“11011011 num”。然后把num替换成00000000,即用8比特的二进制数表示的十进制数0,最终就得到了机器语言“11011011 00000000”。对于接下来的“OUT (1), A”,也可以按照同样的方法转换
最后一句的JP LOOP匹配模式“JP num” ,所以可以先转换成“1 1000011 num” 。请注意这里要用16比特的二进制数替代作为内存地址的num。在微型计算机中是以8比特为单位指定内存地址的,但在Z80 CPU中用于设定内存地址的引脚却有16个,所以在机器语言中也要用16比特的二进制数设定内存地址。JP指令跳转的目的地为00010000,即“LOOP:”标签所标示的语句“LD A, 0”对应的内存地址。把这个地址扩充为16比特就是“00000000 00010000”。要扩充到16位,只需要把高8位全部设为0就可以了。
在将一个2字节的数据存储到内存时,存储顺序是低8位在前、高8位在后(也 就是逆序存储)。这样的存储顺序叫作“小 端序”(Little Endian) ,与此相反,将数据由高位到低位顺序地存储到内存的存储顺序则叫作“大 端序”(Big Endian) 。根据CPU种类的不同,有的CPU使用大端序,有的CPU使用小端序。Z80 CPU使用的是小端序,因此JP LOOP对应的机器语言为“1 1000011 00010000 00000000”。
程序像河水一样流动着
程序的流程分为三种
计算机的硬件系统由CPU、I/O和内存三部分构成。内存中存储着程序,也就是指令和数据。CPU配合着由时钟发生器发出的滴答滴答的时钟信号,从内存中读出指令,然后再依次对其进行解释和执行。
CPU中有各种各样的各司其职的寄存器。其中有一个被称为PC(Program Counter,程序计数器)的寄存器,负责存储内存地址,该地址指向下一条即将执行的指令。每解释执行完一条指令,PC寄存器的值就会自动被更新为下一条指令的地址。
在计算机硬件上的操作中,循环是通过当满足条件时就返回到之前处理过的步骤来实现的。一旦使用了机器语言或汇编语言所提供的跳转指令,就可以将PC寄存器的值设置为任意的内存地址。如果将它的值设为之前执行过的步骤所对应的内存地址,那么就构成了循环。
特殊的程序流程——中断处理
中断处理是指计算机使程序的流程突然跳转到程序中的特定地方,这样的地方被称为中断处理例程(Routine)或是中断处理程序(Handler) ,而这种跳转是通过CPU所具备的硬件功能实现的。
在Z80 CPU中有INT和NMI两个引脚,它们可以接收从I/O设备发出的中断请求信号A。以硬件形式连接到CPU上的I/O模块会发出中断请求信号,CPU根据该信号执行相应的中断处理程序。
每当用户按下键盘上的按键,键盘上的I/O模块就会把中断请求信号发送给CPU。CPU通过这种方式就可以知道有按键被按下,于是就会从I/O设备读入数据(如 图4.14所示)。CPU并不会时刻监控键盘是否有按键被按下。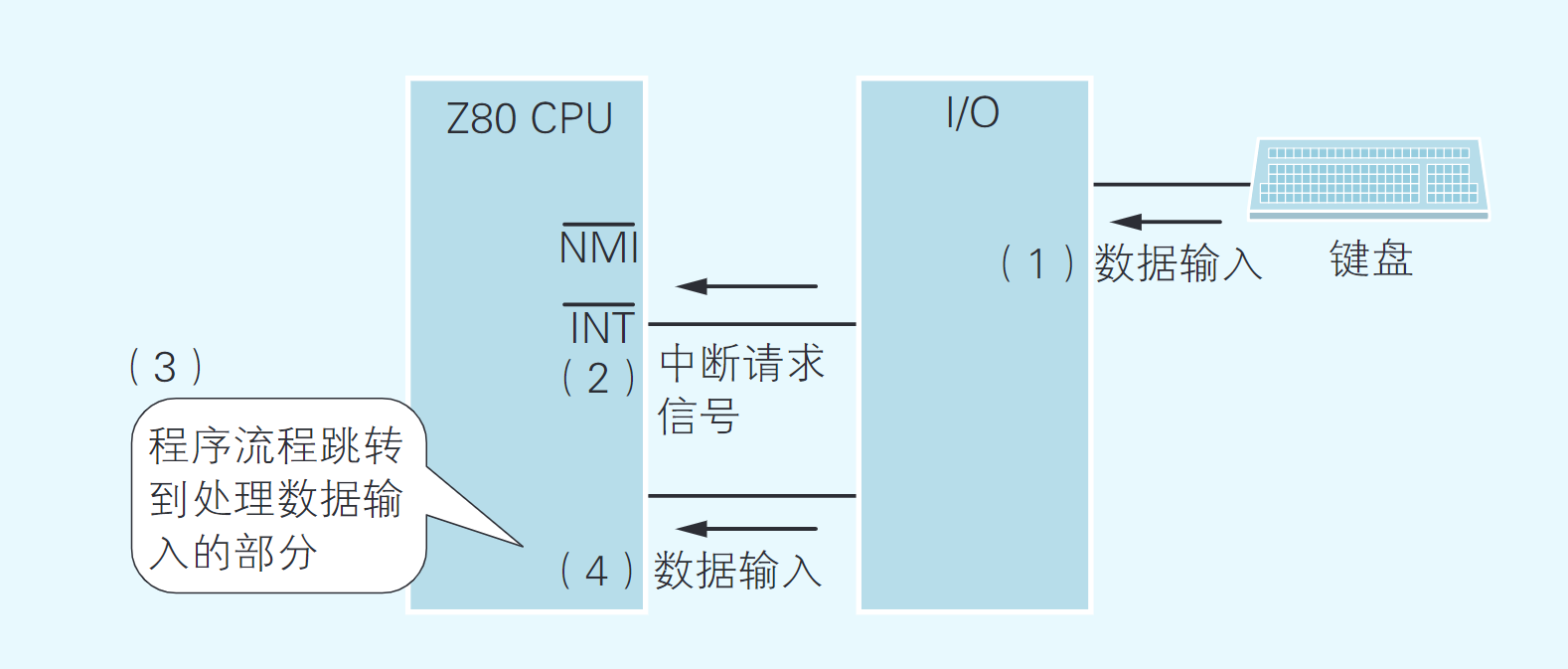
特殊的程序流程——事件驱动
通常把用户在应用程序中点击鼠标或者敲击键盘这样的操作称作“事 件”(Event) 。负责检测事件的是Windows。Windows通过调用应用程序的WndProc()函数通知应用程序事件的发生。而应用程序则根据事件的类型做出相应的处理。这种机制就是事件驱动。
程序的流程还是只有顺序执行、条件分支和循环这三种,这一点是没有改变的。其中的顺序执行是最基本的程序流程,这是因为CPU中的PC寄存器的值会自动更新。条件分支和循环,在高级语言中用程序块表示,在机器语言和汇编语言中用跳转指令表示,在硬件上是通过把PC寄存器的值设为要跳转到的目的地的内存地址来实现。
算法
哨兵”指的是一种含有特殊值的数据,可用于标识数据的结尾等。字符串的末尾用0表示,链表的末尾用-1表示,像这种特殊的数据就是哨兵。
算法是程序设计的“熟语
算法中解决问题的步骤是明确且有限的

哨兵
假设有100个箱子,里面分别装有一个写有任意数字的纸条,箱子上面标有1~100的序号。现在要从这100个箱子当中查找是否有箱子装有写着要查找数字的纸条。
首先看看不使用哨兵的方法。从第一个箱子开始依次检查每个箱子中的纸条。每检查完一个纸条,还要再检查箱子的编号(用 变量N表示),并进一步确认编号是否已超过最后一个编号了。
为了消除这种不必要的处理,于是添加了一个101号箱子,其中预先放入的纸条上写有正要查找的数字。这种数据就被称为“哨 兵”。通过放入哨兵,就一定能找到要找的数据了。找到要找的数据后,如果该箱子的编号还没有到101就意味着找到了实际的数据;如果该箱子的编号是101,则意味着找到的是哨兵,而没有找到实际的数据。
数据结构
了解内存和变量的关系
计算机所处理的数据都存储在了被称为内存的IC(Integrated Circuit,集成电路)中。在一般的个人计算机中,内存内部被分割成了若干个数据存储单元,每个单元可以存储8比特的数据(8比特= 1字节)。
数组
数组是数据结构的基础,之所以这么说是因为数组反映了内存的物理结构本身。在内存中存储数据的空间是连续分布的。而在程序中,往往要从内存整体中分配出一块连续的空间以供使用。如果用程序中的语句表示这种分配使用方式的话,就要用到数组(如图6.2所示)
栈和队列
栈和队列的相似点在于,它们都可以把不能立刻处理的数据暂时存储起来;不同点在于,栈对所存储数据的存取方式是LIFO的,而队列对所存储数据的存取方式是FIFO的。
面向对象
面向对象编程
面向对象编程(OOP,Object Oriented Programming)是一种编写程序的方法,旨在提升开发大型程序的效率,使程序易于维护。
对 OOP 的多种理解方法
面向对象编程是一种基于以下思路的程序设计方法:将关注点置于对象(Object)本身,对象的构成要素包含对象的行为及操作B,以此为基础进行编程。这种方法使程序易于复用,软件的生产效率因而得以提升。其中所使用的主要编程技巧有继承、封装、多态三种。
观点 1:面向对象编程通过把组件拼装到一起构建程序
在面向对象编程中,使用了一种称为“类”的要素,通过把若干个类组装到一起构建一个完整的程序。从这一点来看,可以说类就是程序的组件(Component)。面向对象编程的关键在于能否灵活地运用类。
在大型程序中需要用到大量的函数和变量。假设要用非面向对象的编程方法编写一个由10000个函数和20000个变量构成的程序,那么结果就很容易是代码凌乱不堪,开发效率低到令人吃惊,维护起来也十分困难。
于是一种新的编程方法就被发明出来了,即把程序中有关联的函数和变量汇集到一起编成组。这里的组就是类。
观点 2:面向对象编程能够提升程序的开发效率和可维护性
观点 3:面向对象编程是适用于大型程序的开发方法
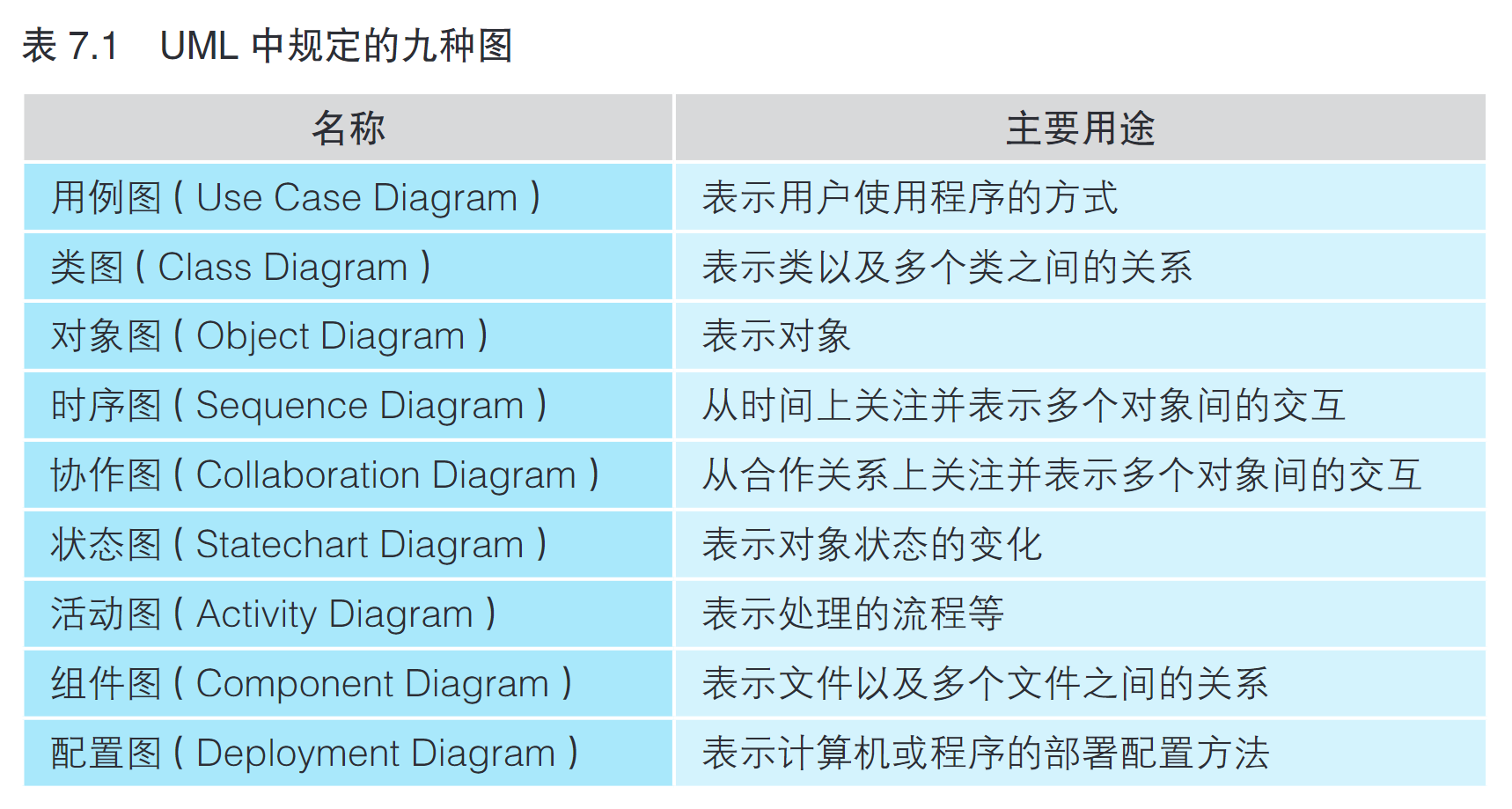
观点 5:面向对象编程可以借助 UML 设计程序
观点 6:面向对象编程通过在对象间传递消息驱动程序
观点 7:在面向对象编程中使用继承、封装和多态
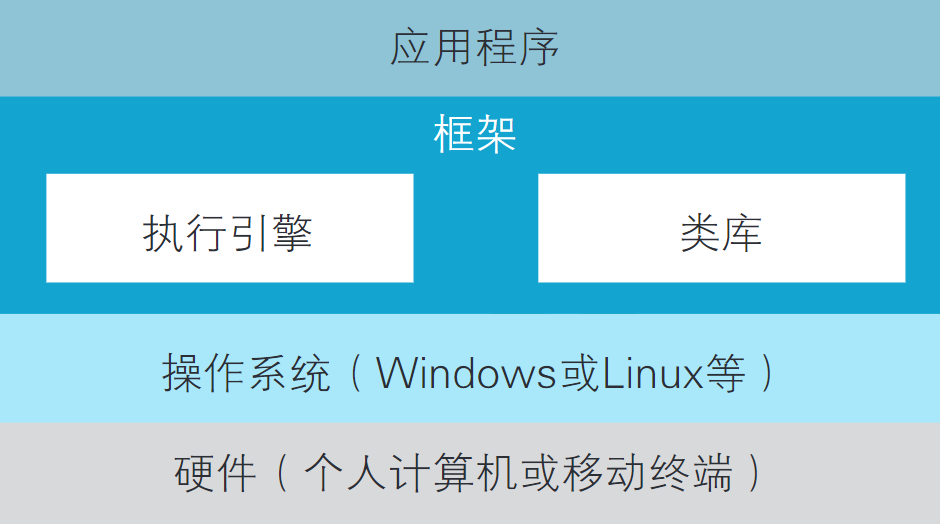
在 Java 和 .NET 中有关 OOP 的知识不能少
Java和.NET其实是位于操作系统(Windows或Linux等)之上,旨在通过隐藏操作系统的复杂性从而提升开发效率的程序集,这样的程序集也被称作“框 架”(Framework)。框架由两部分构成,一部分是负责安全执行程序的“执 行引擎”,另一部分是作为程序组件集合的“类库” (如图7.8所示)
数据库
数据库是数据的基地
适合存储大规模数据的是关系型数据库(Relational Database)。在关系型数据库中,数据被拆分整理到多张表中,同时表与表之间的关系也可以被记录下来。
数据文件、DBMS 和数据库应用程序
数据库的实质虽然是某种数据文件,但是诸位编写的应用程序并不是直接去读写这些数据文件,而是以DBMS作为中介间接地读写(如 图8.3所示)。DBMS不但可以使应用程序轻松地读写数据文件,而且还具有一致并且安全地存储数据的功能。
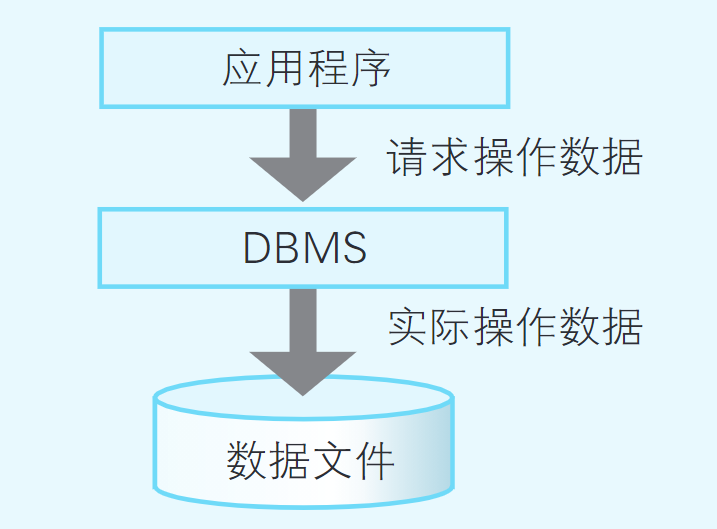
数据库系统的构成要素包括“数据文件”“DBMS” “应用程序”三部分。
在小型系统中,把三个要素全部部署在一台计算机上,称作“独立型系统”。在中型系统中,把数据文件部署在一台计算机上,并且使数据文件被部署了DBMS和应用程序的多台计算机共享,这样的系统被称为“文件共享型系统”。在大型系统中,把数据文件和DBMS部署在一台(或者多台)计算机上,然后用户从另外一些部署着应用程序的计算机上访问,这样的系统被称作“客户端/服务器型系统”。
其中部署着数据文件和DBMS的计算机是服务器(Server),即服务的提供者;部署着应用程序的计算机是客户端(Client),即服务的使用者。如果把服务器和客户端之间用互联网联结起来,就形成了Web系统。在Web系统中,一般情况下应用程序也是部署在服务器中的,在客户端只部署Web浏览器.
设计数据库
在关系型数据库中,把录入到表中的每一行数据都称为记录,把构成一条记录中的各个数据项(在本例中是商品名称、单价等)所在的列都称作字段。记录有时也被称为行或元组(Tuple) ,字段有时也被称为列或属性(Attribute)。上面提到的属性(数 据的类型)就是设置在字段上的。为了代表字段所存储数据的内容还要为每个字段起一个名字。
索引能够提升数据的检索速度
可以在表的各个字段上设置索引(Index) ,这也是DBMS所具备的功能之一。虽然索引和键这两个概念容易让人混淆,但其实两者是完全不同的。索引仅仅是提升数据检索和排序速度的内部机制。一旦在字段上设置了索引,DBMS就会自动为这个字段创建索引表。
索引表是一种数据结构,存储着字段的值以及字段所对应记录的位置。例如,如果在顾客表的顾客姓名字段上设置了索引,DBMS就会创建一张索引表(如 图8.13所示),表中有两个字段,分别存储着顾客姓名和位置(所 对应的记录在数据文件中的位置)。与原来的顾客表相比,索引表中的字段数更少,所以可以更快地进行数据的检索和排序。当查询数据时,DBMS先在索引表中进行数据的检索和排序,然后再根据位置信息从原来的数据表中把完整的记录取出来。索引所起的就是“目 录”的作用。与图书的目录一样,数据库的索引也是一种能够高效地查找目标数据的机制。
事务控制也可以交给 DBMS 处理
事务由若干条SQL语句构成,表示对数据库一系列相关操作的集合。
为了从顾客A的账户中给顾客B的账户汇入1万元,就需要将以下两条SQL语句依次发送给DBMS:1.把A的账户余额更新(UPDATE语句)为现有余额减去1万元;2.把B的账户余额更新(UPDATE语句)为现有余额加上1万元。此时这两条SQL语句就构成了一个事务。
假设在第一条SQL语句执行后,网络或计算机发生了故障,第二条SQL语句无法执行,那么会发生什么呢?A的账户余额虽然减少了1万日元,但是B的账户余额却没有相应地增加1万日元,这就导致了数据不一致。
为了防止出现这种问题,在SQL语言中设计了以下三条语句:1. BEGIN TRANSACTION(开启事务)语句,用于通知DBMS开启事务;2. COMMIT(提交事务)语句,用于通知DBMS提交事务;3. ROLL BACK(事务回滚)语句,用于在事务进行中发生问题时,把数据库中的数据恢复到事务开始前的状态。
TCP/IP 网络
实验 1:查看网卡的 MAC 地址
以太网使用了一种略显粗糙的方法连接LAN内的计算机(如图9.2所示)。以太网中的每台计算机都需要先确认一件事:在网线上有没有其他的计算机正在传输电信号,也就是说要先确保没有人在占用网络,然后才能发送自己想传输的电信号。谁先抢到了网线的使用权,谁就先发送。万一遇到了多台计算机同时都想发送电信号的情况,只需要让这些计算机等待一段长度随机的时间后再重新发送相同的电信号即可。这套机制叫作CSMA/CD(Career Sense Multiple Access with Collision Detection,带冲突检测的载波监听多路访问)。所谓载波监听(Career Sense) ,指的是这套机制会去监听(Sense)表示网络是否正在使用的电信号(Career) 。而多路复用(Multiple Access)指的是多个(Multiple)设备可以同时访问(Access)传输介质。带冲突检测(with Collision Detection)则表示这套机制会去检测(Detection)因同一时刻的传输而导致的电信号冲突(Collision)。在小规模的LAN中,像这样略显粗躁的CSMA/CD机制是可以正常运转的。因为CSMA/CD归根结底也只是一种适用于LAN的机制。
在以太网中,发送给一台计算机的电信号也可以被其他所有的计算机收到。一台计算机收到了电信号以后会先做判断,如果是发送给自己的则选择接收,反之则选择忽略。可以用被称作MAC(Media Access Control)地址的编号来指定电信号的接收者。在每一块网卡所带有的ROM(Read Only Memory,只读存储器)中,都预先烧录了一个唯一的MAC地址。
因为MAC地址是由制造厂商的编号和产品编号两部分组成的,所以世界上的每一个MAC地址都是独一无二的。
使用 ipconfig /all 命令查看 MAC 地址
实验 2:查看计算机的 IP 地址
在TCP/IP网络中,除了硬件上的MAC地址,还需要为每台计算机设定一个软件上的编号。这个编号就是众所周知的IP地址。通常把设定了IP地址的计算机称为“主 机”(Host) 。因为路由器也算是计算机的一种,所以它们也有IP地址。在TCP/IP网络中,传输的数据都会携带MAC地址和IP地址两个地址。
使用 ipconfig /all 命令查看 IP 地址
实验 3:了解 DHCP 服务器的作用
DHCP的全称是Dynamic Host Configuration Protocol(动态主机设置协议)。
DHCP服务器上记录着可以被分配到LAN内计算机的IP地址范围和子网掩码的值。作为DHCP客户端的计算机在启动时,就可以从中知道哪些IP地址还没有分配给其他计算机。
有一个叫作“默 认网关”的配置项。通常会把路由器的IP地址设置在这里。也就是说路由器就是从LAN通往互联网世界的入口(Gateway)。路由器的IP地址也可以从DHCP服务器获取。
实验 4:路由器是数据传输过程中的指路人
与LAN内的其他计算机一样,路由器也是连接在集线器上的。因为LAN内采用了CSMA/CD机制,所以所有发送出去的数据也都会发到路由器上。当从公司内的计算机向另一家公司的计算机发送数据时会发生什么呢?首先,一个不属于LAN内计算机的IP地址会被附加到数据的发送目的地字段上。这样的数据虽然会被LAN内的计算机所忽略,但是不会被路由器忽略。因为路由器的工作原理就是查看附加到数据上的IP地址中的网络地址部分,只要发现这个数据不是发送给LAN内计算机的,就把它发送到LAN外,即互联网的世界中。
分布在世界各地的LAN中的路由器相互交换着信息,互联网正是由于这种信息的交换才得以联通。这种信息被称作“路 由表”,用来记录应该把数据转发到哪里。在像互联网这样的网络中,传输路径错综复杂,而路由器就是站在各个岔路口的指路人(如 图9.6所示)。在一台路由器的路由表中,只会记录通往与之相邻的路由器的路径,而并不会记录世界范围内的所有传输路径。
路由表由5列构成。Network Destination、Netmask、Gateway、Interface这四列记录着数据发送的目的地和路由器的IP地址等信息。Metric这一列记录着路径的权重,这个值由某种算法决定,比如数据传输过程中经过的路由器的数量。如果遇到有多条候选路径都可以通往目的地的情况,路由器就会选择Metric值较小的那条路径。在路由表中还有如下的规则:如果数据的发送目的地就在本LAN中,则可以直接发送数据而无需经过路由器转发;反之如果在LAN外(或 发送目的地的IP地址不在路由表中),则需要经过路由器转发。
实验 5:查看路由器的路由过程
在命令提示符窗口中执行tracert命令后,就可以查看路由的过程了。
tracert www.google.com
9.7 实验 6:DNS 服务器可以把主机名解析成 IP 地址
在互联网中,难以记忆的IP地址使用起来很麻烦。于是人们就发明出了DNS服务器,这样只需要使用FQDN,DNS服务器就可以自动地把它解析为IP地址了(这 个过程叫作“域 名解析”)。DNS服务器通常被部署在各个LAN中,里面记录着FQDN和IP地址的对应关系表。世界范围内的DNS服务器是通过相互合作运转起来的。如果一台DNS服务器无法解析域名,它就会去询问其他的DNS服务器。这套流程是自动进行的,诸位并不会意识到。
计算机都有一个主机名,每个LAN也都有一个域名。举例来说,笔者所使用的计算机的主机名是ma50j(源于这台计算机的型号),所在的LAN的域名是yzw .co.jp。把主机名和域名组合起来所形成的ma50j.yze.co.jp,就是能够标识笔者这台计算机的一个世界范围内独一无二的名字,这个名字与IP地址的作用是等价的。通常把这种由主机名和域名组合起来形成的名字称作FQDN(Fully Qualified Domain Name,完整限定域名)。
在互联网中,难以记忆的IP地址使用起来很麻烦。于是人们就发明出了DNS服务器,这样只需要使用FQDN,DNS服务器就可以自动地把它解析为IP地址了(这 个过程叫作“域 名解析”)。DNS服务器通常被部署在各个LAN中,里面记录着FQDN和IP地址的对应关系表。世界范围内的DNS服务器是通过相互合作运转起来的。如果一台DNS服务器无法解析域名,它就会去询问其他的DNS服务器。这套流程是自动进行的。
实验 7:查看 IP 地址和 MAC 地址的对应关系
加密数据
什么是加密
文本数据可以由各种各样的字符构成。其中每个字符都被分配了一个数字,我们称之为“字 符编码”。定义了应该把哪个编码分配给哪个字符的字符编码体系叫作字符集。字符集分为ASCII字符集、JIS字符集、Shift-JIS字符集,EUC字符集、Unicode字符集等若干种。
错开字符编码的加密方式
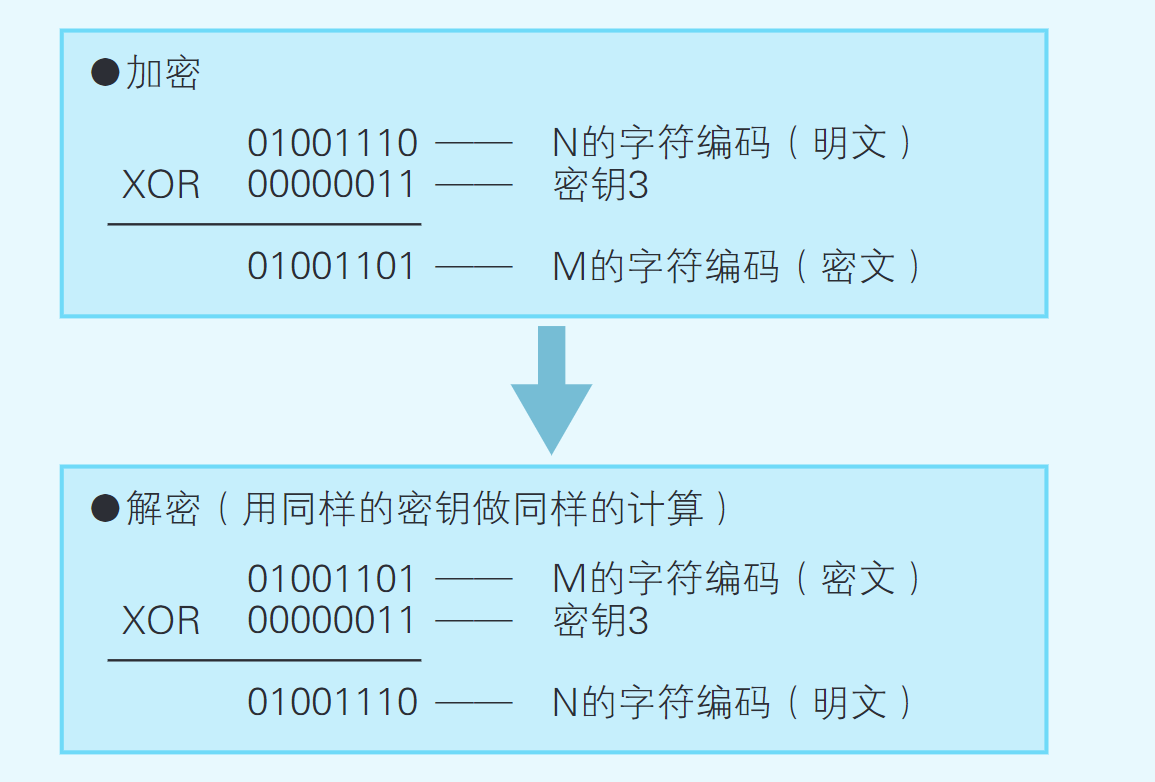
密钥越长,解密越困难
适用于互联网的公开密钥加密技术
对称密钥加密技
这种加密技术的特征是在加密和解密的过程中使用数值相同的密钥。因此,要使用这种技术,就必须事先把密钥的值作为只有发送者和接收者才知道的秘密保护好。
在公开密钥加密技术中,用于加密的密钥可以公开给全世界,因此称为“公 钥”,而用于解密的密钥是只有自己才知道的秘密,因此称为“私 钥”。
1、消息接收方准备好公钥和私钥
2、私钥接收方自己留存、公钥发布给消息发送方
3、消息发送方使用接收方公钥对消息进行加密
4、消息接收方用自己的私钥对消息解密
数字签名可以证明数据的发送者是谁
【文本数据的发送者】
(1)选取一段明文例:NIKKEI
(2)计算出明文内容的信息摘要例:(78+73+75+75+69+73)÷100的余数= 43
(3)用私钥对计算出的信息摘要进行加密例:43→66(字母B的编码)
(4)把步骤(3)得出的值附加到明文后面再发送给接收者例:NIKKEI B
【文本数据的接收者】
(1)用发送者的公钥对信息摘要进行解密例:B = 66→43
(2)计算出明文部分的信息摘要例:(78+73+75+75+69+73)÷100的余数= 43
(3)比较在步骤(1)和(2)中求得的值,二者相同则证明接收的信息有效
XML
XML 是标记语言
XML是eXtensible Markup Language的缩写,译为可扩展标记语言。
<html>是用于表示这是HTML文件的标签。同样,其他标签也分别被赋予了意义.
通常把通过添加标签为数据赋予意义的行为称为“标 记”。为这种给数据赋予意义的行为定义规则的语言就是“标 记语言”。HTML是用于编写网页的标记语言,更简单地说法就是HTML决定了可用于编写网页的标签。
XML 是可扩展的语言
在iuhist.xml中就有<publisherName>和<processorArchitecture>等标签,而且很有可能这两个标签表示的就是“发行者的名字”和“处理器的架构”
那么是XML规定了这些标签吗?答案是否定的。XML本身并不会限定标签的种类,反倒是允许XML的使用者随心所欲地创建标签。也就是说,在“<”和“>”中的单词可以是任意的。这就是所谓的“可扩展”。在HTML中,我们只能使用由HTML定义出的那若干种标签,因此HTML是固定的标记语言。
XML 是元语言
通过定义要使用的标签种类,就可以创造出一门新的标记语言。通常把这种用于创造语言的语言称作“元 语言”。例如,我们可以使用<dog>和<cat>等标签,创造一种属于自己的标记语言——宠物语言。
XML的数据是纯文本格式的,也就是说只包含字符。通常把遵循了XML的约束编写出的文档称为“XML文档”;把保存着XML文档的文件称为“XML文件”。可以使用记事本等文本编辑器编写XML文件。
XML 可以为信息赋予意义
如果网站只提供了HTML,那么这个程序几乎不可能完成。因为HTML中规定的各种标签只能用来指定信息的呈现样式,而不能表示信息的含义。
xML 是通用的数据交换格式
如果某家厂商的某个应用程序把数据保存到了XML文件中,那么其他厂商的另一个应用程序就应该可以通过加载这个XML文件来使用数据。
可以为 XML 标签设定命名空间
在XML文档中,通过把“xmlns=”命名空间的名字””作为标签的一个属性记述,就可以为标签设定命名空间。xmlns即XML NameSpace(命名空间)的缩写。通常用全世界唯一的标识符作为命名空间的名称。

