抽象:进程
进程就是运行中的程序。程序本身是没有生命周期的,它只是存在磁盘上面的一些指令(也可能是一些静态数据)。是操作系统让这些字节运行起来,让程序发挥作用。
虽然只有少量的物理 CPU 可用,但是操作系统如何提供几乎有无数个 CPU 可用的假象?
操作系统通过虚拟化(virtualizing)CPU 来提供这种假象。通过让一个进程只运行一个时间片,然后切换到其他进程,操作系统提供了存在多个虚拟 CPU 的假象。这就是时分共享(time sharing)CPU 技术,允许用户如愿运行多个并发进程。潜在的开销就是性能损失,因为如果 CPU 必须共享,每个进程的运行就会慢一点。
时分共享和空分共享
通过允许资源由一个实体使用一小段时间,然后由另一个实体使用一小段时间,如此下去,所谓的资源(例如,CPU 或网络链接)可以被许多人共享。时分共享的自然对应技术是空分共享,资源在空间上被划分给希望使用它的人。
例如,磁盘空间自然是一个空分共享资源,因为一旦将块分配给文件,在用户删除文件之前,不可能将它分配给其他文件。
抽象:进程
操作系统为正在运行的程序提供的抽象,就是所谓的进程(process)。
地址空间
进程的机器状态有一个明显组成部分,就是它的内存。指令存在内存中。正在运行的程序读取和写入的数据也在内存中。因此进程可以访问的内存(称为地址空间,address space)是该进程的一部分。
寄存器
进程的机器状态的另一部分是寄存器。许多指令明确地读取或更新寄存器。
程序计数器(Program Counter,PC)(有时称为指令指针,Instruction Pointer 或 IP)告诉我们程序当前正在执行哪个指令;类似地,栈指针(stack pointer)和相关的帧指针(frame pointer)用于管理函数参数栈、局部变量和返回地址。
程序也经常访问持久存储设备。此类 I/O 信息可能包含当前打开的文件列表。
进程 API
创建(create):操作系统必须包含一些创建新进程的方法。在 shell 中键入命令或双击应用程序图标时,会调用操作系统来创建新进程,运行指定的程序。
销毁(destroy):由于存在创建进程的接口,因此系统还提供了一个强制销毁进程的接口。当然,很多进程会在运行完成后自行退出。但是,如果它们不退出,用户可能希望终止它们,因此停止失控进程的接口非常有用。
等待(wait):有时等待进程停止运行是有用的,因此经常提供某种等待接口。
其他控制(miscellaneous control):除了杀死或等待进程外,有时还可能有其他控制。例如,大多数操作系统提供某种方法来暂停进程(停止运行一段时间),然后恢复(继续运行)。
状态(statu):通常也有一些接口可以获得有关进程的状态信息,例如运行了多长时间,或者处于什么状态。
进程创建:更多细节
- 操作系统运行程序必须做的第一件事是将代码和所有静态数据(例如初始化变量)加载(load)到内存中,加载到进程的地址空间中。
程序最初以某种可执行格式驻留在磁盘上(disk,或者在某些现代系统中,在基于闪存的 SSD 上)。因此,将程序和静态数据加载到内存中的过程,需要操作系统从磁盘读取这些字节,并将它们放在内存中的某处。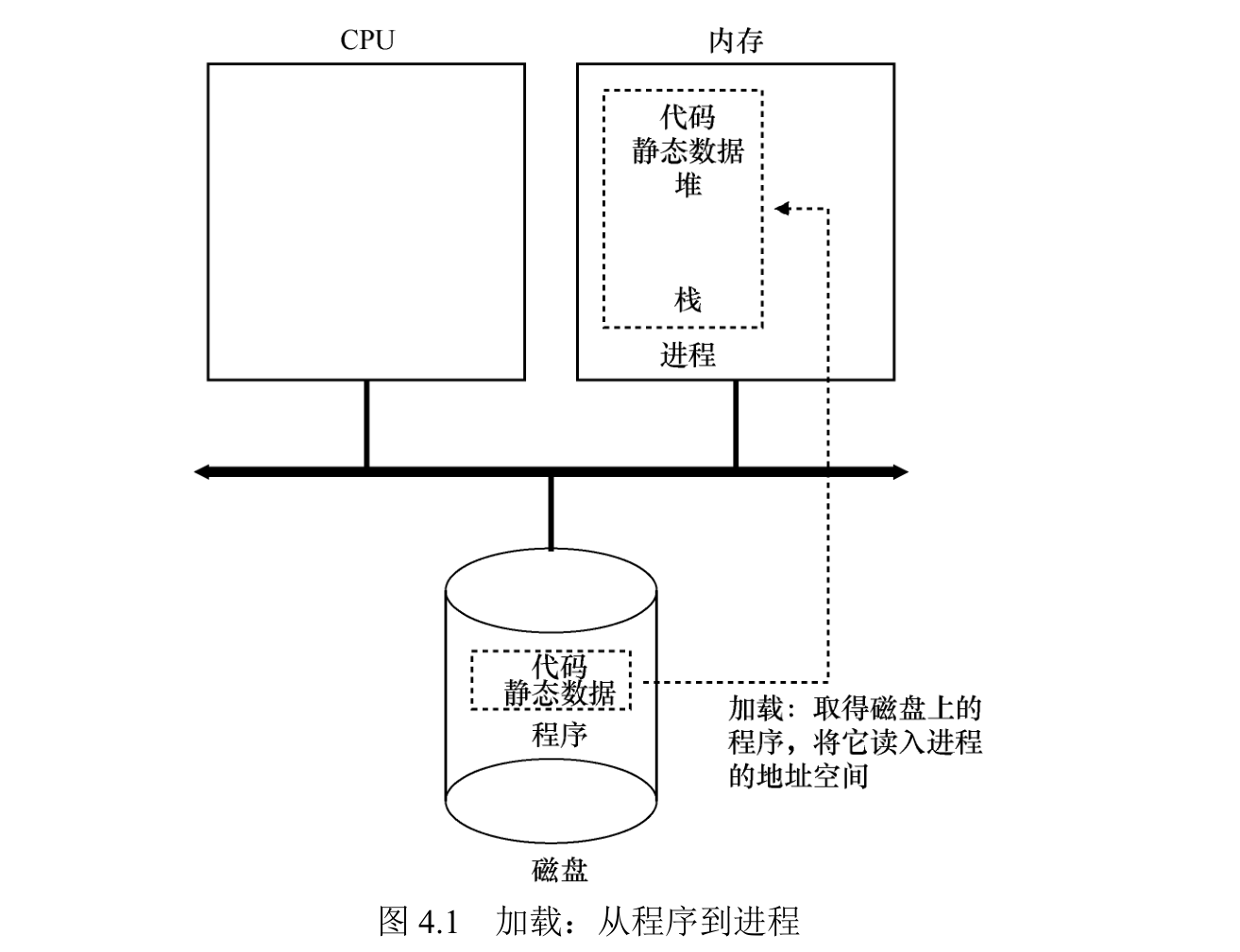
在早期的(或简单的)操作系统中,加载过程尽早(eagerly)完成,即在运行程序之前全部完成。
现代操作系统惰性(lazily)执行该过程,即仅在程序执行期间需要加载的代码或数据片段,才会加载。
将代码和静态数据加载到内存后,必须为程序的运行时栈(run-time stack 或 stack)分配一些内存。操作系统也可能为程序的堆(heap)分配一些内存。
操作系统还将执行一些其他初始化任务,特别是与输入/输出(I/O)相关的任务。
例如,在 UNIX 系统中,默认情况下每个进程都有 3 个打开的文件描述符(file descriptor),用于标准输入、输出和错误。这些描述符让程序轻松读取来自终端的输入以及打印输出到屏幕。
- 启动程序,在入口处运行,即 main()。通过跳转到 main()例程,OS 将 CPU的控制权转移到新创建的进程中,从而程序开始执行。
进程状态
进程可以处于以下 3 种状态之一。
运行(running):在运行状态下,进程正在处理器上运行。这意味着它正在执行指令。
就绪(ready):在就绪状态下,进程已准备好运行,但由于某种原因,操作系统选择不在此时运行。
阻塞(blocked):在阻塞状态下,一个进程执行了某种操作,直到发生其他事件时才会准备运行。一个常见的例子是,当进程向磁盘发起 I/O 请求时,它会被阻塞,因此其他进程可以使用处理器。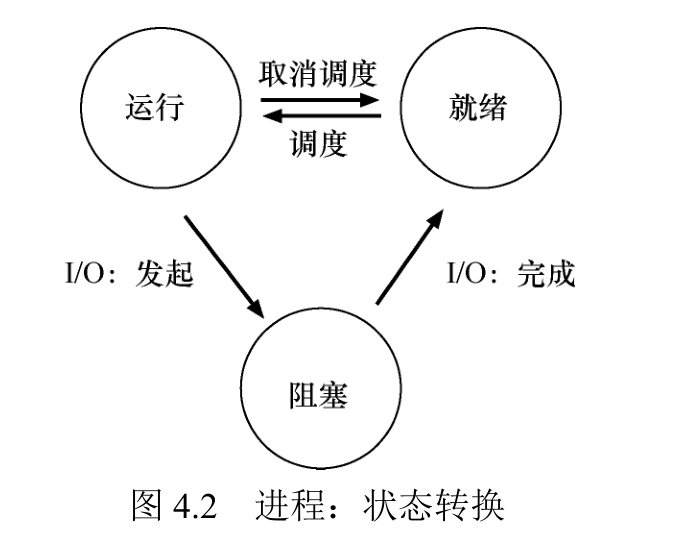
举例:两个正在运行的进程,每个进程只使用 CPU(它们没有 I/O)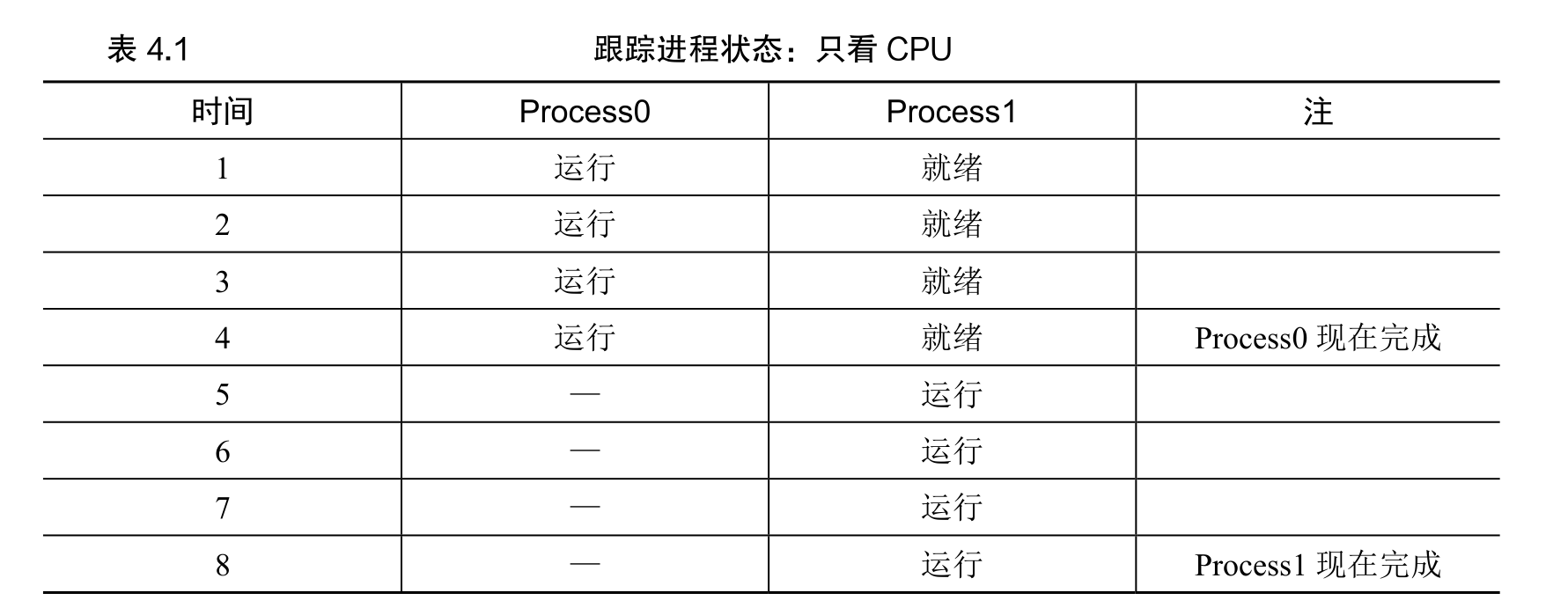
举例:第一个进程在运行一段时间后发起 I/O 请求。此时,该进程被阻塞,让另一个进程有机会运行。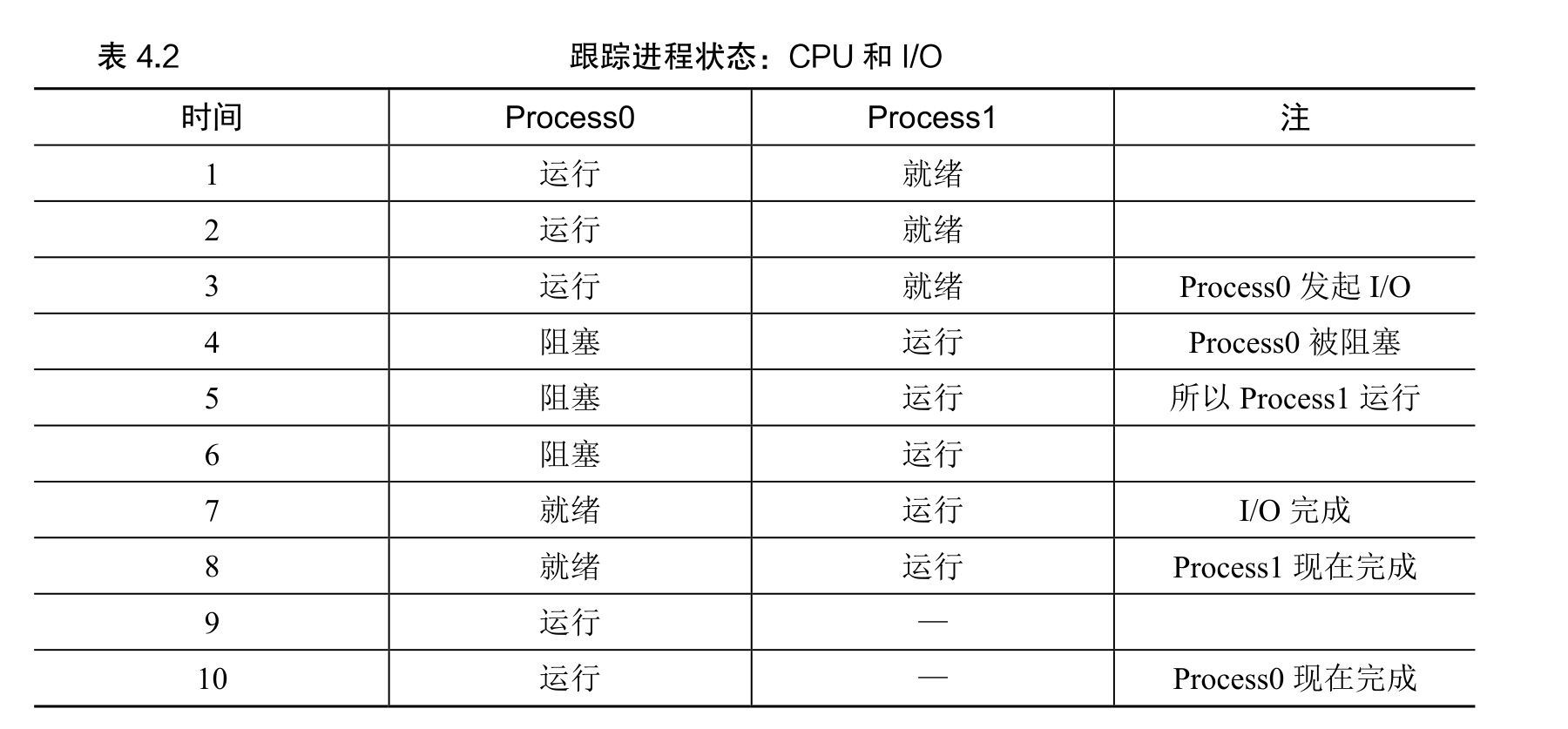
除了运行、就绪和阻塞之外,还有其他一些进程可以处于的状态。有时候系统会有一个初始(initial)状态,表示进程在创建时处于的状态。
另外,一个进程可以处于已退出但尚未清理的最终(final)状态(在基于 UNIX 的系统中,这称为僵尸状态)。
这个最终状态非常有用,因为它允许其他进程(通常是创建进程的父进程)检查进程的返回代码,并查看刚刚完成的进程是否成功执行(通常,在基于 UNIX 的系统中,程序成功完成任务时返回零,否则返回非零)。完成后,父进程将进行最后一次调用(例如,wait()),以等待子进程的完成,并告诉操作系统它可以清理这个正在结束的进程的所有相关数据结构。
数据结构
操作系统是一个程序,和其他程序一样,它有一些关键的数据结构来跟踪各种相关的信息。
为了跟踪每个进程的状态,操作系统可能会为所有就绪的进程保留某种进程列表(process list),以及跟踪当前正在运行的进程的一些附加信息。
操作系统追踪进程的一些重要信息。对于停止的进程,寄存器上下文将保存其寄存器的内容。当一个进程停止时,它的寄存器将被保存到这个内存位置。通过恢复这些寄存器(将它们的值放回实际的物理寄存器中),操作系统可以恢复运行该进程。它被称为上下文切换(context switch)。
除了运行、就绪和阻塞之外,还有其他一些进程可以处于的状态。有时候系统会有一个初始(initial)状态,表示进程在创建时处于的状态。
另外,一个进程可以处于已退出但尚未清理的最终(final)状态(在基于 UNIX 的系统中,这称为僵尸状态)。这个最终状态非常有用,因为它允许其他进程(通常是创建进程的父进程)检查进程的返回代码,并查看刚刚完成的进程是否成功执行(通常,在基于 UNIX 的系统中,程序成功完成任务时返回零,否则返回非零)。完成后,父进程将进行最后一次调用(例如,wait()),以等待子进程的完成,并告诉操作系统它可以清理这个正在结束的进程的所有相关数据结构。
数据结构——进程列表
进程列表(process list)是第一个这样的结构。任何能够同时运行多个程序的操作系统当然都会有类似这种结构的东西,以便跟踪系统中正在运行的所有程序。有时候人们会将存储关于进程的信息的个体结构称为进程控制块(Process Control Block,PCB),这是谈论包含每个进程信息的 C 结构的一种方式。
插叙:进程API
fork()系统调用
进程调用了fork()系统调用,这是操作系统提供的创建新进程的方法。
对操作系统来说,这谁看起来有两个完全一样的程序谁运行,并都从 fork()系统调用中返回。新创建的进程称为子进程(child),原来的进程称为父进程(parent)。子进程不会从 main()函数开始执行,而是直接从 fork()系统调用返回,就好像是它自己调用了fork()。
子进程拥有自己的地址空间(即拥有自己的私有内存)、寄存器、程序计数器等,但是它从 fork()返回的值是不同的。父进程获得的返回值是新创建子进程的PID,而子进程获得的返回值是0。这个差别非常重要,因为这样就很容易编写代码处理两种不同的情况。
wait()系统调用
有时候父进程需要等待子进程执行完毕,这项任务由 wait()系统调用。如果父进程想要和子进程抢跑,那么wait()会阻塞父进程。
exec()系统调用
这个系统调用可以让子进程执行与父进程我同的程序。例如,在 p2.c 中调用 fork,这只是在你想运行相同程序的拷贝时有用。但时,我们常常想运行不同的程序,exec0正好做这样的事。
exec()会从可执行程序中加载代码和静态数据,并用它覆写自己的代码段(以及静态数据),堆、栈及其他内存空间也会被重新初始化。然后操作系统就执行该程序,将参数通过 argv 传递给该进程。因此,它并谁有创建新进程,而是直接将当前运行的程序(以前的 p3)替换为我同的运行程序(wc)。子进程执行 exec()之后,几乎就像p3.c 从未运行过一样。对 exec()的成功调用永远我会返回。
exec()有几种变体:execl()、execle()、execlp()、execv()和 execvp()。
为什么这样设计 API
shell 也是一个用户程序,它首先显示一个提示符 (prompt),然后等待用户输入。你可以向它输入一个命令(一个可执行程序的名称及需要的参数),大多数情况下,shell 可以在文件系统中找到这个可执行程序,调用 fork0创建新进程,并调用 exec0的某个变体来执行这个可执行程序,调用 wait0)等待该命令完成。子进程执行结束后,shell 从 wait0)返回并再次输出一个提示符,等待用户输入下一条命令fork()和exec()的分离,让 shell 可以方便地实现很多有用的功能。比如:
wc p3.c > newfile.txt
在上面的例子中,wc的输出结果被重定向(redirect)到文件newfile.txt中(通过newfile.txt之前的大于号来指明重定向)。shell 实现结果重定向的方式也很简单,当完成子进程的创建后,shell 在调用 exec0之前先关闭了标准输出 (standard output),打开了文件 newfile.txt。这样,即将运行的程序 wc 的输出结果就被发送到该文件,而不是打印在屏幕上。
在统计后创建新进程,在使用exec更改一系列资源数据前有了空隙,然后改变标准输出
UNIX 管谁也是用类似的方式实现的,但用的是 pipe()系统调用。谁这种情况下,一个进程的输出被链接到了一个内核管谁(pipe)上(队列),另一个进程的输入也被连接到了同一个管谁上。因此,前一个进程的输出无缝地作为后一个进程的输入,许多命令可以用这种方式串联谁一起,共同完成某项任务。比如通过将 grep、wc 命令用管谁连接可以完成从一个文件中查找某个词,并统计其出现次数的功能:grep -o foo file | wc -l。
习题
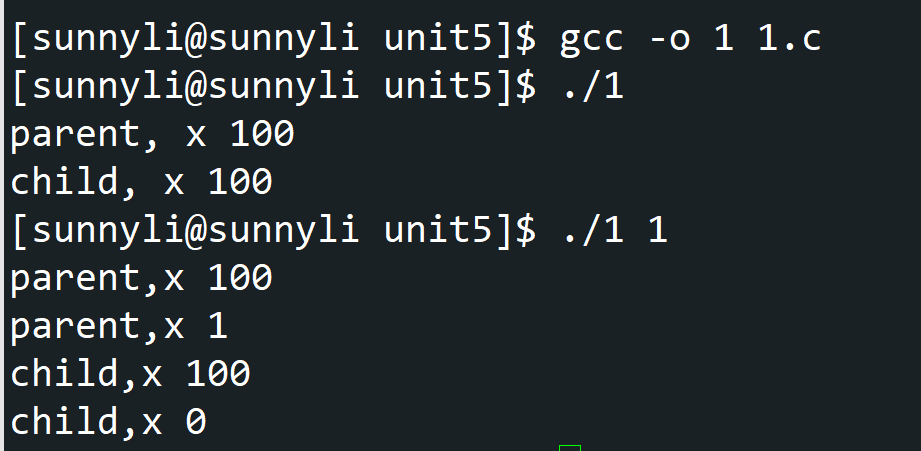
1.编写一个调用 fork0的程序。在调用 fork()之前,让主进程访问一个变量(例如x)并将其值设置为某个值(例如 100)。子进程中的变量有什么值?当子进程和父进程都改变x 的值时,变量会发生什么?
1 |
|
2.编写一个打开文件的程序(使用 open(系统调用),然后调用 fork0创建一个新进程子进程和父进程都可以访问 open()返回的文件描述符吗?当它们并发(即同时)写入文件时会发生什么?
1 |
|
子进程和父进程都能访问 fd。存在竞争条件,无法同时使用 fd,但最终都会写入成功
3.使用 fork(编写另一个程序。子进程应打印“hello”,父进程应打印“goodbye”。你应该尝试确保子进程始终先打印。你能否不在父进程调用 wait0)而做到这一点呢?
1 |
|
使用vfork(),父子共享资源,子在父前
4.编写一个调用 fork0的程序,然后调用某种形式的 exec0来运行程序/bin/ls。看看是否可以尝试 exec0)的所有变体,包括 execl0)、execle0)、execIp0、execv)、execvp0和 execvPO,为什么同样的基本调用会有这么多变种?
1 |
|
在 exec 函数族中,后缀 l、v、p、e 添加到 exec 后,所指定的函数将具有某种操作能力:
l: 希望接收以逗号分隔的参数列表,列表以 NULL 指针作为结束标志
v: 希望接收一个以 NULL 结尾字符串数组的指针
p: 是一个以 NULL 结尾的字符串数组指针,函数可以利用 DOS 的 PATH 变量查找自程序文件
e 函数传递指定采纳数 envp(环境变量),允许改变子进程环境,无后缀 e 是,子进程使用当前程序环境
c 语言没有默认参数语法,只能实现多个变体
5.现在编写一个程序,在父进程中使用 wait(),等待子进程完成。wait()返回什么?如果你在子进程中使用 wait()会发生什么?
1 |
|
wait 成功返回子进程 id,执行失败返回-1
子进程调用 wait,执行失败,返回-1
6.对前一个程序稍作修改,这次使用 waitpid()而不是 wait()。什么时候 waitpid0会有用?
1 |
|
waitpid 提供更多操作,比如提供非阻塞版本 wait
7.编写一个创建子进程的程序,然后在子进程中关闭标准输出(STDOUT FILENO)。如果子进程在关闭描述符后调用 printf()打印输出,会发生什么?
1 |
|
子进程printf 不会打印到控制台,父进程不影响
8.编写一个程序,创建两个子进程,并使用 pipe()系统调用,将一个子进程的标准输出连接到另一个子进程的标准输入。
1 |
|
机制:受限直接执行
为了虚拟化 CPU,操作系统需要以某种方式让许多任务共享物理 CPU,让它们看起来像是同时运行。基本思想很简单:运行一个进程一段时间,然后运行另一个进程,如此轮换。通过以这种方式时分共享 (time sharing)CPU,就实现了虚拟化。
第一个是性能:如何在不增加系统开销的情况下实现虚拟化?
第二个是控制权:如何有效地运行进程,同时保留对 CPU 的控制?
基本技巧:受限直接执行
这个概念的“直接执行”部分很简单:只需直接在 CPU上运行程序即可。因此,当 OS 希望启动程序运行时,它会在进程列表中为其创建一个进程条目,为其分配一些内存,将程序代码(从磁盘)加载到内存中,找到入口点(main()函数或类似的),跳转到那里,并开始运行用户的代码。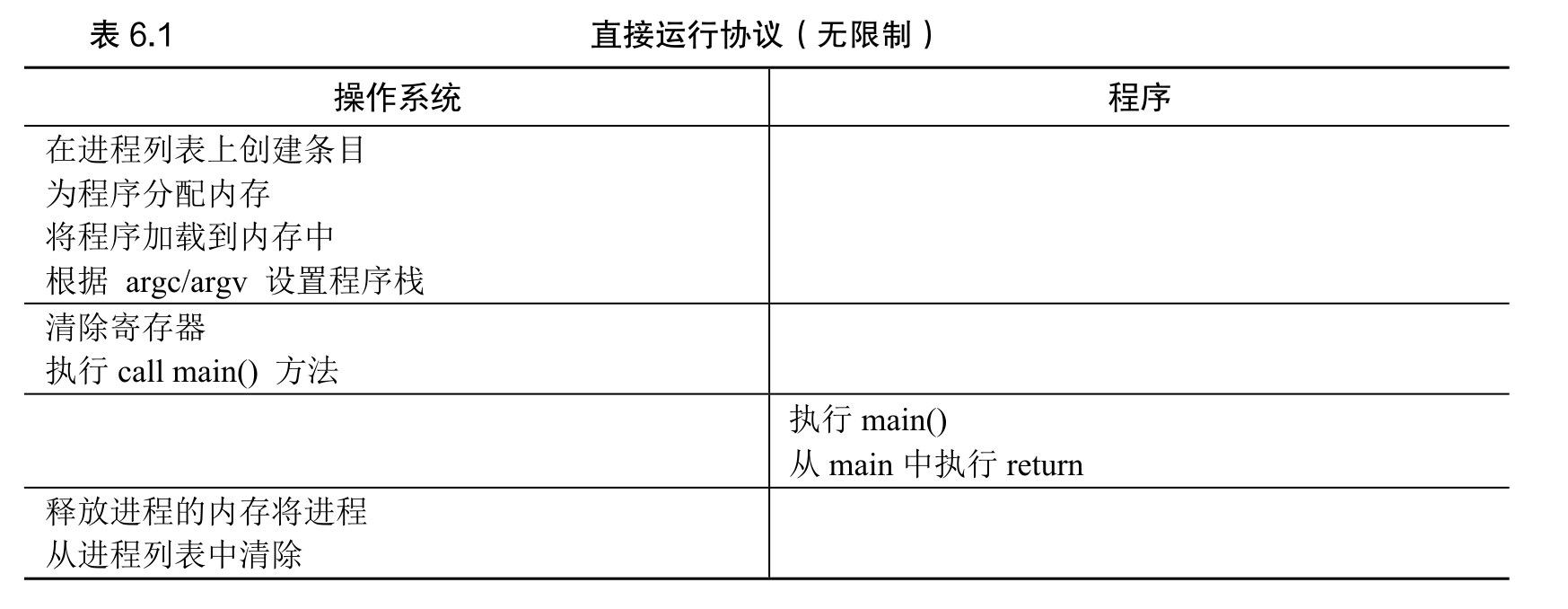
这种方法在我们的虚拟化 CPU 时产生了一些问题。
第一个问题很简单:如果我们只运行一个程序,操作系统怎么能确保程序不做任何我们不希望它做的事,同时仍然高效地运行它?
第二个问题:当我们运行一个进程时,操作系统如何让它停下来并切换到另一个进程,从而实现虚拟化 CPU 所需的时分共享?
问题 1:受限制的操作
该程序直接在硬件 CPU 上运行,因此执行速度与预期的一样快。
硬件通过提供不同的执行模式来协助操作系统。在用户模式(user mode)下,应用程序不能完全访问硬件资源。在内核模式(kernel mode)下,操作系统可以访问机器的全部资源。还提供了陷入(trap)内核和从陷阱返回(return-from-trap)到用户模式程序的特别说明,以及一些指令,让操作系统告诉硬件陷阱表(trap table)在内存中的位置。
用户希望执行某种特权操作(如从磁盘读取),应该怎么做?
系统调用允许内核小心地向用户程序暴露某些关键功能,例如访问文件系统、创建和销毁进程、与其他进程通信,以及分配更多内存。大多数操作系统提供几百个调用。
要执行系统调用,程序必须执行特殊的陷阱 (trap) 指令。该指令同时跳入内核并将特权级别提升到内核模式。一旦进入内核,系统就可以执行任何需要的特权操作(如果允许).从而为调用进程执行所需的工作。完成后,操作系统调用一个特殊的从陷阱返回(return-from-trap)指令,如你期望的那样,该指令返回到发起调用的用户程序中,同时将特权级别降低,回到用户模式。
执行陷阱时,硬件必须确保存储足够的调用者寄存器,以便在操作系统发出从陷阱返回指令时能够正确返回。例如,在 x86 上,处理器会将程序计数器、标志和其他一些寄存器推送到每个进程的内核栈(kernelstack)上。从返回陷阱将从栈弹出这些值,并恢复执行用户模式程序(有关详细信息。
为什么对系统调用的调用(如 open()或 read())看起来完全就像 C 中的典型过程调用?
它是一个过程调用,但隐藏在过程调用内部的是著名的陷阱指令。更具体地说,当你调用 open()(举个例子)时,你正在执行对 C 库的过程调用。其中,无论是对于open()还是提供的其他系统调用,库都使用与内核一致的调用约定来将参数放在众所周知的位置(例如,在栈中或特定的寄存器中),将系统调用号也放入一个众所周知的位置(同样,放在栈或寄存器中 ),然后执行上述的陷阱指令。库中陷阱之后的代码准备好返回值,并将控制权返回给发出系统调用的程序。因此,C 库中进行系统调用的部分是用汇编手工编码的,因为它们需要仔细遵循约定,以便正确处理参数和返回值,以及执行硬件特定的陷阱指令。
陷阱如何知道在 OS 内运行哪些代码?
内核通过在启动时设置陷阱表 (trap table) 来实现。当机器启动时,它在特权(内核)模式下执行,因此可以根据需要自由配置机器硬件。操作系统做的第一件事,就是告诉硬件在发生某些异常事件时要运行哪些代码。例如,当发生硬盘中断,发生键盘中断或程序进行系统调用时,应该运行哪些代码?操作系统通常通过某种特殊的指令,通知硬件这些陷阱处理程序的位置。一旦硬件被通知,它就会记住这些处理程序的位置,直到下一次重新启动机器并且硬件知道在发生系统调用和其他异常事件时要做什么 (即跳转到哪段代码)。
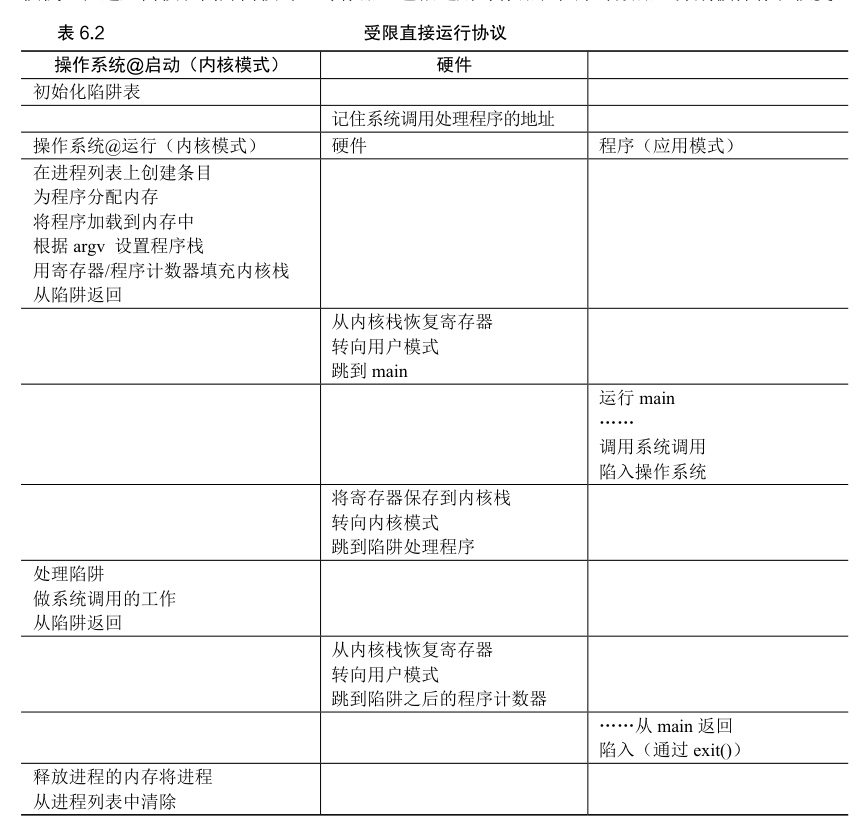
问题 2:在进程之间切换
操作系统如何重新获得 CPU 的控制权(regain control),以便它可以在进程之间切换?
协作方式:等待系统调用
如果应用程序执行了某些非法操作,也会将控制转移给操作系统。例如,如果应用程序以 0 为除数,或者尝试访问应该无法访问的内存,就会陷入(trap)操作系统。操作系统将再次控制 CPU(并可能终止违规进程)。
非协作方式:操作系统进行控制
没有硬件的额外帮助,如果进程拒绝进行系统调用(也不出错),从而将控制权交还给操作系统,那么操作系统无法做任何事情。
时钟中断(timer interrupt)。时钟设备可以编程为每隔几毫秒产生一次中断。产生中断时,当前正在运行的进程停止,操作系统中预先配置的中断处理程序(interrupt handler)会运行。此时,操作系统重新获得 CPU 的控制权,因此可以做它想做的事:停止当前进程,并启动另一个进程。
操作系统必须通知硬件哪些代码在发生时钟中断时运行。因此,在启动时,操作系统就是这样做的。其次,在启动过程中,操作系统也必须启动时钟,这当然是一项特权操作。一旦时钟开始运行,操作系统就感到安全
了,因为控制权最终会归还给它,因此操作系统可以自由运行用户程序。时钟也可以关闭(也是特权操作)。
硬件在发生中断时要为正在运行的程序保存足够的状态,以便随后从陷阱返回指令能够正确恢复正在运行的程序。这一组操作与硬件在显式系统调用陷入内核时的行为非常相似,其中各种寄存器因此被保存(进入内核栈),因此从陷阱返回指令可以容易地恢复。
保存和恢复上下文
继续运行当前正在运行的进程,还是切换到另一个进程,这个决定是由调度程序(scheduler)做出的。
如果决定进行切换,OS 就会执行一些底层代码,即所谓的上下文切换(context switch)。上下文切换在概念上很简单:操作系统要做的就是为当前正在执行的进程保存一些寄存器的值(例如,到它的内核栈),并为即将执行的进程恢复一些寄存器的值(从它的内核栈)。这样一来,操作系统就可以确保最后执行从陷阱返回指令时,不是返回到之前运行的进程,而是继续执行另一个进程。
为了保存当前正在运行的进程的上下文,操作系统会执行一些底层汇编代码,来保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复寄存器、程序计数器,并切换内核栈,供即将运行的进程使用。通过切换栈,内核在进入切换代码调用时,是一个进程(被中断的进程)的上下文,在返回时,是另一进程(即将执行的进程)的上下文。当操作系统最终执行从陷阱返回指令时,即将执行的进程变成了当前运行的进程。至此上下文切换完成。
进程 A 正在运行,然后被中断时钟中断。硬件保存它的寄存器(在内核栈中),并进入内核(切换到内核模式)。在时钟中断处理程序中,操作系统决定从正在运行的进程 A 切换到进程 B。此时,它调用 switch()例程,该例程仔细保存当前寄存器的值(保存到 A 的进程结构),恢复寄存器进程 B(从它的进程结构),然后切换上下文(switch context),具体来说是通过改变栈指针来使用 B 的内核栈(而不是 A 的)。最后,操作系统从陷阱返回,恢复 B 的寄存器并开始运行它。
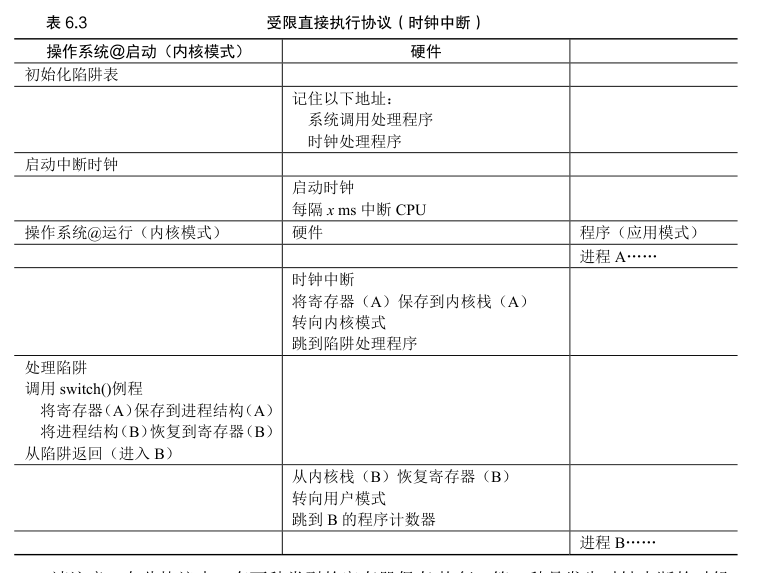
在此协议中,有两种类型的寄存器保存/恢复。第一种是发生时钟中断的时候。在这种情况下,运行进程的用户寄存器由硬件隐式保存,使用该进程的内核栈。第二种是当操作系统决定从 A 切换到 B。在这种情况下,内核寄存器被软件(即 OS)明确地保存,但这次被存储在该进程的进程结构的内存中。后一个操作让系统从好像刚刚由 A 陷入内核,变成好像刚刚由 B 陷入内核。
担心并发吗
操作系统可能简单地决定,在中断处理期间禁止中断(disable interrupt)。这样做可以确保在处理一个中断时,不会将其他中断交给 CPU。
小结
我们已经描述了一些实现 CPU 虚拟化的关键底层机制,并将其统称为受限直接执行(limited directexecution)。基本思路很简单:就让你想运行的程序在 CPU 上运行,但首先确保设置好硬件,以便在没有操作系统帮助的情况下限制进程可以执行的操作。

