进程调度:介绍
调度指标
周转时间(turnaround time)。任务的周转时间定义为任务完成时间减去任务到达系统的时间。
先进先出(FIFO)
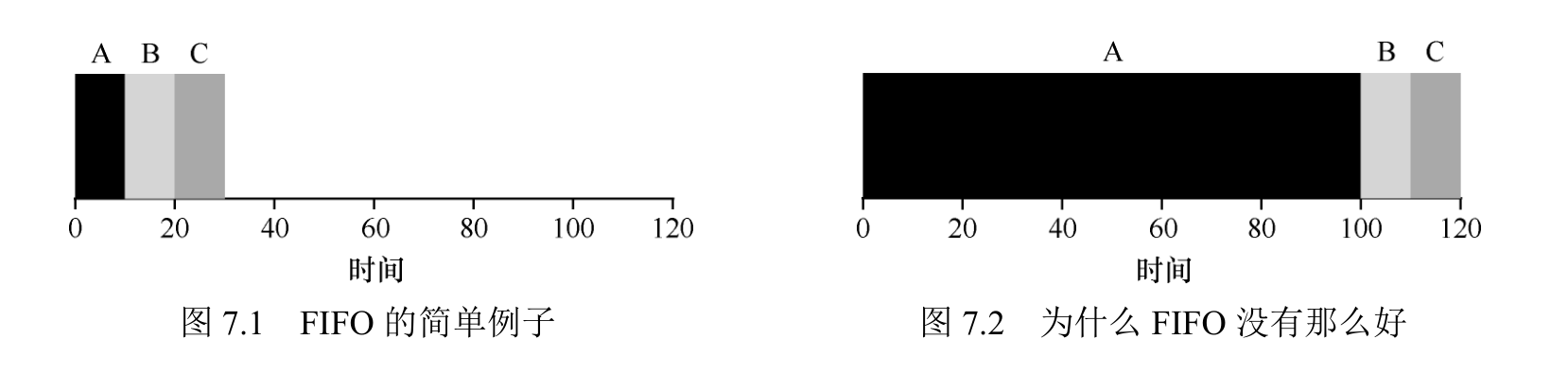
3 个工作 A、B 和 C 在大致相同的时间(T 到达时间 = 0)到达系统。因为 FIFO 必须将某个工作放在前面,所以我们假设当它们都同时到达时,A 比 B 早一点点,然后 B 比 C 早到达一点点。假设每个工作运行 10s。这些工作的平均周转时间(average turnaround time)是多少?
A 在 10s 时完成,B 在 20s 时完成,C 在 30s 时完成。因此,这3个任务的平均周转时间就是(10 + 20 + 30)/ 3 = 20。
假设 3 个任务(A、B 和 C),但这次 A 运行100s,而 B 和 C 运行 10s。
A 先运行 100s,B 或 C 才有机会运行。因此,系统的平均周转时间是比
较高的:令人不快的 110s((100 + 110 + 120)/ 3 = 110)。
最短任务优先(SJF)
先运行最短的任务,然后是次短的任务,如此下去。
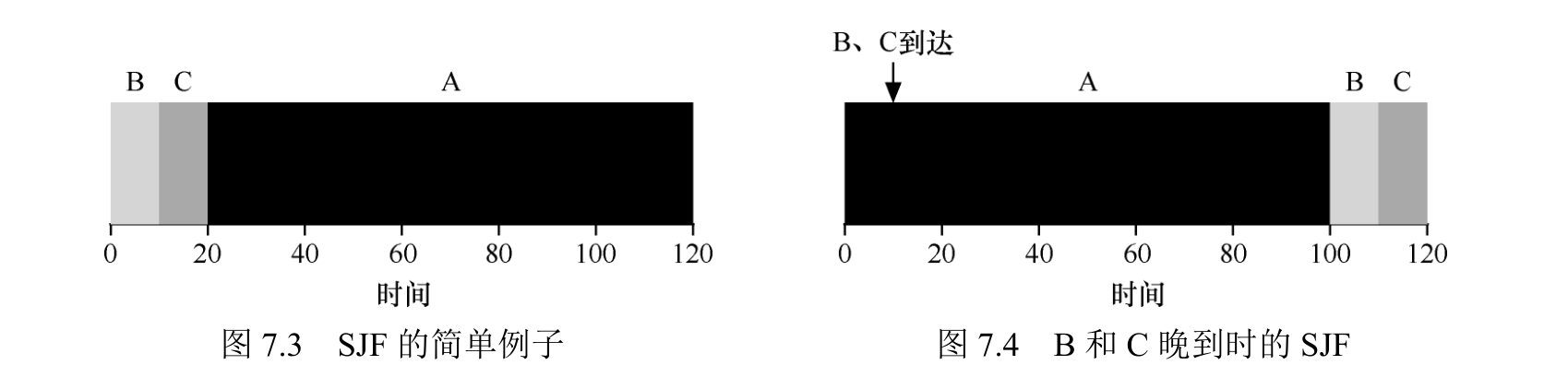
我们用上面的例子,SJF 调度策略更好。仅通过在 A 之前运行B和C,SJF 将平均周转时间从 110s 降低到 50s ((10+20 +120)/3=50)。
考虑到所有工作
假设A在t = 0时到达,且需要运行 100s。而 B 和 C 在 t = 10 到达,且各需要运行 10s。用纯 SJF,我们可以得到如图 7.4 所示的调度。
最短完成时间优先(STCF)
为了解决这个问题,需要调度程序本身的一些机制。当B和C到达时,调度程序当然可以做其他事情:它可以抢占 (preempt) 工作 A,并决定运行另一个工作,或许稍后继续工作 A。根据我们的定义,SJF 是一种非抢占式(non-preemptive) 调度程序,因此存在上述问题。
向 SJF 添加抢占,称为最短完成时间优先(Shortest Time-to-Completion First,STCF)或抢占式最短作业优先(Preemptive Shortest JobFirst ,PSJF)调度程序。每当新工作进入系统时,它就会确定剩余工作和新工作中,谁的剩余时间最少,然后调度该工作。

度量指标:响应时间
如果我们知道任务长度,而且任务只使用 CPU,而我们唯一的衡量是周转时间,STCF 将是一个很好的策略。事实上,对于许多早期批处理系统,这些类型的调度算法有一定的意义。然而,引入分时系统改变了这一切。现在,用户将会坐在终端前面,同时也要求系统的交互性好。 因此,一个新的度量标准诞生了:响应时间(response time)。
响应时间定义为从任务到达系统到首次运行的时间。更正式的定义是:
T 响应时间= T 首次运行−T 到达时间
轮转(引入响应时间)
RR调度基本思想很简单:RR 在一个时间片(time slice,有时称为调度量子,(schedulingquantum)内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直到结束。
它反复执行,直到所有任务完成。因此,RR 有时被称为时间切片 (time-slicing)请注意,时间片长度必须是时钟中断周期的倍数。因此,如果时钟中断是每 10ms 中断一次则时间片可以是 10ms、20ms 或 10ms 的任何其他倍数。
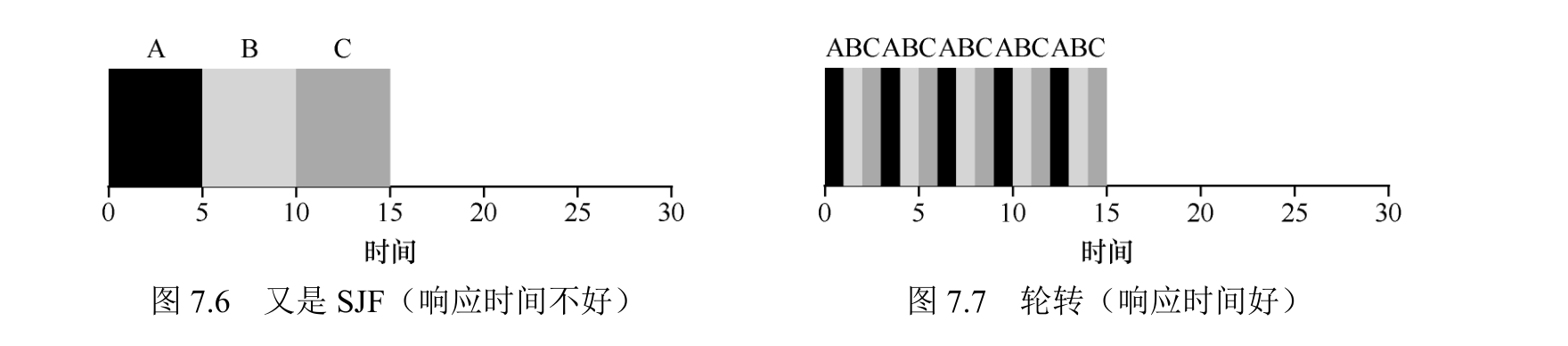
RR 的平均响应时间是:(0 + 1 + 2)/3 = 1; SJF 算法平均响应时间是:(0 + 5 + 10)/ 3 = 5。
时间片太短是有问题的:突然上下文切换的成本将影响整体性能。
当系统某些操作有固定成本时,通常会使用摊销技术(amortization)。通过减少成本的频度(即执行较少次的操作),系统的总成本就会降低。例如,如果时间片设置为 10ms,并且上下文切换时间为 1ms,那么浪费大约 10%的时间用于上下文切换。如果要摊销这个成本,可以把时间片增加到 100ms。在这种情况下,不到 1%的时间用于上下文切换,因此时间片带来的成本就被摊销了。
上下文切换的成本不仅仅来自保存和恢复少量寄存器的操作系统操作。程序运行时,它们在 CPU 高要缓存、TLB、分支预测器和其他片上硬件中建立了大量的状态。切换到另一个工作会导致此状态被刷新,且与当前运行的作业相关的新状态被引入。
如果你愿意不公平,你可以运行较短的工作直到完成,但是要以响应时间为代价。如果你重视公平性,则响应时间会较短,但会以周转时间为代价。这种权衡在系统中很常见。
第一种类型(SJF、STCF)优化周转时间,但对响应时间不利。第二种类型(RR)优化响应时间,但对周转时间不利。
结合 I/O
调度程序显然要在工作发起 I/O 请求时做出决定,因为当前正在运行的作业在 I/O 期间不会使用 CPU,它被阻塞等待 I/O 完成。如果将 I/O 发送到硬盘驱动器,则进程可能会被阻塞几毫秒或更长时间,具体取决于驱动器当前的 I/O 负载。因此,这时调度程序应该在 CPU上安排另一项工作。
调度程序还必须在 I/O 完成时做出决定。发生这种情况时,会产生中断,操作系统运行并将发出 I/O 的进程从阻塞状态移回就绪状态。当然,它甚至可以决定在那个时候运行该项工作。
让我们假设有两项工作 A 和 B,每项工作需要 50ms 的 CPU时间。但是,有一个明显的区别:A 运行 10ms,然后发出 I/O 请求(假设 I/O 每个都需要10ms),而 B 只是使用 CPU 50ms,不执行 I/O。调度程序先运行 A,然后运行 B。
题目
1.使用 SJF 和 FIFO 调度程序运行长度为 200 的 3 个作业时,计算响应时间和周转时间。
SJF:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 200 |
| 1 | 200 | 400 |
| 2 | 400 | 600 |
| FIFO: | ||
| 作业 id | 响应时间 | 周转时间 |
| — | — | — |
| 0 | 0 | 200 |
| 1 | 200 | 400 |
| 2 | 400 | 600 |
| 调度策略 | 平均响应时间 | 平均周转时间 |
| — | — | — |
| SJF | 200 | 400 |
| FIFO | 200 | 400 |
2.现在做同样的事情,但有不同长度的作业,即 100、200 和 300
SJF:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 100 |
| 1 | 100 | 300 |
| 2 | 300 | 600 |
| FIFO: | ||
| 作业 id | 响应时间 | 周转时间 |
| — | — | — |
| 0 | 0 | 100 |
| 1 | 100 | 300 |
| 2 | 300 | 600 |
| 调度策略 | 平均响应时间 | 平均周转时间 |
| — | — | — |
| SJF | 400/3 | 1000/3 |
| FIFO | 400/3 | 1000/3 |
3.现在做同样的事情,但采用 RR 调度程序,时间片为 1
长度为 200:
RR:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 598 |
| 1 | 1 | 599 |
| 2 | 2 | 600 |
| 平均响应时间 = 1 | ||
| 平均周转时间 = 599 |
长度为 100, 200, 300:
RR:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 298 |
| 1 | 1 | 499 |
| 2 | 2 | 600 |
| 平均响应时间 = 1 | ||
| 平均周转时间 = 456.67 |
4.对于什么类型的工作负载,SJF 提供与 FIFO 相同的周转时间?
运行时间相同的任务
5.对于什么类型的工作负载和量子长度(时间片长度),SJF 与 RR 提供相同的响应时间?
运行时间 <= 时间片
6.随着工作长度的增加,SJF 的响应时间会怎样?你能使用模拟程序来展示趋势吗?
响应时间越来越长
7.随着量子长度(时间片长度)的增加,RR 的响应时间会怎样?你能写出一个方程,计算给定 N 个工作时,最坏情况的响应时间吗?
平均响应时间增加
时间片 >= 工作最长运行时间时,有最坏情况
即 ti 为作业运行时间
res_avg = (0 + t1 + (t1+t2) + (t1+t2+t3) + … (t1+t2+t3 +…tN-1))/N
调度-多级反馈队列
多级反馈队列需要解决两方面的问题。
首先,它要优化周转时间。这通过先执行短工作来实现。然而,操作系统通常不知道工作要运行多久,而这又是SJF(或 STCF)等算法所必需的。
其次,MLFQ 希望给交互用户(如用户坐在屏幕前,等着进程结束)很好的交互体验,因此需要降低响应时间。然而,像轮转这样的算法虽然降低了响应时间,周转时间却很差。
所以这里的问题是:通常我们对进程一无所知,应该如何构建调度程序来实现这些目标?调度程序如何在运行过程中学习进程的特征,从而做出更好的调度决策?
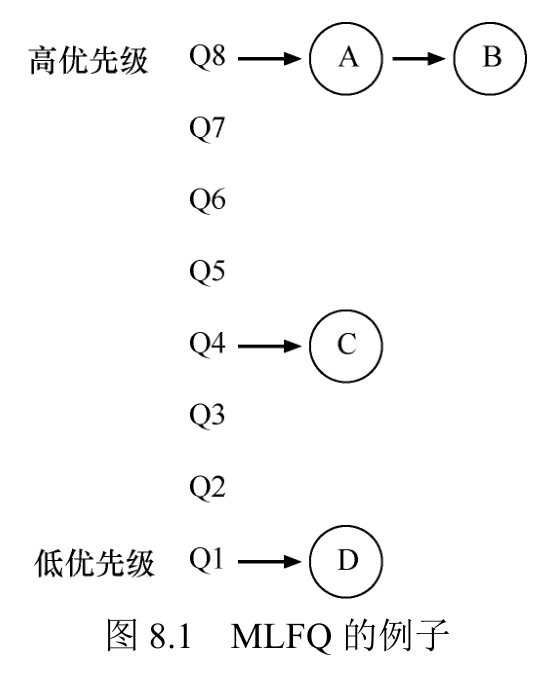
MLFQ:基本规则
MLFQ 中有许多独立的队列(queue),每个队列有不同的优先级(priority level)。任何时刻,一个工作只能存在于一个队列中。MLFQ 总是优先执行较高优先级的工作(即在较
高级队列中的工作)。
当然,每个队列中可能会有多个工作,因此具有同样的优先级。在这种情况下,我们就对这些工作采用轮转调度。
规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
规则 2:如果 A 的优先级 = B 的优先级,轮转运行A 和 B。
尝试 1:如何改变优先级
规则 3:工作进入系统时,放在最高优先级(最上层队列)。
规则 4a:工作用完整个时间片后,降低其优先级(移入下一个队列)。
规则 4b:如果工作在其时间片以内主动释放 CPU,则优先级不变。
实例 1:单个长工作
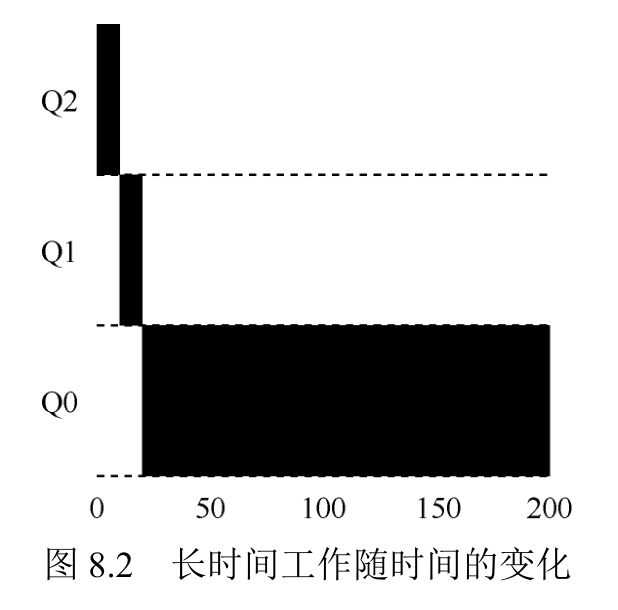
该工作首先进入最高优先级(Q2)。执行一个 10ms 的时间片后,调度程序将工作的优先级减 1,因此进入 Q1。在 Q1 执行一个时间片后,最终降低优先级进入系统的最低优先级(Q0),一直留在那里。
实例 2:来了一个短工作
有两个工作:A是一个长时间运行的 CPU 密集型工作,B 是一个运行时间很短的交互型工作。假设 A 执行一段时间后 B 到达。
A(用黑色表示)在最低优先级队列执行(长时间运行的 CPU 密集型工作都这样)。B(用灰色表示)在时间 T=100 时到达,并被加入最高优先级队列。由于它的运行时间很短(只有 20ms),经过两个时间片,在被移入最低优先级队列之前,B 执行完毕。然后 A 继续运行(在低优先级)。
主要目标:如果不知道工作是短工作还是长工作,那么就在开始的时候假设其是短工作,并赋予最高优先级。如果确实是短工作,则很快会执行完毕,否则将被慢慢移入低优先级队列,而这时该工作也被认为是长工作了。通过这种方式,MLFQ 近似于 SJF。
实例 3:如果有 I/O 呢
假设交互型工作中有大量的 I/O 操作(比如等待用户的键盘或鼠标输入),它会在时间片用完之前放弃 CPU。在这种情况下,我们不想处罚它,只是保持它的优先级不变。
交互型工作 B(用灰色表示)每执行 1ms 便需要进行 I/O操作,它与长时间运行的工作 A(用黑色表示)竞争 CPU。MLFQ 算法保持 B 在最高优先级,因为 B 总是让出 CPU。如果 B 是交互型工作,MLFQ 就进一步实现了它的目标,让交互型工作快速运行。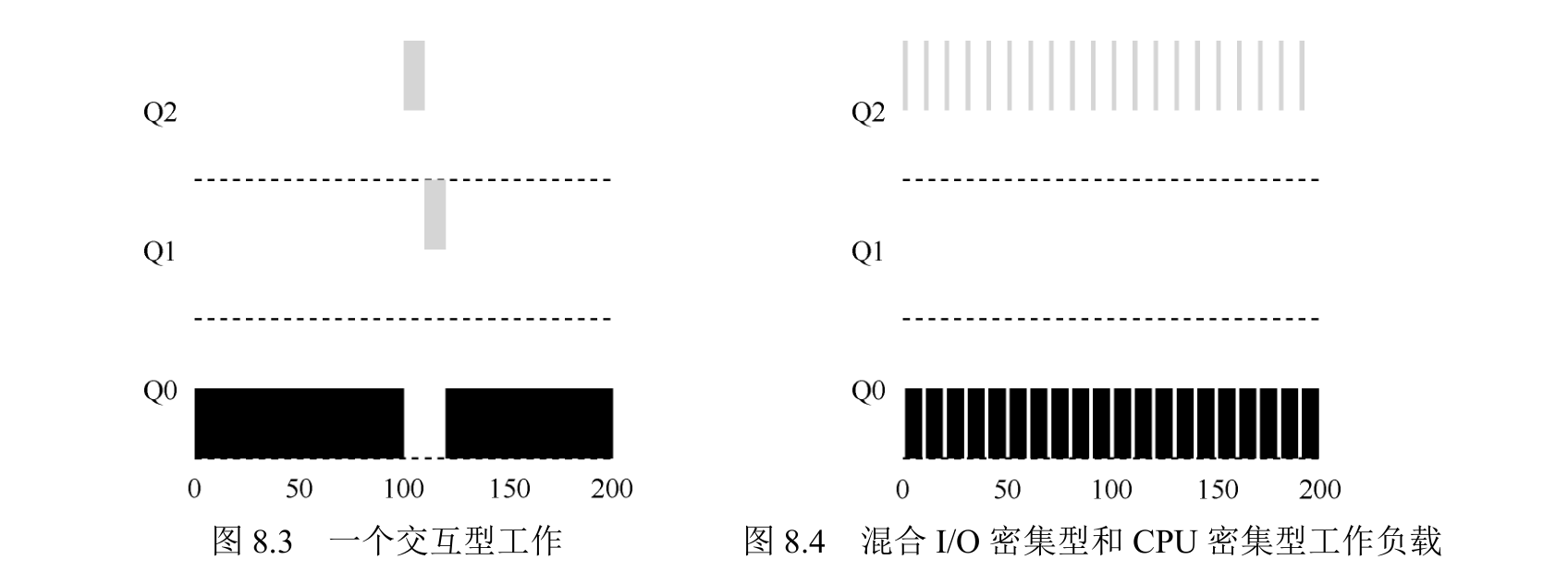
当前 MLFQ 的一些问题
首先,会有饥饿(starvation)问题。如果系统有“太多”交互型工作,就会不断占用CPU,导致长工作永远无法得到 CPU(它们饿死了)。即使在这种情况下,我们希望这些长工作也能有所进展。
愚弄调度程序指的是用一些卑鄙的手段欺骗调度程序,让它给你远超公平的资源。上述算法对如下的攻击束手无策:进程在时间片用完之前,调用一个 I/O 操作(比如访问一个无关的文件),从而主动释放 CPU。如此便可以保持在高优先级,占用更多的 CPU 时间。做得好时(比如,每运行 99%的时间片时间就主动放弃一次 CPU),工作可以几乎独占 CPU。
最后,一个程序可能在不同时间表现不同。一个计算密集的进程可能在某段时间表现为一个交互型的进程。用我们目前的方法,它不会享受系统中其他交互型工作的待遇。
尝试 2:提升优先级
规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
新规则一下解决了两个问题。首先,进程不会饿死——在最高优先级队列中,它会以轮转的方式,与其他高优先级工作分享 CPU,从而最终获得执行。其次,如果一个 CPU 密集型工作变成了交互型,当它优先级提升时,调度程序会正确对待它。
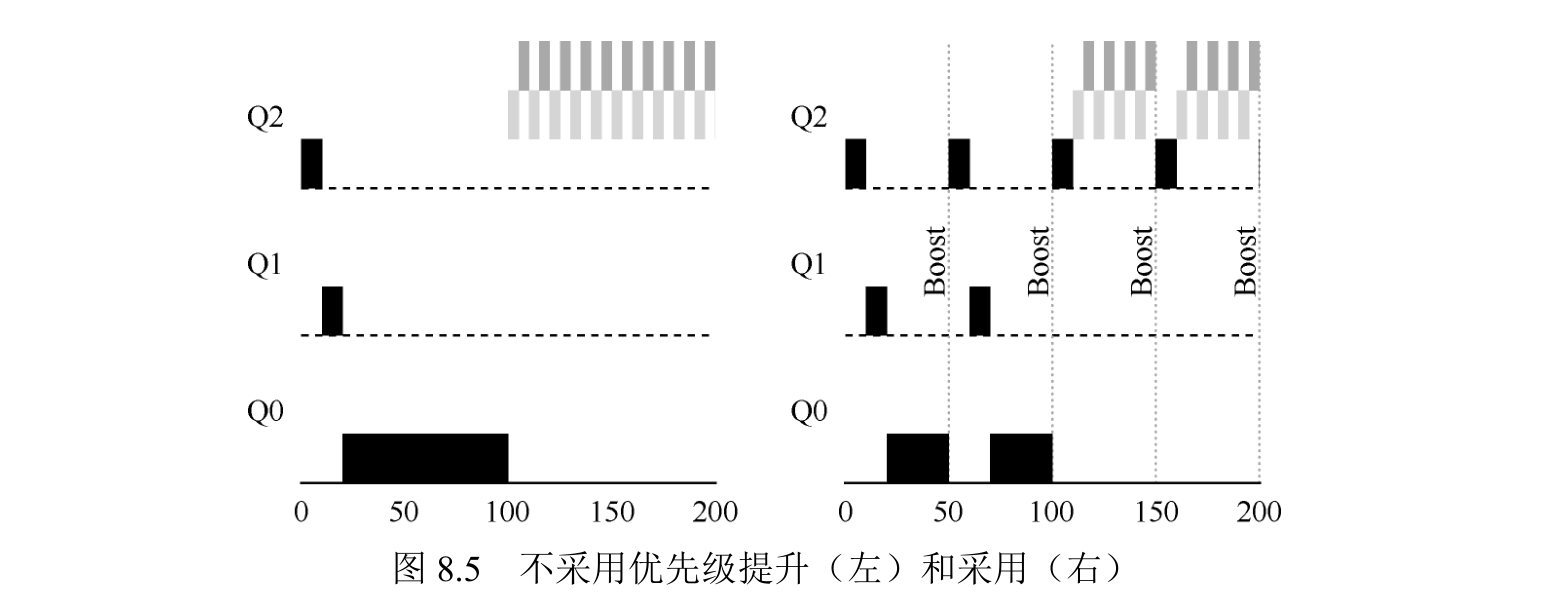
左边没有优先级提升,长工作在两个短工作到达后被饿死。右边每 50ms 就有一次优先级提升(这里只是举例,这个值可能过小),因此至少保证长工作会有一些进展,每过 50ms 就被提升到最高优先级,从而定期获得执行。
尝试 3:更好的计时方式
工作在时间片以内释放 CPU,就保留它的优先级。那么应该怎么做?
这里的解决方案,是为 MLFQ 的每层队列提供更完善的 CPU 计时方式(accounting)。调度程序应该记录一个进程在某一层中消耗的总时间,而不是在调度时重新计时。 只要进程用完了自己的配额,就将它降到低一优先级的队列中去。不论它是一次用完的,还是拆成很多次用完。因此,我们重写规则 4a 和 4b。
规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列)。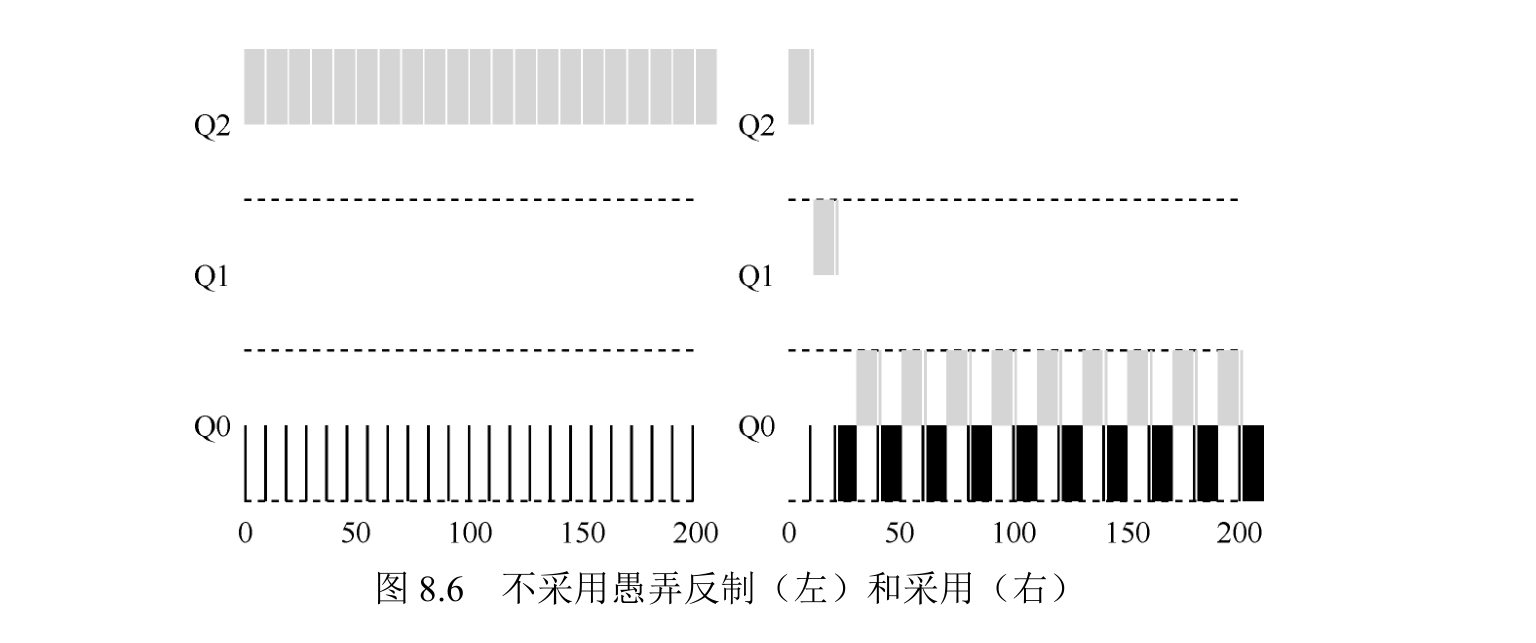
MLFQ 调优及其他问题
大多数的 MLFQ 变体都支持不同队列可变的时间片长度。高优先级队列通常只有较短的时间片(比如 10ms 或者更少),因而这一层的交互工作可以更快地切换。相反,低优先级队列中更多的是 CPU 密集型工作,配置更长的时间片会取得更好的效果。图 8.7展示了一个例子,两个长工作在高优先级队列执行 10ms,中间队列执行 20ms,最后在最低优先级队列执行 40ms。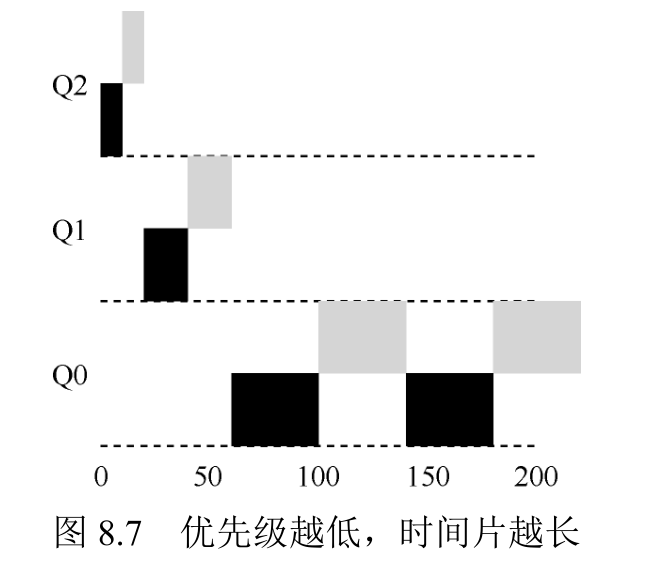
总结
本章包含了一组优化的 MLFQ 规则。为了方便查阅,我们重新列在这里。
规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
规则 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B。
规则 3:工作进入系统时,放在最高优先级(最上层队列)。
规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列)。
规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
操作系统导论-调度-比例份额
比例份额算法基于一个简单的想法:调度程序的最终目标,是确保每个工作获得一定比例的 CPU 时间,而不是优化周转时间和响应时间。
基本概念:彩票数表示份额
调度程序知道总共的彩票数(在我们的例子中,有 100 张)。调度程序抽取中奖彩票,这是从 0 和 99之间的一个数,拥有这个数对应的彩票的进程中奖。假设进程 A 拥有 0 到 74 共 75 张彩票,进程 B 拥有 75 到 99 的 25 张,中奖的彩票就决定了运行 A 或 B。调度程序然后加载中奖进程的状态,并运行它。
彩票机制
一种方式是利用彩票货币(ticket currency)的概念。这种方式允许拥有一组彩票的用户以他们喜欢的某种货币,将彩票分给自己的不同工作。之后操作系统再自动将这种货币兑换为正确的全局彩票。
比如,假设用户 A 和用户 B 每人拥有 100 张彩票。用户 A 有两个工作 A1 和 A2,他以自己的货币,给每个工作 500 张彩票(共 1000 张)。用户 B 只运行一个工作,给它 10 张彩票(总共 10 张)。操作系统将进行兑换,将 A1 和 A2 拥有的 A 的货币 500 张,兑换成全局货币 50 张。类似地,兑换给 B1 的 10 张彩票兑换成 100 张。然后会对全局彩票货币(共 200张)举行抽奖,决定哪个工作运行。
另一个有用的机制是彩票转让(ticket transfer)。通过转让,一个进程可以临时将自己的彩票交给另一个进程。这种机制在客户端/服务端交互的场景中尤其有用,在这种场景中,客户端进程向服务端发送消息,请求其按自己的需求执行工作,为了加速服务端的执行,客户端可以将自己的彩票转让给服务端,从而尽可能加速服务端执行自己请求的速度。服务端执行结束后会将这部分彩票归还给客户端。
最后,彩票通胀(ticket inflation)有时也很有用。利用通胀,一个进程可以临时提升或降低自己拥有的彩票数量。当然在竞争环境中,进程之间互相不信任,这种机制就没什么意义。一个贪婪的进程可能给自己非常多的彩票,从而接管机器。但是,通胀可以用于进程之间相互信任的环境。在这种情况下,如果一个进程知道它需要更多 CPU 时间,就可以增加自己的彩票,从而将自己的需求告知操作系统,这一切不需要与任何其他进程通信。
实现


这段代码从前向后遍历进程列表,将每张票的值加到 counter 上,直到值超过 winner。这时,当前的列表元素所对应的进程就是中奖者。在我们的例子中,中奖彩票是 300。首先,计 A 的票后,counter 增加到 100。因为 100 小于 300,继续遍历。然后 counter 会增加到 150(B 的彩票),仍然小于 300,继续遍历。最后,counter 增加到 400(显然大于 300),因此退出遍历,current 指向 C(中奖者)。
步长调度
系统中的每个工作都有自己的步长,这个值与票数值成反比。在上面的例子中,A、B、C 这 3 个工作的票数分别是 100、50 和 250,我们通过用一个大数分别除以他们的票数来获得每个进程的步长。比如用 10000 除以这些票数值,得到了 3 个进程的步长分别为 100、200 和 40。 我们称这个值为每个进程的步长(stride)。每次进程运行后,我们会让它的计数器 [称为行程(pass)值] 增加它的步长,记录它的总体进展。
当需要进行调度时,选择目前拥有最小行程值的进程,并且在运行之后将该进程的行程值增加一个步长。
在我们的例子中,3 个进程(A、B、C)的步长值分别为 100、200 和 40,初始行程值都为 0。因此,最初,所有进程都可能被选择执行。假设选择 A(任意的,所有具有同样低的行程值的进程,都可能被选中)。A 执行一个时间片后,更新它的行程值为 100。然后运行 B,并更新其行程值为 200。最后执行 C,C 的行程值变为 40。这时,算法选择最小的行程值,是 C,执行并增加为 80(C 的步长是 40)。然后 C 再次运行(依然行程值最小),行程值增加到 120。现在运行 A,更新它的行程值为 200(现在与 B 相同)。然后 C 再次连续运行两次,行程值也变为 200。此时,所有行程值再次相等,这个过程会无限地重复下去。
表 9.1 展示了一段时间内调度程序的行为。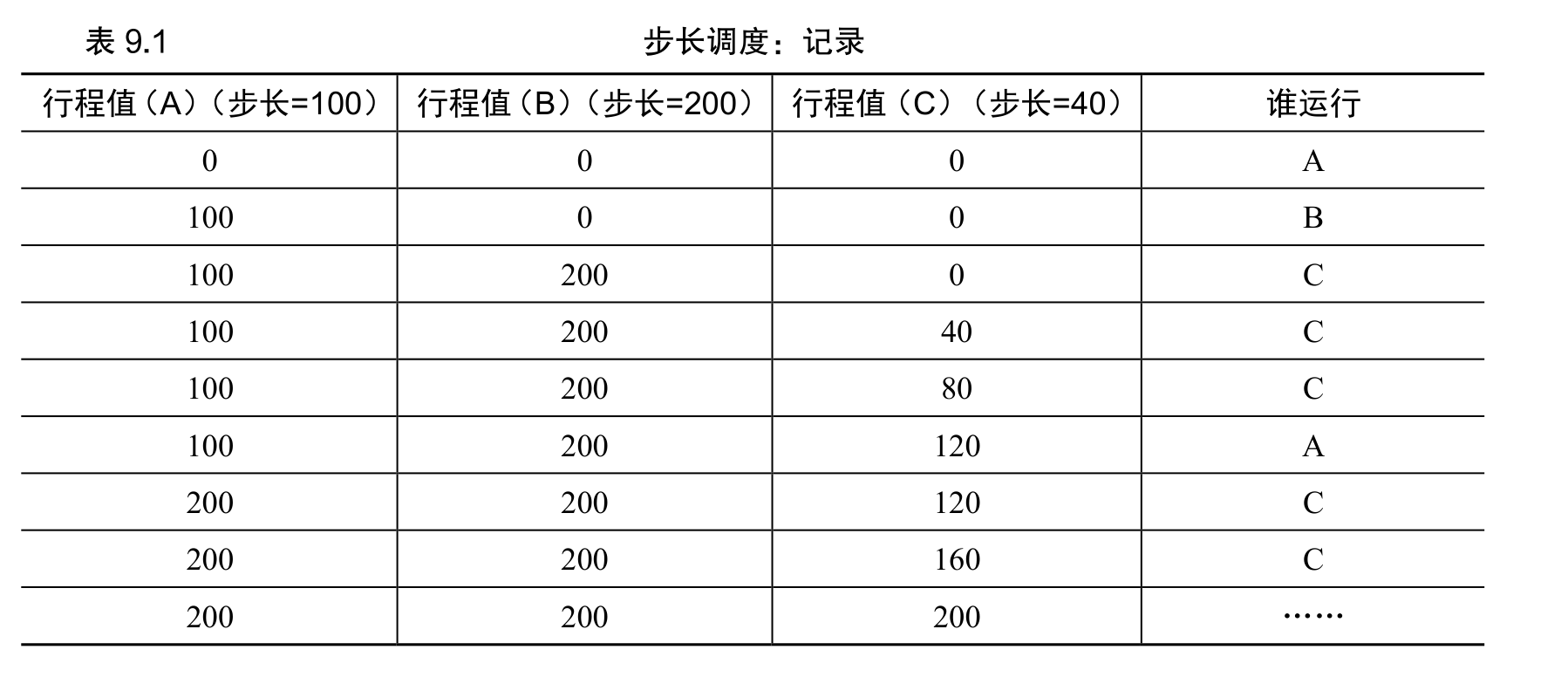
可以看出,C 运行了 5 次、A 运行了 2 次,B 一次,正好是票数的比例——200、100 和 50。彩票调度算法只能一段时间后,在概率上实现比例,而步长调度算法可以在每个调度周期后做到完全正确。
多处理器调度(高级)
多核处理器(multicore)将多个 CPU核组装在一块芯片上,是这种扩散的根源。
多线程应用可以将工作分散到多个 CPU 上,因此 CPU资源越多就运行越快。

