抽象:地址空间
早期系统
从内存来看,早期的机器并没有提供多少抽象给用户。
操作系统曾经是一组函数(实际上是一个库),在内存中(在本例中,从物理地址 0 开始),然后有一个正在运行的程序(进程),目前在物理内存中(在本例中,从物理地址 64KB 开始),并使用剩余的内存。这里几乎没有抽象,用户对操作系统的要求也不多。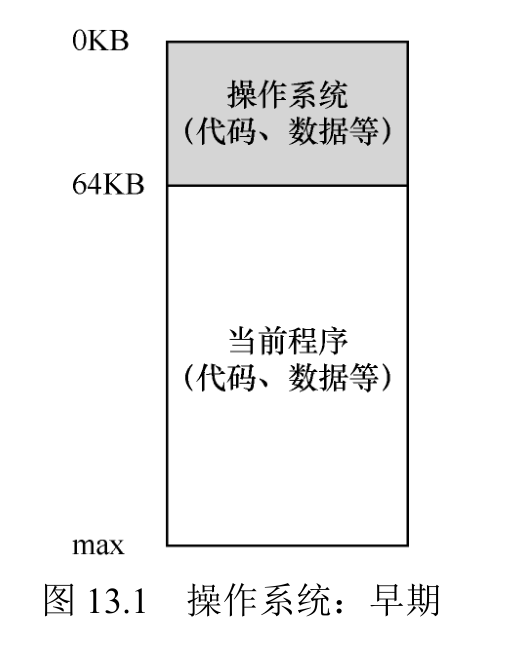
多道程序和时分共享
由于机器昂贵,多道程序(multiprogramming)系统时代开启,其中多个进程在给定时间准备运行,比如当有一个进程在等待 I/O 操作的时候,操作系统会切换这些进程,这样增加了 CPU 的有效利用率(utilization)。
但很快,人们开始对机器要求更多,分时系统的时代诞生了,他们厌倦了长时间的(因此也是低效率的)编程—调试循环。交互性(interactivity)变得很重要,因为许多用户可能同时在使用机器,每个人都在等待(或希望)他们执行的任务及时响应。
一种实现时分共享的方法,是让一个进程单独占用全部内存运行一小段时间,然后停止它,并将它所有的状态信息保存在磁盘上(包含所有的物理内存),加载其他进程的状态信息,再运行一段时间,这就实现了某种比较粗糙的机器共享。
将全部的内存信息保存到磁盘就太慢了。因此,在进程切换的时候,我们仍然将进程信息放在内存中,这样操作系统可以更有效率地实现时分共享。
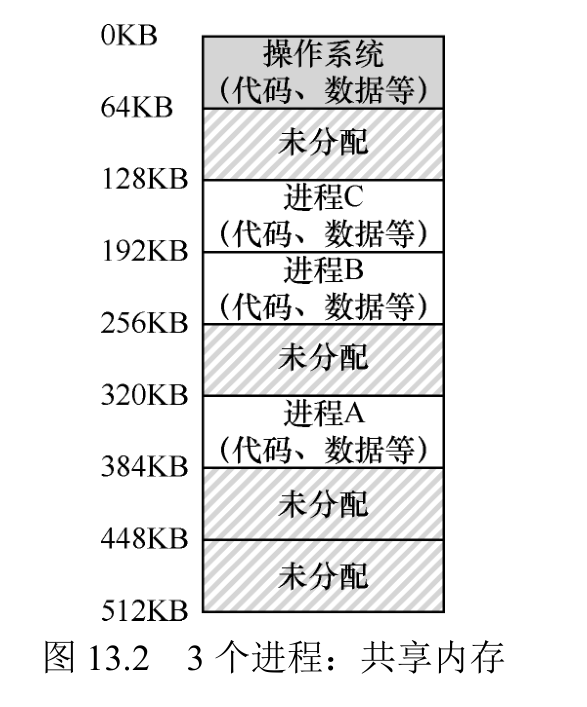
有 3 个进程(A、B、C),每个进程拥有从512KB 物理内存中切出来给它们的一小部分内存。假定只有一个 CPU,操作系统选择运行其中一个进程(比如 A),同时其他进程(B 和 C)则在队列中等待运行。
多个程序同时驻留在内存中,使保护(protection)成为重要问题。人们不希望一个进程可以读取其他进程的内存,更别说修改了。
地址空间
操作系统需要提供一个易用(easy to use)的物理内存抽象。这个抽象叫作地址空间(address space),是运行的程序看到的系统中的内存。
一个进程的地址空间包含运行的程序的所有内存状态。比如:程序的代码(code,指令)必须在内存中,因此它们在地址空间里。当程序在运行的时候,利用栈(stack)来保存当前的函数调用信息,分配空间给局部变量,传递参数和函数返回值。最后,堆(heap)用于管理动态分配的、用户管理的内存,就像你从 C 语言中调用 malloc()或面向对象语言(如 C ++或 Java)中调用 new 获得内存。当然,还有其他的东西(例如,静态初始化的变量),但现在假设只有这 3 个部分:代码、栈和堆。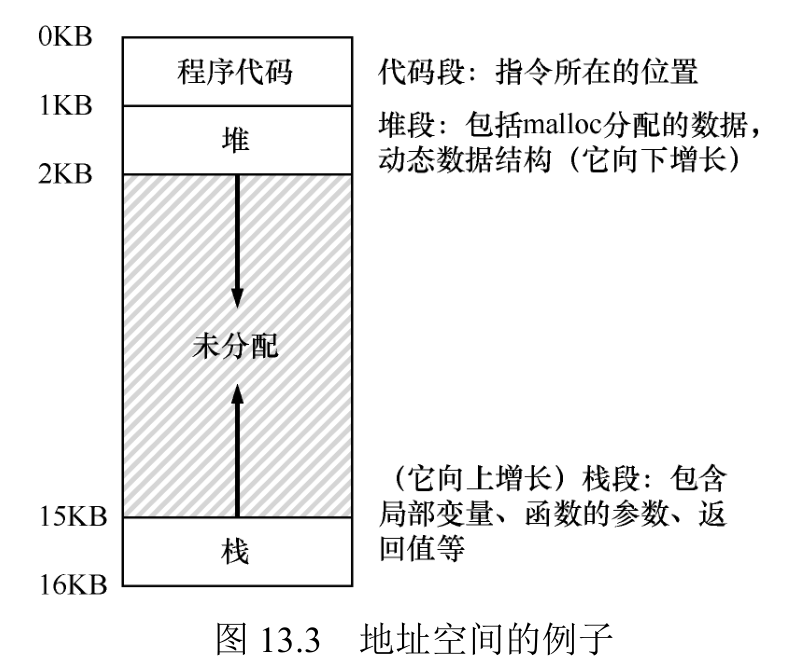
程序代码位于地址空间的顶部(在本例中从 0 开始,并且装入到地址空间
的前 1KB)。代码是静态的(因此很容易放在内存中),所以可以将它放在地址空间的顶部,我们知道程序运行时不再需要新的空间。
当我们描述地址空间时,所描述的是操作系统提供给运行程序的抽象(abstract)。程序不在物理地址 0~16KB 的内存中,而是加载在任意的物理地址。
操作系统在单一的物理内存上为多个运行的进程(所有进程共享内存)构建一个私有的、可能很大的地址空间的抽象。当操作系统这样做时,我们说操作系统在虚拟化内存(virtualizing memory)。
通过内存隔离,操作系统进一步确保运行程序不会影响底层操作系统的操作。一些现代操作系统通过将某些部分与操作系统的其他部分分离,实现进一步的隔离。这样的微内核(microkernel)可以比整体内核提供更大的可靠性。
目标
虚拟内存(VM)系统的一个主要目标是透明(transparency)。操作系统实现虚拟内存的方式,应该让运行的程序看不见。因此,程序不应该感知到内存被虚拟化的事实,相反,程序的行为就好像它拥有自己的私有物理内存。在幕后,操作系统(和硬件)完成了所有的工作,让不同的工作复用内存,从而实现这个假象。
虚拟内存的另一个目标是效率(efficiency)。操作系统应该追求虚拟化尽可能高效(efficient),包括时间上(即不会使程序运行得更慢)和空间上(即不需要太多额外的内存来支持虚拟化)。在实现高效率虚拟化时,操作系统将不得不依靠硬件支持,包括 TLB 这样的硬件功能(我们将在适当的时候学习)。
虚拟内存第三个目标是保护(protection)。操作系统应确保进程受到保护(protect),不会受其他进程影响,操作系统本身也不会受进程影响。当一个进程执行加载、存储或指令提取时,它不应该以任何方式访问或影响任何其他进程或操作系统本身的内存内容(即在它的地址空间之外的任何内容)。因此,保护让我们能够在进程之间提供隔离(isolation)的特性,每个进程都应该在自己的独立环境中运行,避免其他出错或恶意进程的影响。
在一个程序中打印出一个地址,那就是一个虚拟的地址。虚拟地址只是提供地址如何在内存中分布的假象,只有操作系统(和硬件)才知道物理地址。
c语言存储了程序的指令和常量数据。函数的代码在程序被编译后会被存储在代码区,函数地址就是指向函数在代码区的位置。
插叙:内存操作API
内存类型
在运行一个 C 程序的时候,会分配两种类型的内存。
第一种称为栈内存,它的申请和释放操作是编译器来隐式管理的,所以有时也称为自动(automatic)内存。
第二种叫堆(heap)内存,其中所有的申请和释放操作都由程序员显式地完成。
int *x = (int *) malloc(sizeof(int));
注意到栈和堆的分配都发生在这一行:首先编译器看到指针的声明(int * x)时,知道为一个整型指针分配空间,随后,当程序调用 malloc()时,它会在堆上请求整数的空间,函数返回这样一个整数的地址(成功时,失败时则返回 NULL),然后将其存储在栈中以供程序使用。
malloc()调用
malloc 函数非常简单:传入要申请的堆空间的大小,它成功就返回一个指向新申请空间的指针,失败就返回 NULL。
只需要包含头文件 stdlib.h 就可以使用 malloc 了。但实际上,甚至都不需这样做,因为 C 库是 C 程序默但链接的,其中就有 mallock()的代码,加上这个头文件只是让编译器检查你是否正确调用了 malloc()。
free()调用
没什么讲的
底层操作系统支持
malloc()和 free()不是系统调用,而是库调用。
malloc库负责管理虚拟地址空间内的内存空间,但它本身是通过调用操作系统的一些系统调用来实现的。这些系统调用会进入操作系统,来请求本多内存或者将一些内容释放回系统。
一个这样的系统调用叫作 brk,它被用来改变程序分断(break)的位置:堆结束的位置。它需要一个参数(新分断的地址),从而根据新分断是大于还是小于当前分断,来增加或减小堆的大小。另一个调用 sbrk 要求传入一个增量,但目的是类似的。
习题
1.首先,编写一个名为 null.c 的简单程序,它创建一个指向整数的指针,将其设置为 NULL,然后尝试对其进行释放内存操作。把它编译成一个名为 null 的可执行文件。当你运行这个程序时会发生什么?
1 |
|
什么都没发生……
4.编写一个使用 malloc()来分配内存的简单程序,但在退出之前忘记释放它。这个程序运行时会发生什么?你可以用 gdb 来查找它的任何问题吗?用 valgrind 呢(再次使用–leak-check=yes 标志)?
1 |
|
5.编写一个程序,使用 malloc 创建一个名为 data、大小为 100 的整数数组。然后,将 data[100]设置为 0。当你运行这个程序时会发生什么?当你使用 valgrind 运行这个程序时会发生什么?程序是否正确?
还是什么都没发生……
但是1,没有释放指针内存泄漏.
2,Invalid write 无效写入,数组越界
6.创建一个分配整数数组的程序(如上所述),释放它们,然后尝试打印数组中某个元素的值。程序会运行吗?当你使用 valgrind时会发生什么?
程序会正常运行
使用 free 时,
不会改变被释放变量本身的值,调用 free() 后它仍然会指向相同的内存空间,但是此时该内存已无效
free 并不会覆盖释放的内存, 所以读取时仍然能读取到数值
机制:地址转换
在实现 CPU 虚拟化时,我们遵循的一般准则被称为受限直接访问(Limited Direct Execution,LDE)。LDE 背后的想法很简单:让程序运行的大部分指令直接访问硬件,只在一些关键点(如进程发起系统调用或发生时钟中断)由操作系统介入来确保“在正确时间,正确的地点,做正确的事”。
为了实现高效的虚拟化,操作系统应该尽量让程序自己运行,同时通过在关键点的及时介入(interposing),来保持对硬件的控制。高效和控制是现代操作系统的两个主要目标。
高效决定了我们要利用硬件的支持,这在开始的时候非常初级(如使用一些寄存器),但会变得相当复杂(比如我们会讲到的 TLB、页表等)。
控制意味着操作系统要确保应用程序只能访问它自己的内存空间。因此,要保护应用程序不会相互影响,也不会影响操作系统,我们需要硬件的帮助。
最后,我们对虚拟内存还有一点要求,即灵活性。具体来说,我们希望程序能以任何方式访问它自己的地址空间,从而让系统更容易编程。
利用地址转换,硬件对每次内存访问进行处理(即指令获取、数据读取或写入),将指令中的虚拟(virtual)地址转换为数据实际存储的物理(physical)地址。因此,在每次内存引用时,硬件都会进行地址转换,将应用程序的内存引用重定位到内存中实际的位置。
假象:每个程序都拥有私有的内存,那里存放着它自己的代码和数据。虚拟现实的背后是丑陋的物理事实:许多程序其实是在同一时间共享着内存,就像 CPU(或多个 CPU)在不同的程序间切换运行。
假设
我们先假设用户的地址空间必须连续地放在物理内存中。假设地址空间不是很大,小于物理内存的大小。最后,假设每个地址空间的大小完全一样。
一个例子
C 语言形式:
1 | void func() { |
对应的x86 汇编:
1 | movl 0x0(%ebx), %eax; |
0x0(%ebx)表示以%ebx寄存器中的值作为基址,偏移地址为0x0,即从%ebx指向的内存地址开始读取或写入数据。
在虚拟内存中,硬件可以介入到每次内存访问中,将进程提供的虚拟地址转换为数据实际存储的物理地址。
在图中,可以看到代码和数据都位于进程的地址空间,3 条指令序列位于地址 128(靠近头部的代码段),变量 x 的值位于地址 15KB(在靠近底部的栈中)。如图所示,x的初始值是 3000。
如果这 3 条指令执行,从进程的角度来看,发生了以下几次内存访问:
从地址 128 获取指令;
执行指令(从地址 15KB 加载数据);
从地址 132 获取命令;
执行命令(没有内存访问);
从地址 135 获取指令;
执行指令(新值存入地址 15KB)。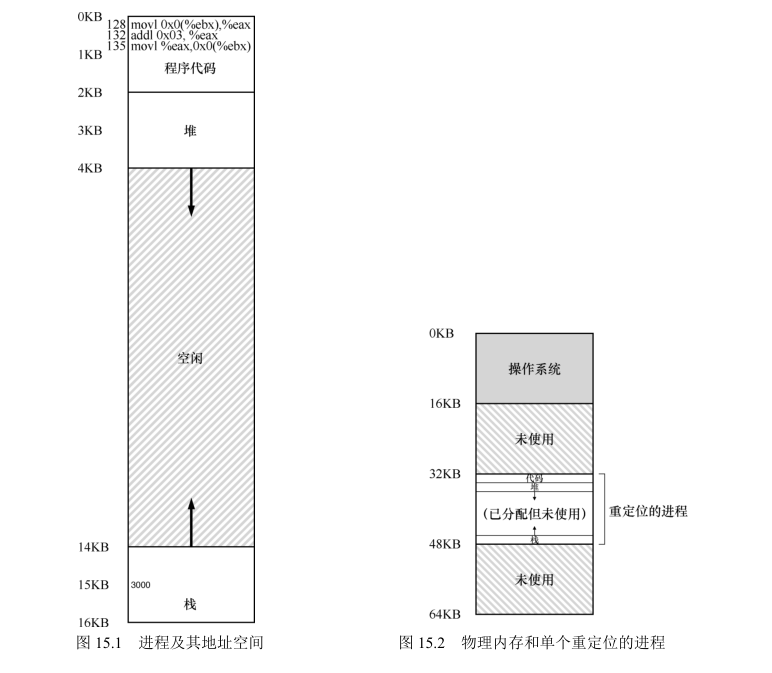
从程序的角度来看,它的地址空间(address space)从 0 开始到 16KB 结束。它包含的所有内存引用都应该在这个范围内。然而,对虚拟内存来说,操作系统希望将这个进程地址空间放在物理内存的其他位置,并不一定从地址 0 开始。
图 15.2 展示了一个例子,说明这个进程的地址空间被放入物理内存后可能的样子。从图 中可以看到,操作系统将第一块物理内存留给了自己,并将上述例子中的进程地址空间重定位到从 32KB 开始的物理内存地址。剩下的两块内存空闲(16~32KB 和 48~64KB)。
动态(基于硬件)重定位
它在首次出现的时分机器中引入,那时只是一个简单的思想,称为基址加界限机制(base and bound),有时又称为动态重定位(dynamic relocation),我们将互换使用这两个术语。
每个 CPU 需要两个硬件寄存器:基址(base)寄存器和界限(bound)寄存器,有时称为限制(limit)寄存器。这组基址和界限寄存器,让我们能够将地址空间放在物理内存的任何位置,同时又能确保进程只能访问自己的地址空间。
physical address = virtual address + base 没有算偏移量
物理地址=(虚拟地址-偏移量)+基地址。
进程中使用的内存引用都是虚拟地址(virtual address),硬件接下来将虚拟地址加上基址寄存器中的内容,得到物理地址(physical address),再发给内存系统。
补充:基于软件的重定位
例如,程序中有一条指令是从地址 1000 加载到寄存器(即 movl 1000,%eax),当整个程序的地址空间被加载到从 3000(不是程序认为的 0)开始的物理地址中,加载程序会重写指令中的地址(即 movl 4000, %eax),从而完成简单的静态重定位。
静态重定位有许多问题,首先也是最重要的是不提供访问保护,进程中的错误地址可能导致对其他进程或操作系统内存的非法访问,一般来说,需要硬件支持来实现真正的访问保护。静态重定位的另一个缺点是一旦完成,稍后很难将内存空间重定位到其他位置。
1 | 128: movl 0x0(%ebx), %eax |
程序计数器(PC)首先被设置为 128。当硬件需要获取这条指令时,它先将这个值加上基址寄存器中的 32KB(32768),得到实际的物理地址 32896,然后硬件从这个物理地址获取指令。接下来,处理器开始执行该指令。这时,进程发起从虚拟地址 15KB 的加载,处理器同样将虚拟地址加上基址寄存器内容(32KB),得到最终的物理地址 47KB,从而获得需要的数据。
将虚拟地址转换为物理地址,这正是所谓的地址转换(address translation)技术。也就是说,硬件取得进程认为它要访问的地址,将它转换成数据实际位于的物理地址。由于这种重定位是在运行时发生的,而且我们甚至可以在进程开始运行后改变其地址空间,这种技术一般被称为动态重定位(dynamic relocation)。
界限寄存器提供了访问保护。在上面的例子中,界限寄存器被置为 16KB。如果进程需要访问超过这个界限或者为负数的虚拟地址,CPU 将触发异常,进程最终可能被终止。界限寄存器的用处在于,它确保了进程产生的所有地址都在进程的地址“界限”中。
这种基址寄存器配合界限寄存器的硬件结构是芯片中的(每个 CPU 一对)。有时我们将CPU 的这个负责地址转换的部分统称为内存管理单元(Memory Management Unit,MMU)。随着我们开发更复杂的内存管理技术,MMU 也将有更复杂的电路和功能。
转换示例
设想一个进程拥有 4KB 大小地址空间(是的,小得不切实际),它被加载到从 16KB 开始的物理内存中。一些地址转换结果见表 15.1。
补充:数据结构——空闲列表
操作系统必须记录哪些空闲内存没有使用,以便能够为进程分配内存。很多不同的数据结构可以用于这项任务,其中最简单的(也是我们假定在这里采用的)是空闲列表(free list)。它就是一个列表,记录当前没有使用的物理内存的范围。
硬件支持:总结
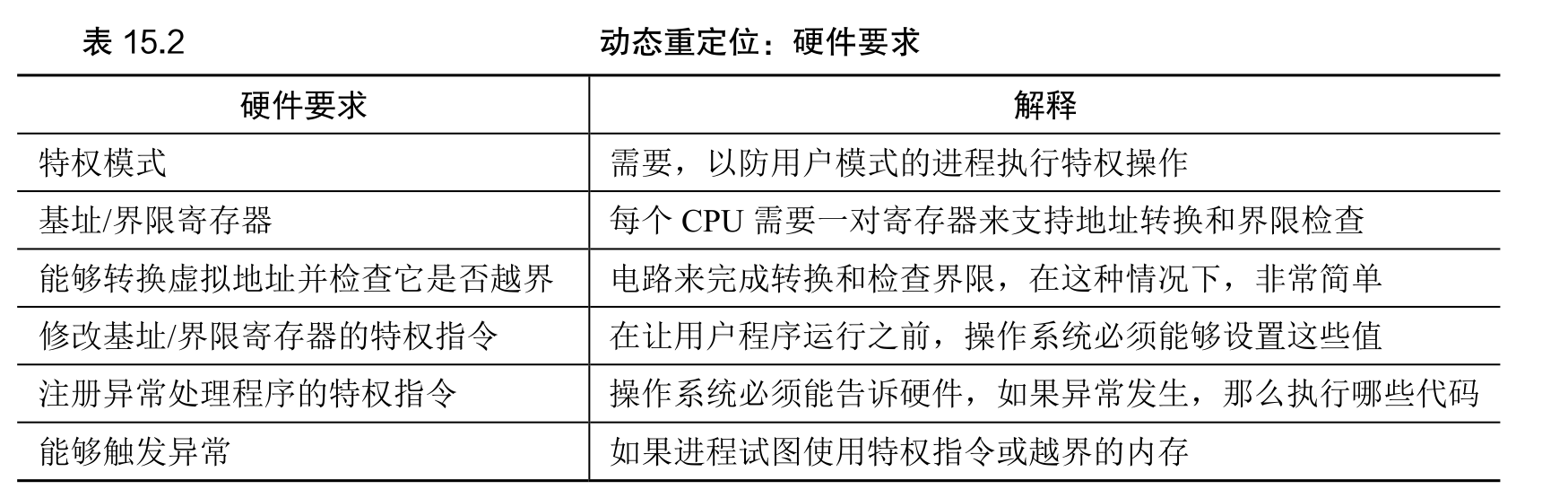
硬件应该提供一些特殊的指令,用于修改基址寄存器和界限寄存器,允许操作系统在切换进程时改变它们。这些指令是特权(privileged)指令,只有在内核模式下,才能修改这些寄存器。
操作系统的问题
硬件支持和操作系统管理结合在一起,实现了一个简单的虚拟内存。具体来说,在一些关键的时刻操作系统需要介入,以实现基址和界限方式的虚拟内存。
第一,在进程创建时,操作系统必须采取行动,为进程的地址空间找到内存空间。由于我们假设每个进程的地址空间小于物理内存的大小,并且大小相同,这对操作系统来说很容易。它可以把整个物理内存看作一组槽块,标记了空闲或已用。当新进程创建时,操作系统检索这个数据结构(常被称为空闲列表,free list),为新地址空间找到位置,并将其标记为已用。
在进程终止时(正常退出,或因行为不端被强制终止),操作系统也必须做一些工作,回收它的所有内存,给其他进程或者操作系统使用。在进程终止时,操作系统会将这些内存放回到空闲列表,并根据需要清除相关的数据结构。
在上下文切换时,操作系统也必须执行一些额外的操作。每个 CPU 毕竟只有一个基址寄存器和一个界限寄存器,但对于每个运行的程序,它们的值都不同,因为每个程序被加载到内存中不同的物理地址。因此,在切换进程时,操作系统必须保存和恢复基础和界限寄存器。具体来说,当操作系统决定中止当前的运行进程时,它必须将当前基址和界限寄存器中的内容保存在内存中,放在某种每个进程都有的结构中,如进程结构(process structure)或进程控制块(Process Control Block,PCB)中。类似地,当操作系统恢复执行某个进程时(或第一次执行),也必须给基址和界限寄存器设置正确的值。
操作系统必须提供异常处理程序(exception handler),或要一些调用的函数,像上面提到的那样。操作系统在启动时加载这些处理程序(通过特权命令)。例如,当一个进程试图越界访问内存时,CPU 会触发异常。在这种异常产生时,操作系统必须准备采取行动。通常操作系统会做出充满敌意的反应:终止错误进程。

按时间线展示了大多数硬件与操作系统的交互。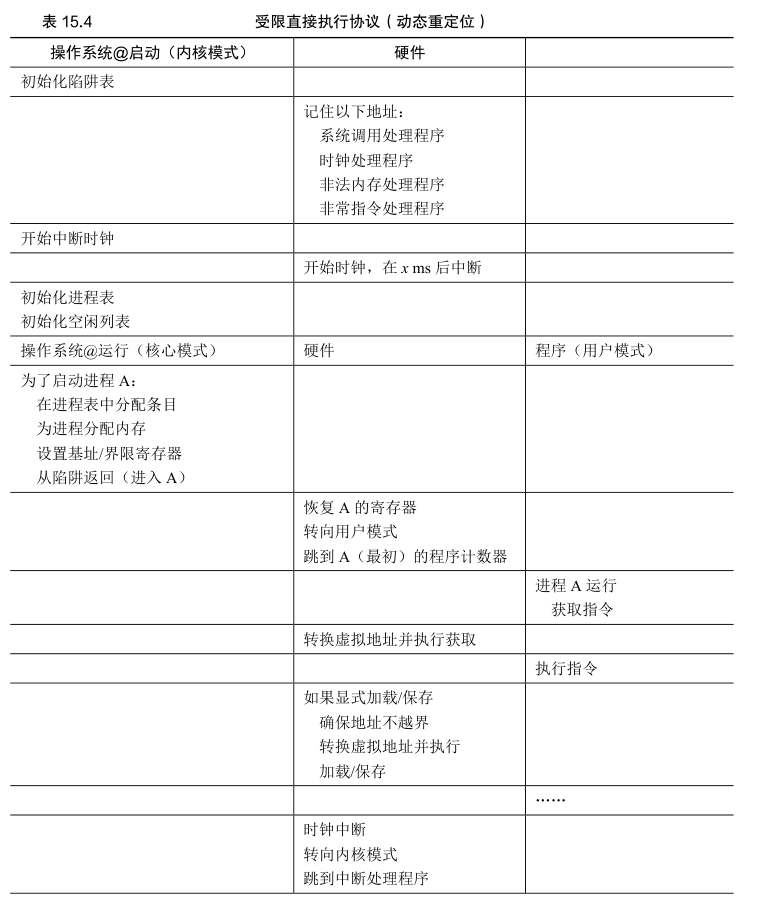
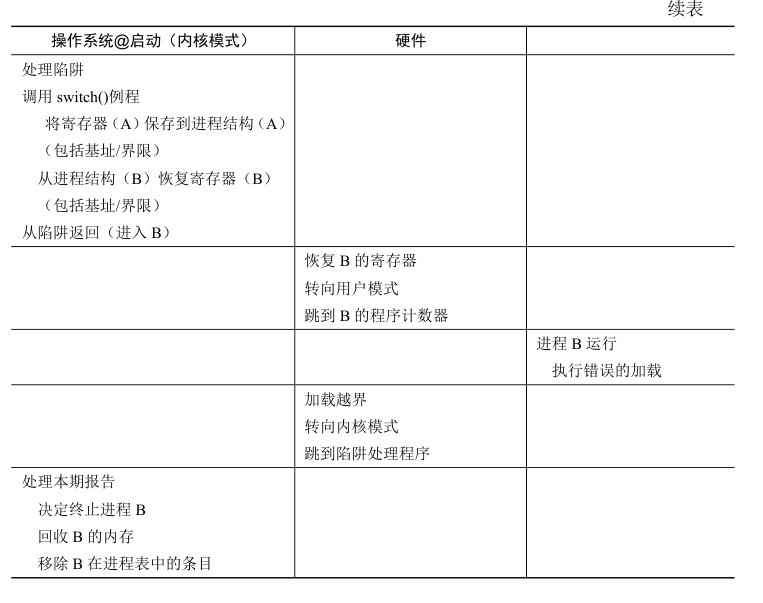
内部碎片和外部碎片
内部碎片是指分配给进程的内存块中,有一部分空间没有被利用,但由于无法分配给其他进程使用,而造成的浪费。
外部碎片是指存储器中有一些连续的空闲空间,但由于这些空间被多个小的不连续的空闲块所分割,无法满足大的内存需求。
分段内存管理碎片
分段内存管理没有内部碎片,因为他的逻辑定义,基址寄存器和界限寄存器决定了哪些是该进程所拥有的。所以没有已经分配给此进程但是没有用的空间,故没有内部碎片。
分段内存管理有外部碎片,因为他这一种内存管理方式占用空间不同,分着分着就有一些很小的没有办法再用的空间出现,这就是外部碎片。
分页内存管理碎片
分页内存管理有内部碎片,因为页这个词的定义他是没有意义的,他不像分段管理某一块代表了某一部分,分给这个进程的这一页如小于进程实际上拥有的,那么就产生了内部碎片。
分页内存管理没有外部碎片,外部碎片是剩余的没有办法被别的进程所用的空间碎片,分页的方式每个块大小相同所以不会产生外部碎片。
(分段有外部碎片的原因是他每个块的大小不同,如果有大的块想用这块小地址就用不了,所以才叫外部碎片,但是分页方式大家大小都一样,你肯定能用上,所以就没有外部碎片)
分段
栈和堆之间,有一大块“空闲”空间。
如果我们将整个地址空间放入物理内存,那么栈和堆之间的空间并没有被进程使用,却依然占用了实际的物理内存。因此,简单的通过基址寄存器和界限寄存器实现的虚拟内存很浪费。另外,如果剩余物理内存无法提供连续区域来放置完整的地址空间,进程便无法运行。这种基址加界限的方式看来并不像我们期望的那样灵活。
分段:泛化的基址/界限
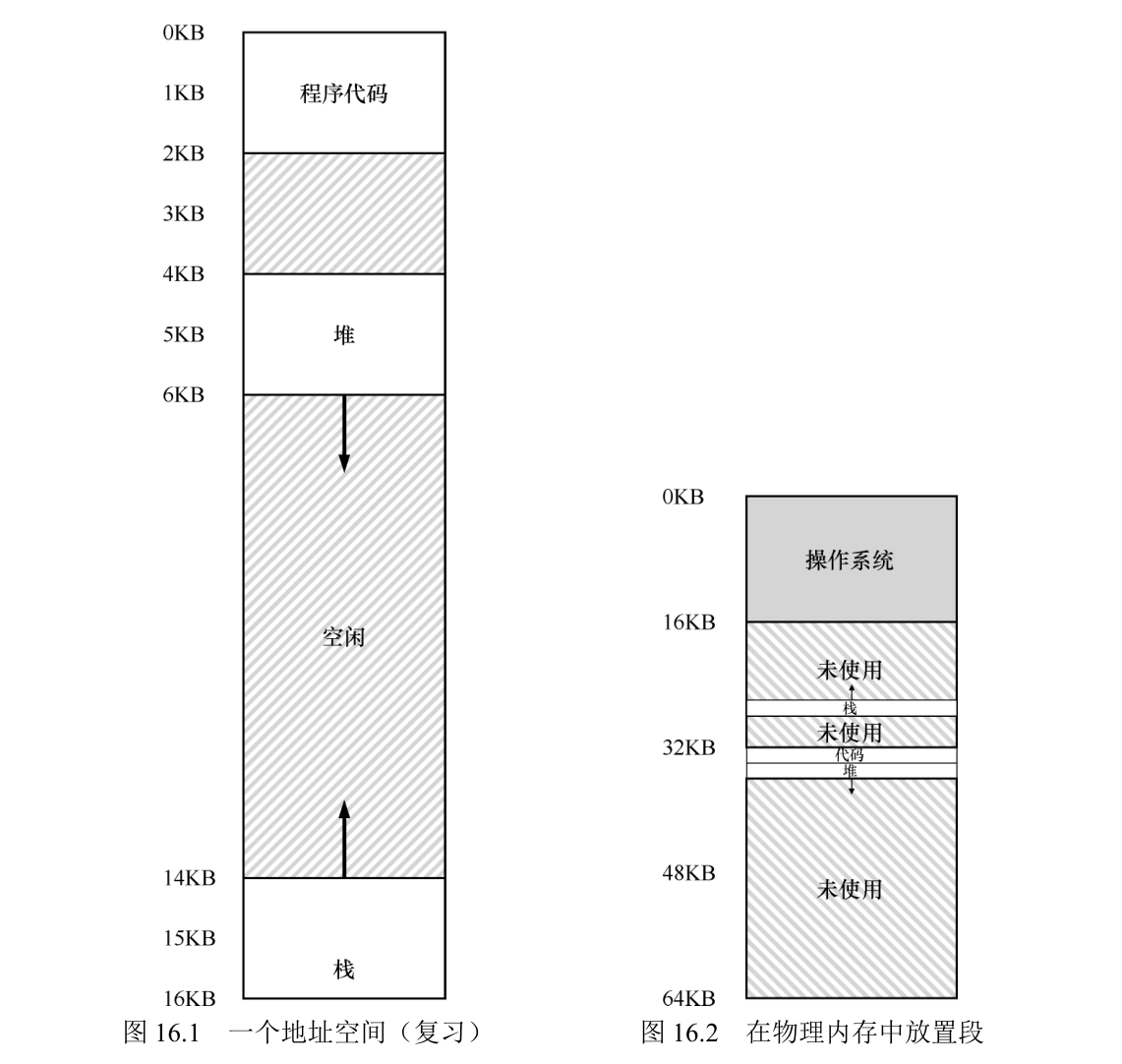
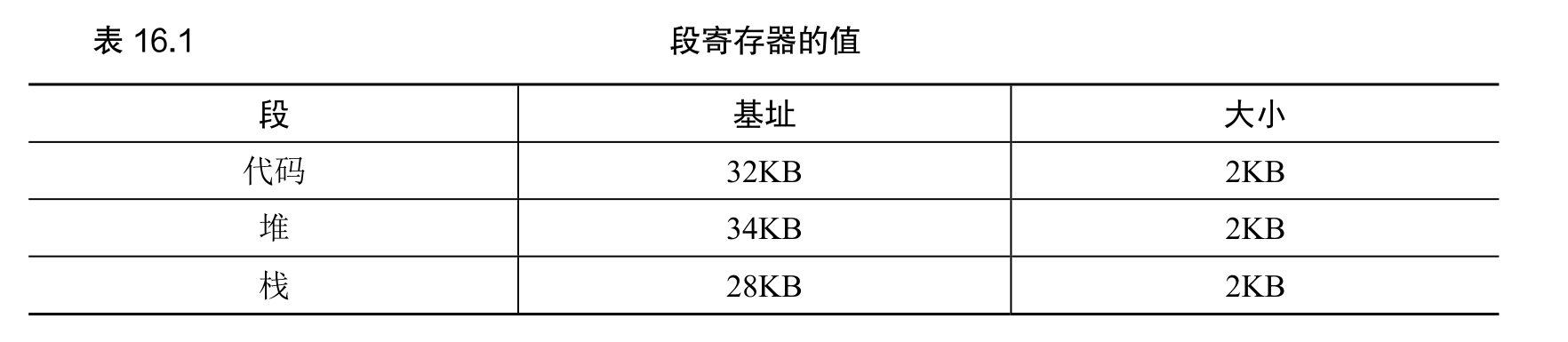
在 MMU 中引入不止一个基址和界限寄存器对,而是给地址空间内的每个逻辑段(segment)一对。一个段只是地址空间里的一个连续定长的区域,在典型的地址空间里有 3 个逻辑不同的段:代码、栈和堆。分段的机制使得操作系统能够将不同的段放到不同的物理内存区域,从而避免了虚拟地址空间中的未使用部分占用物理内存。
转换例子
假设现在要引用虚拟地址100(在代码段中),MMU 将基址值加上偏移量(100)得到实际的物理地址:100 + 32KB =32868。然后它会检查该地址是否在界限内(100 小于 2KB),发现是的,于是发起对物理地址 32868 的引用。
注意这里的代码段开始地址是0,偏移量是0
来看一个堆中的地址,虚拟地址 4200(同样参考图 16.1)。如果用虚拟地址 4200 加上堆的基址(34KB),得到物理地址 39016,这不是正确的地址。我们首先应该先减去堆的偏移量,即该地址指的是这个段中的哪个字节。因为堆从虚拟地址 4K(4096)开始,4200 的偏移量实际上是 4200 减去 4096,即 104,然后用这个偏移量(104)加上基址寄存器中的物理地址(34KB),得到真正的物理地址 34920。
注意这里的堆开始地址是4096,偏移量是4096,计算所占用空间时要减去偏移量。
我们引用哪个段
硬件在地址转换时使用段寄存器。它如何知道段内的偏移量,以及地址引用了哪个段?
一种常见的方式,有时称为显式(explicit)方式,就是用虚拟地址的开头几位来标识不同的段,VAX/VMS 系统使用了这种技术。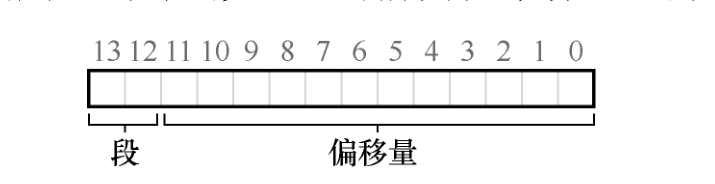
如果前两位是 00,硬件就知道这是属于代码段的地址,因此使用代码段的基址和界限来重定位到正确的物理地址。如果前两位是 01,则是堆地址,对应地,使用堆的基址和界限。 下面来看一个 4200 之上的堆虚拟地址,进行进制转换,确保弄清楚这些内容。虚拟地址 4200 的二进制形式如下: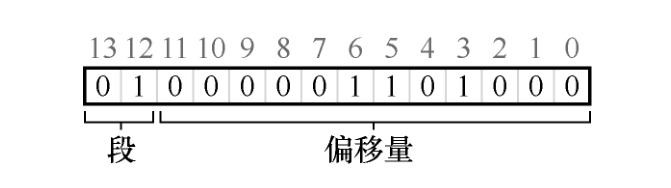
硬件就用前两位来决定使用哪个段寄存器,然后用后 12 位作为段内偏移。偏移量与基址寄存器相加,硬件就得到了最终的物理地址。
在隐式(implicit)方式中,硬件通过地址产生的方式来确定段。例如,如果地址由程序计数器产生(即它是指令获取),那么地址在代码段。如果基于栈或基址指针,它一定在栈段。其他地址则在堆段。
栈怎么办
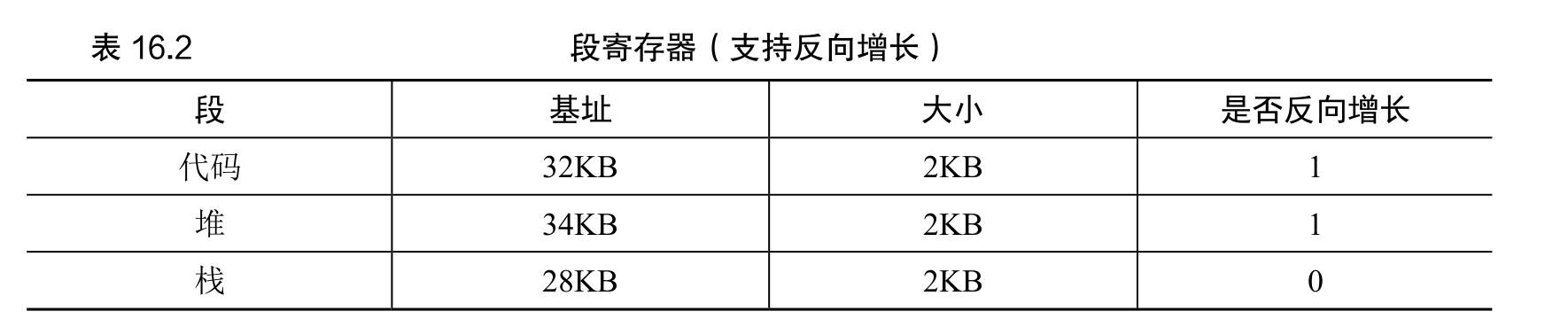
在表 16.1 中,栈被重定位到物理地址 28KB。但有一点关键区别,它反向增长。在物理内存中,它始于 28KB,增长回到 26KB,相应虚拟地址从 16KB 到 14KB。地址转换必须有所不同。
- 首先,我们需要一点硬件支持。除了基址和界限外,硬件还需要知道段的增长方向(用一位区分,比如 1 代表自小而大增长,0 反之)。
支持共享
要节省内存,有时候在地址空间之间共享(share)某些内存段是有用的。尤其是,代码共享很常见。
基本为每个段增加了几个位,标识程序是否能够读写该段,或执行其中的代码。通过将代码段标记为只读,同样的代码可以被多个进程共享,而不用担心破坏隔离。虽然每个进程都认为自己独占这块内存,但操作系统秘密地共享了内存,进程不能修改这些内存,所以假象得以保持。
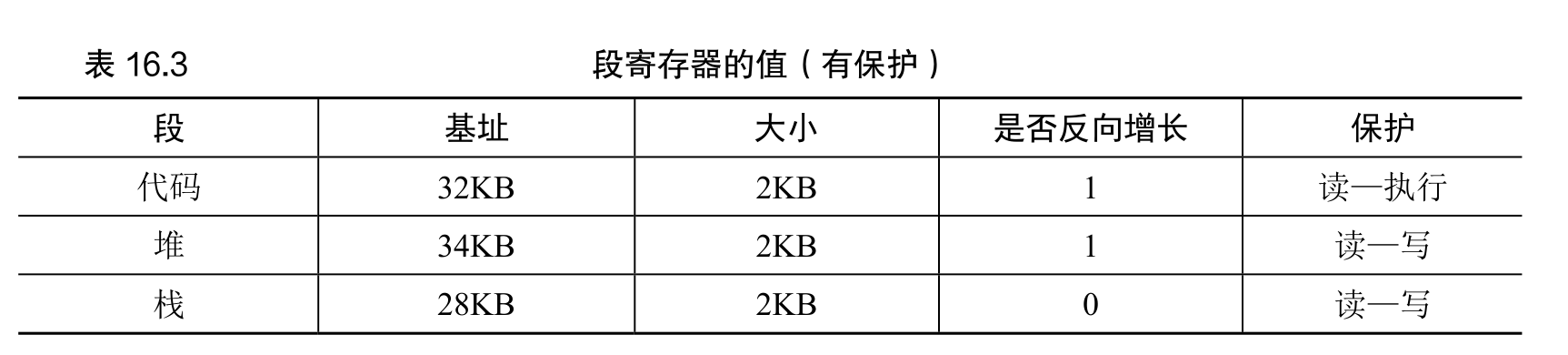
除了检查虚拟地址是否越界,硬件还需要检查特定访问是否允许。如果用户进程试图写入只读段,或从非执行段执行指令,硬件会触发异常,让操作系统来处理出错进程。
细粒度与粗粒度的分段
支持许多段需要进一步的硬件支持,并在内存中保存某种段表(segment table)。这种段表通常支持创建非常多的段,因此系统使用段的方式,可以比之前讨论的方式更灵活。例如,像 Burroughs B5000 这样的早期机器可以支持成千上万的段,有了操作系统和硬件的支持,编译器可以将代码段和数据段划分为许多不同的部分。当时的考虑是,通过更细粒度的
段,操作系统可以更好地了解哪些段在使用哪些没有,从而可以更高效地利用内存。
操作系统支持
系统运行时,地址空间中的不同段被重定位到物理内存中。与我们之前介绍的整个地址空间只有一个基址/界限寄存器对的方式相比,大量节省了物理内存。
操作系统在上下文切换时应该做什么?
各个段寄存器中的内容必须保存和恢复。显然,每个进程都有自己独立的虚拟地址空间,操作系统必须在进程运行前,确保这些寄存器被正确地赋值。
物理内存很快充满了许多空闲空间的小洞,因而很难分配给新的段,或扩大已有的段。这种问题被称为外部碎片。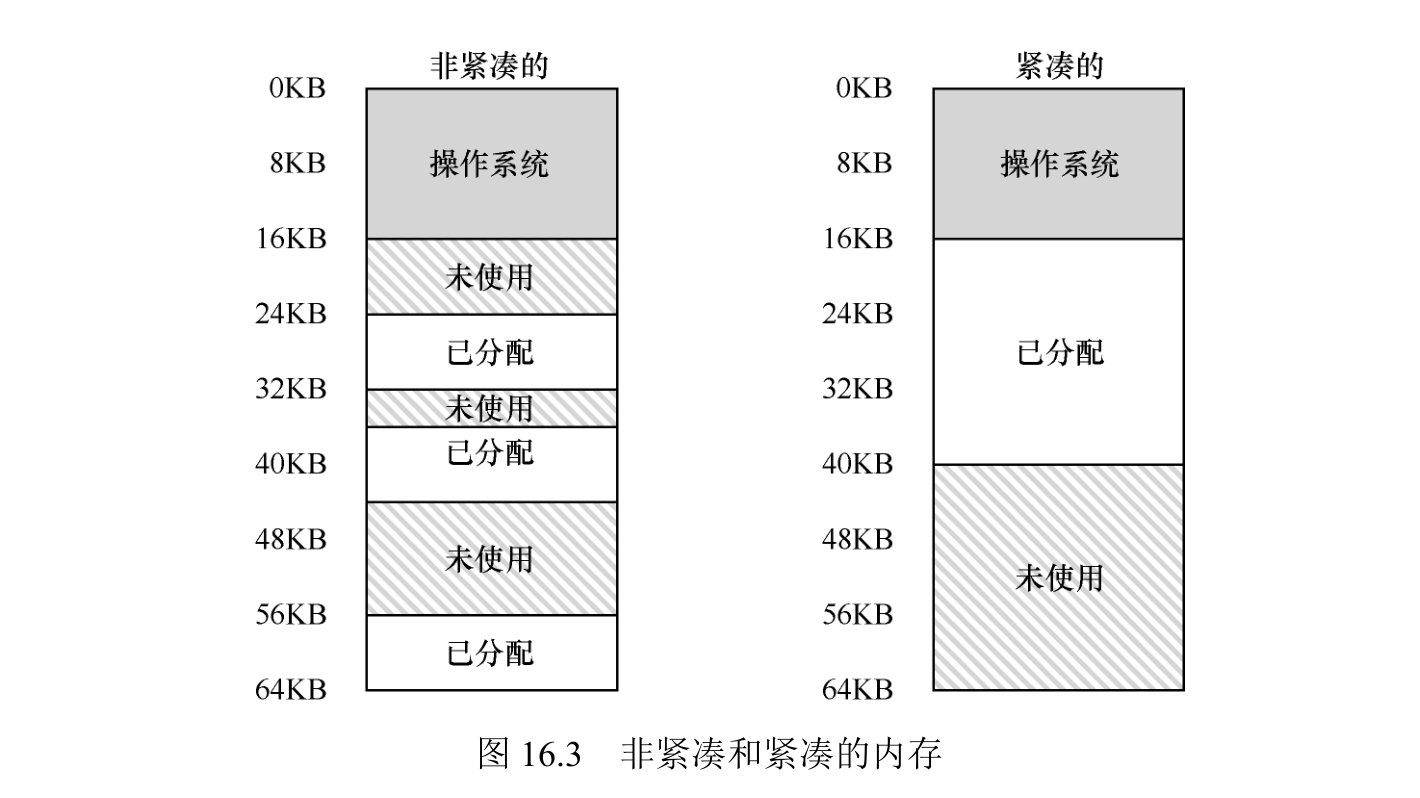
问题的一种解决方案是紧凑(compact)物理内存,重新安排原有的段。例如,操作系统先终止运行的进程,将它们的数据复制到连续的内存区域中去,改变它们的段寄存器中的值,指向新的物理地址,从而得到了足够大的连续空闲空间。这样做,操作系统能让新的内存分配请求成功。但是,内存紧凑成本很高,因为拷贝段是内存密集型的,一般会占用大量的处理器时间。
一种更简单的做法是利用空闲列表管理算法,试图保留大的内存块用于分配。相关的算法可能有成百上千种,包括传统的最优匹配(best-fit,从空闲链表中找最接近需要分配空间的空闲块返回)、最坏匹配(worst-fit)、首次匹配(first-fit)以及像伙伴算法(buddy algorithm)这样更复杂的算法。
无论算法多么精妙,都无法完全消除外部碎片
空闲空间管理
如果需要管理的空间被划分为固定大小的单元,就很容易。在这种情况下,只需要维护这些大小固定的单元的列表,如果有请求,就返回列表中的第一项。
如果要管理的空闲空间由大小不同的单元构成,管理就变得困难(而且有趣)。这种情况出现在用户级的内存分配库(如 malloc()和 free()),或者操作系统用分段(segmentation)的方式实现虚拟内存。
这两种情况下,出现了外部碎片(external fragmentation)的问题:
空闲空间被分割成不同大小的小块,成为碎片,后续的请求可能失败,因为没有一块足够大的连续空闲空间,即使这时总的空闲空间超出了请求的大小。
假设
我们假定基本的接口就像 malloc()和 free()提供的那样。
该库管理的空间由于历史原因被称为堆,在堆上管理空闲空间的数据结构通常称为空闲列表(free list)。该结构包含了管理内存区域中所有空闲块的引用。当然,该数据结构不一定真的是列表,而只是某种可以追踪空闲空间的数据结构。
进一步假设,我们主要关心的是外部碎片。
当然,分配程序也可能有内部碎片(internal fragmentation)的问题。如果分配程序给出的内存块超出请求的大小,在这种块中超出请求的空间(因此而未使用)就被认为是内部碎片(因为浪费发生在已分配单元的内部),这是另一种形式的空间浪费。
我们还假设,内存一旦被分配给客户,就不可以被重定位到其他位置。
最后我们假设,分配程序所管理的是连续的一块字节区域。
底层机制
分割与合并
空闲列表包含一组元素,记录了堆中的哪些空间还没有分配。假设有下面的 30 字节的堆:
这个堆对应的空闲列表会有两个元素,一个描述第一个 10 字节的空闲区域(字节 0~9),一个描述另一个空闲区域(字节 20~29):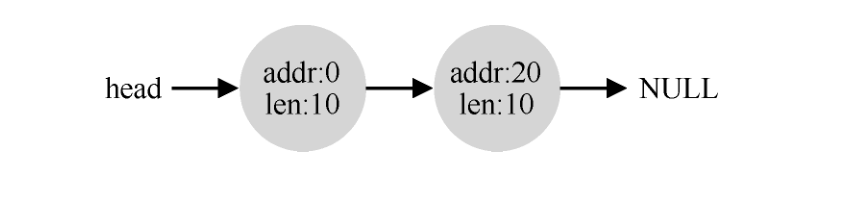
任何大于 10 字节的分配请求都会失败(返回 NULL),因为没有足够的连续可用空间。
假设我们只申请一个字节的内存。这种情况下,分配程序会执行所谓的分割(splitting)动作:它找到一块可以满足请求的空闲空间,将其分割,第一块返回给用户,第二块留在空闲列表中。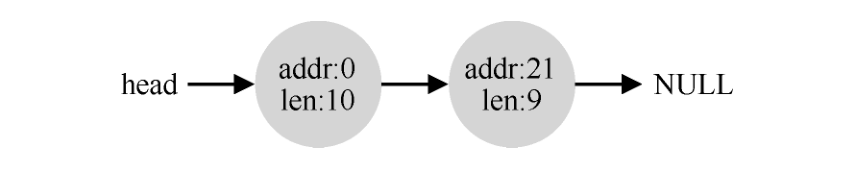
因此,如果请求的空间大小小于某块空闲块,分配程序通常会进行分割。
分配程序会在释放一块内存时合并可用空间。 在归还一块空闲内存时,仔细查看要归还的内存块的地址以及邻它的空闲空间块。如果新归还的空间与一个原有空闲块相邻(或两个,就像这个例子),就将它们合并为一个较大的空闲块。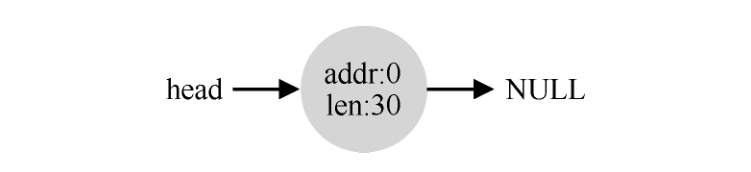
追踪已分配空间的大小
该头块中至少包含所分配空间的大小(这个例子中是 20)。它也可能包含一些额外的指针来加速空间释放,包含一个幻数来提供完整性检查,以及其他信息。
1 | typedef struct header_t { |
用户调用 free(ptr)时,库会通过简单的指针运算得到头块的位置:
1 | void free(void *ptr) { |
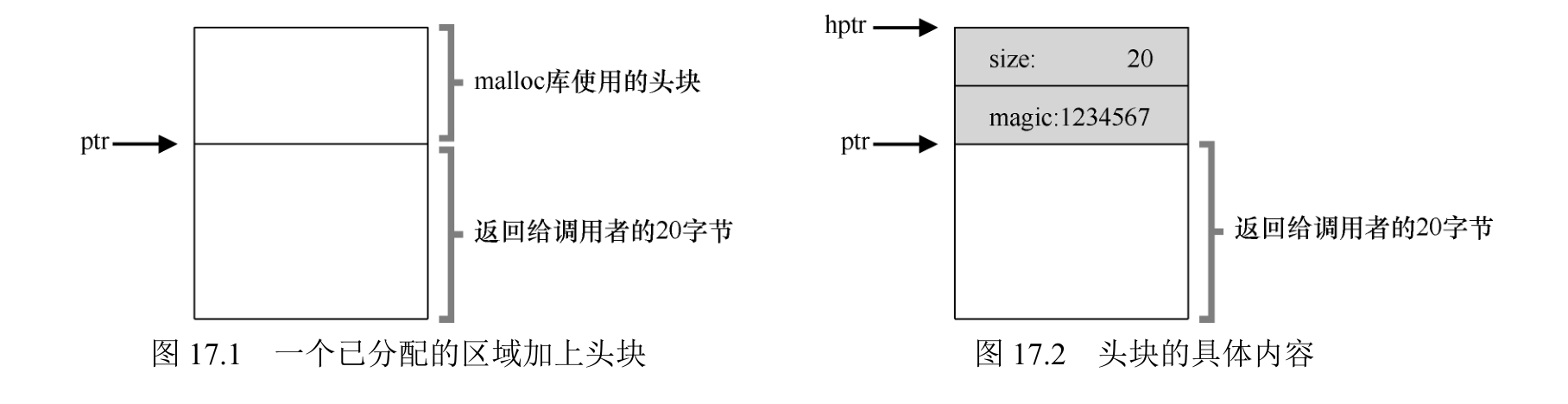
获得头块的指针后,库可以很容易地确定幻数是否符合预期的值,作为正常性检查(assert(hptr->magic == 1234567)),并简单计算要释放的空间大小(即头块的大小加区域长度)。实际释放的是头块大小加上分配给用户的空间的大小。因此,如果用户请求 N 字节的内存,库不是寻找大小为 N 的空闲块,而是寻找N 加上头块大小的空闲块。
嵌入空闲列表
假设我们需要管理一个 4096 字节的内存块(即堆是 4KB)。为了将它作为一个空闲空间列表来管理,首先要初始化这个列表。开始,列表中只有一个条目,记录了大小为 4096的空间(减去头块的大小)。
1 | typedef struct node_t { |
现在来看一些代码,它们初始化堆,并将空闲列表的第一个元素放在该空间中。这块空间通过系统调用 mmap()获得。
1 | node_t *head = mmap(NULL, 4096, PROT_READ|PROT_WRITE, |
因为只有一个 4088 字节的块,所以选中这个块。然后,这个块被分割(split)为两块:一块足够满足请求(以及头块,如前所述),一块是剩余的空闲块。假设记录头块为 8 个字节(一个整数记录大小,一个整数记录幻数),堆中的空间如图: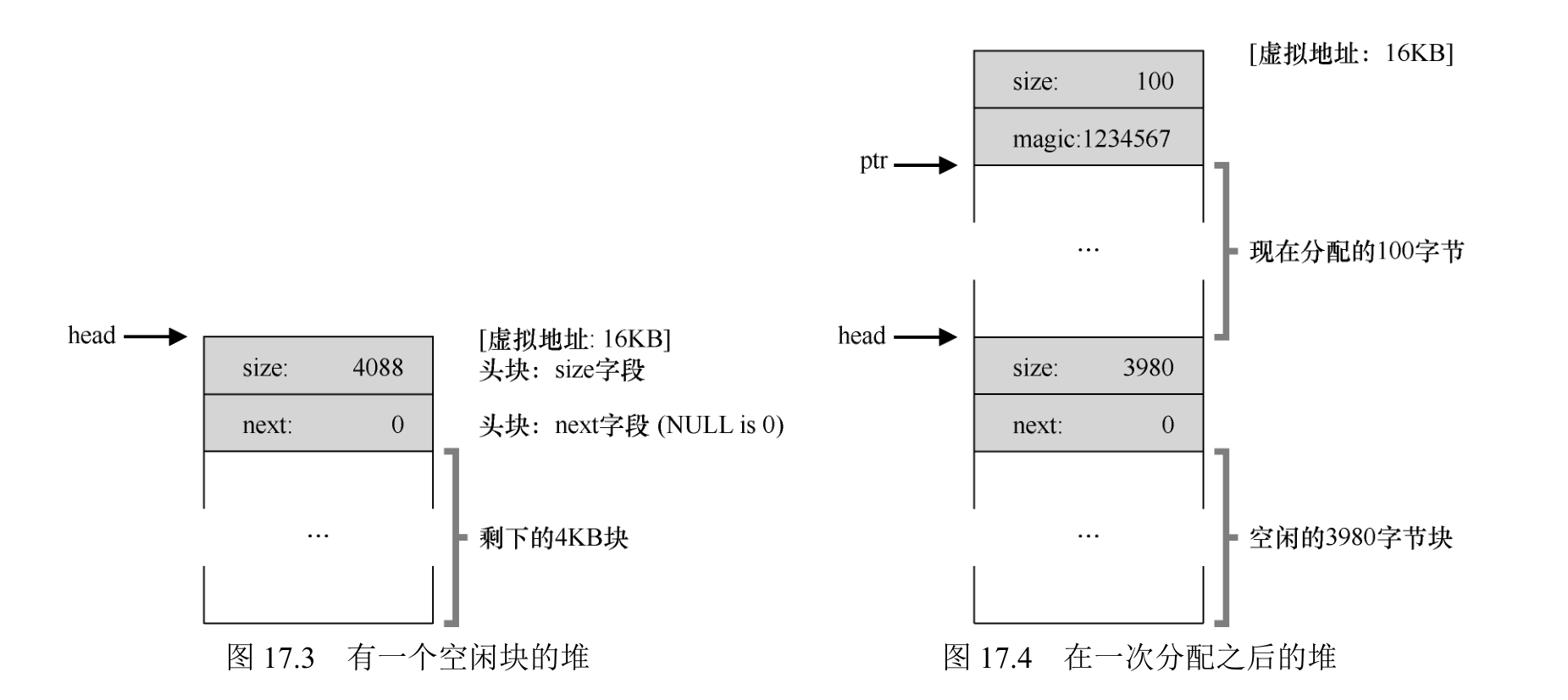
16KB等于16,384字节。
在这个例子中,应用程序调用 free(16500),归还了中间的一块已分配空间(内存块的起始地址 16384 加上前一块的 108,和这一块的头块的 8 字节,就得到了 16500)。这个值在前图中用 sptr 指向。
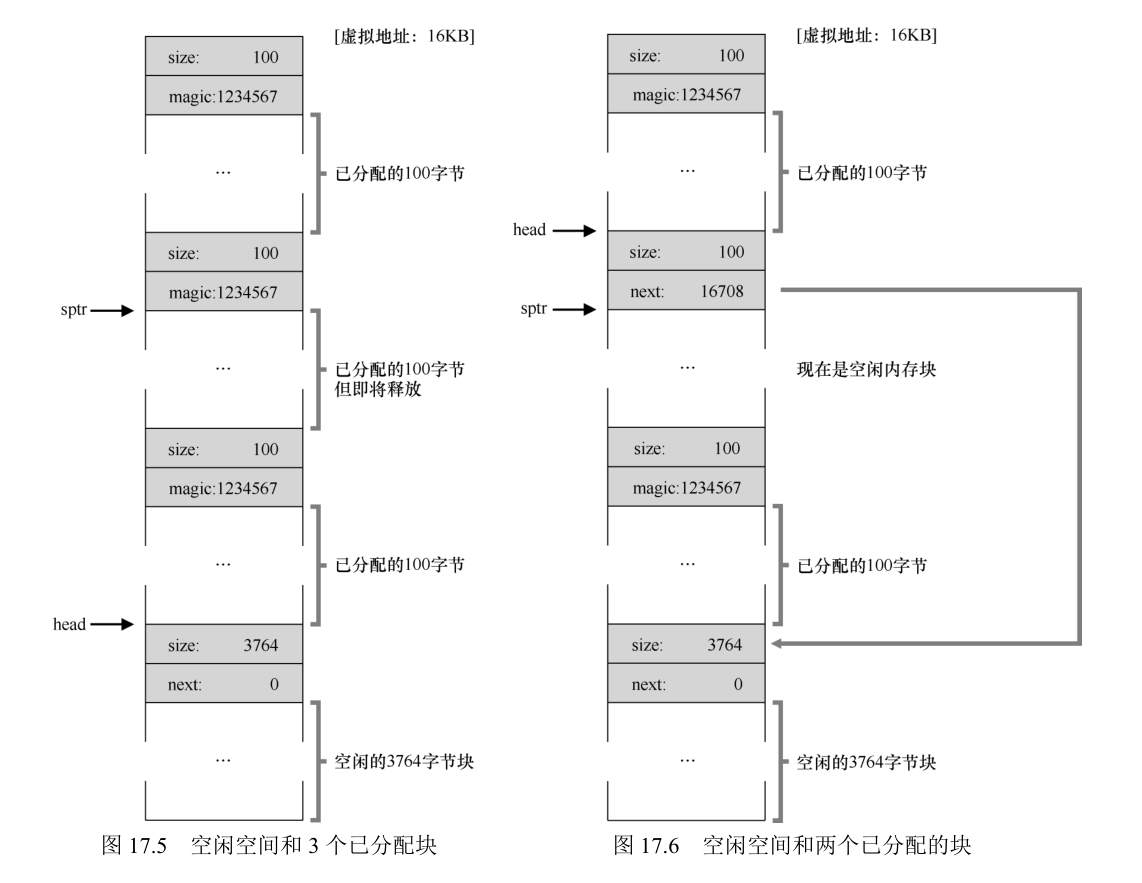
现在的空闲列表包括一个小空闲块(100 字节,由列表的头指向)和一个大空闲块(3764字节)。
最后一个例子:现在假设剩余的两块已分配的空间也被释放。没有合并,空闲列表将非常破碎,如图: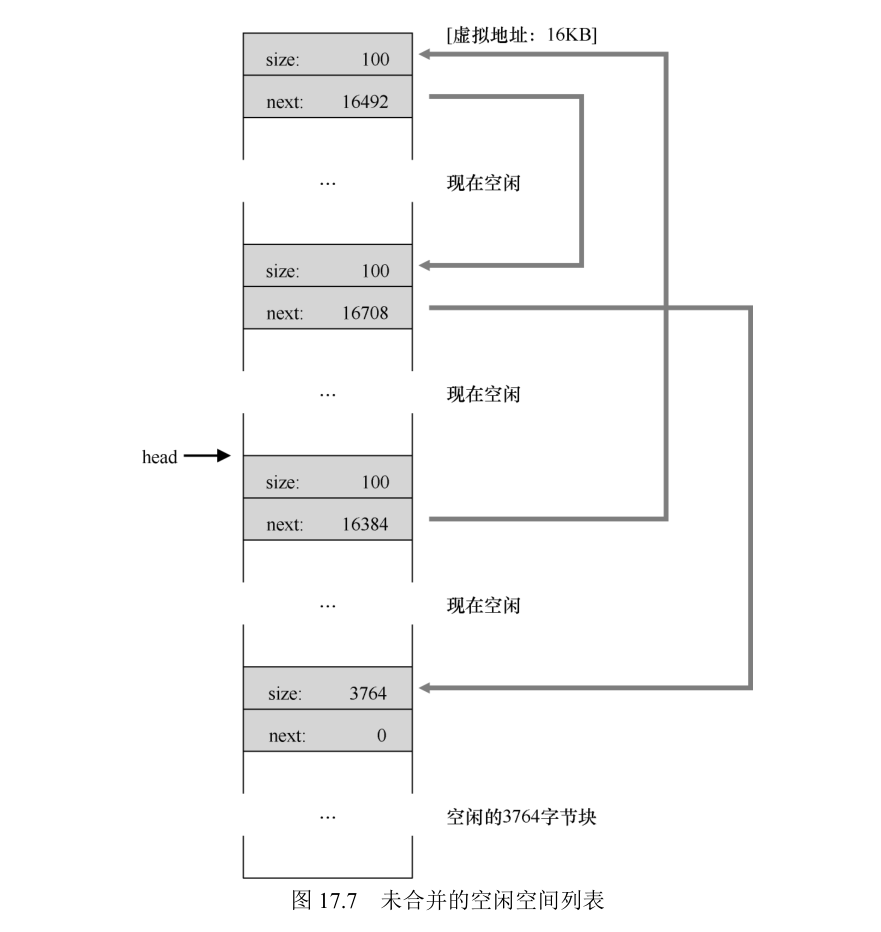
解决方案很简单:遍历列表,合并(merge)相邻块。完成之后,堆又成了一个整体。
让堆增长
大多数传统的分配程序会从很小的堆开始,当空间耗尽时,再向操作系统申请更大的空间。通常,这意味着它们进行了某种系统调用(例如,大多数 UNIX 系统中的 sbrk),让堆增长。操作系统在执行 sbrk 系统调用时,会找到空闲的物理内存页,将它们映射到请求进程的地址空间中去,并返回新的堆的末尾地址。这时,就有了更大的堆,请求就可以成功满足。
基本策略
最优匹配
首先遍历整个空闲列表,找到和请求大小一样或更大的空闲块,然后返回这组候选者中最小的一块。这就是所谓的最优匹配(也可以称为最小匹配)。只需要遍历一次空闲列表,就足以找到正确的块并返回。
最差匹配
最差匹配(worst fit)方法与最优匹配相反,它尝试找最大的空闲块,分割并满足用户需求后,将剩余的块(很大)加入空闲列表。最差匹配尝试在空闲列表中保留较大的块,而不是向最优匹配那样可能剩下很多难以利用的小块。但是,最差匹配同样需要遍历整个空闲列表。更糟糕的是,大多数研究表明它的表现非常差,导致过量的碎片,同时还有很高的开销。
首次匹配
首次匹配(first fit)策略就是找到第一个足够大的块,将请求的空间返回给用户。同样,剩余的空闲空间留给后续请求。
首次匹配有速度优势(不需要遍历所有空闲块),但有时会让空闲列表开头的部分有很多小块。因此,分配程序如何管理空闲列表的顺序就变得很重要。一种方式是基于地址排序(address-based ordering)。通过保持空闲块按内存地址有序,合并操作会很容易,从而减少了内存碎片。
下次匹配
不同于首次匹配每次都从列表的开始查找,下次匹配(next fit)算法多维护一个指针,指向上一次查找结束的位置。其想法是将对空闲空间的查找操作扩散到整个列表中去,避免对列表开头频繁的分割。这种策略的性能与首次匹配很接它,同样避免了遍历查找。
例子
设想一个空闲列表包含 3 个元素,长度依次为 10、30、20
假设有一个 15 字节的内存请求。最优匹配会遍历整个空闲列表,发现 20 字节是最优匹配,因为它是满足请求的最小空闲块。结果空闲列表变为:
本例中发生的情况,在最优匹配中常常发生,现在留下了一个小空闲块。最差匹配类似,但会选择最大的空闲块进行分割,在本例中是 30。结果空闲列表变为:
在这个例子中,首次匹配会和最差匹配一样,也发现满足请求的第一个空闲块。不同的是查找开销,最优匹配和最差匹配都需要遍历整个列表,而首次匹配只找到第一个满足需求的块即可,因此减少了查找开销。
其他方式
分离空闲列表
如果某个应用程序经常申请一种(或几种)大小的内存空间,那就用一个独立的列表,只管理这样大小的对象。其他大小的请求都一给更通用的内存分配程序。
应该拿出多少内存来专门为某种大小的请求服务,而将剩余的用来满足一般请求?
具体来说,在内核启动时,它为可能频繁请求的内核对象创建一些对象缓存(object cache),如锁和文件系统 inode 等。这些的对象缓存每个分离了特定大小的空闲列表,因此能够很快地响应内存请求和释放。如果某个缓存中的空闲空间快耗尽时,它就向通用内存分配程序申请一些内存厚块(slab)(总量是页大小和对象大小的公倍数)。相反,如果给定厚块中对象的引用计数变为 0,通用的内存分配程序可以从专门的分配程序中回收这些空间,这通常发生在虚拟内存系统需要更多的空间的时候。
伙伴系统
在这种系统中,空闲空间首先从概念上被看成大小为 2^N 的大空间。当有一个内存分配请求时,空闲空间被递归地一分为二,直到刚好可以满足请求的大小(再一分为二就无法满足)。这时,请求的块被返回给用户。
在下面的例子中,一个 64KB 大小的空闲空间被切分,以便提供 7KB 的块: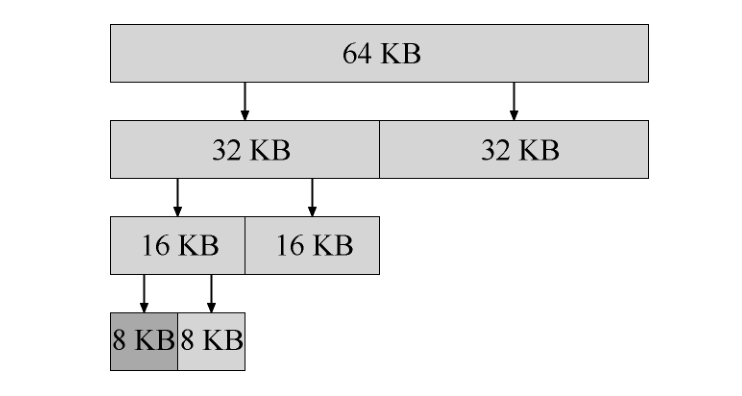
这种分配策略只允许分配2的整数次幂大小的空闲块,因此会有内部碎片(internal fragment)的麻烦。
伙伴系统的漂亮之处在于块被释放时。如果将这个 8KB 的块归还给空闲列表,分配程序会检查“伙伴”8KB 是否空闲。如果是,就合二为一,变成 16KB 的块。然后会检查这个 16KB 块的伙伴是否空闲,如果是,就合并这两块。这个递归合并过程继续上溯,直到合并整个内存区域,或者某一个块的伙伴还没有被释放。
分页:介绍
第一种是将空间分割成不同长度的分片,就像虚拟内存管理中的分段。将空间切成不同长度的分片以后,空间本身会碎片化(fragmented),随着时间推移,分配内存会变得比较困难。
第二种方法:将空间分割成固定长度的分片。在虚拟内存中,我们称
这种思想为分页,分页不是将一个进程的地址空间分割成几个不同长度的逻辑段(即代码、堆、段),而是分割成固定大小的单元,每个单元称为一页。相应地,我们把物理内存看成是定长槽块的阵列,叫作页帧(page frame)。每个这样的页帧包含一个虚拟内存页。
一个简单例子
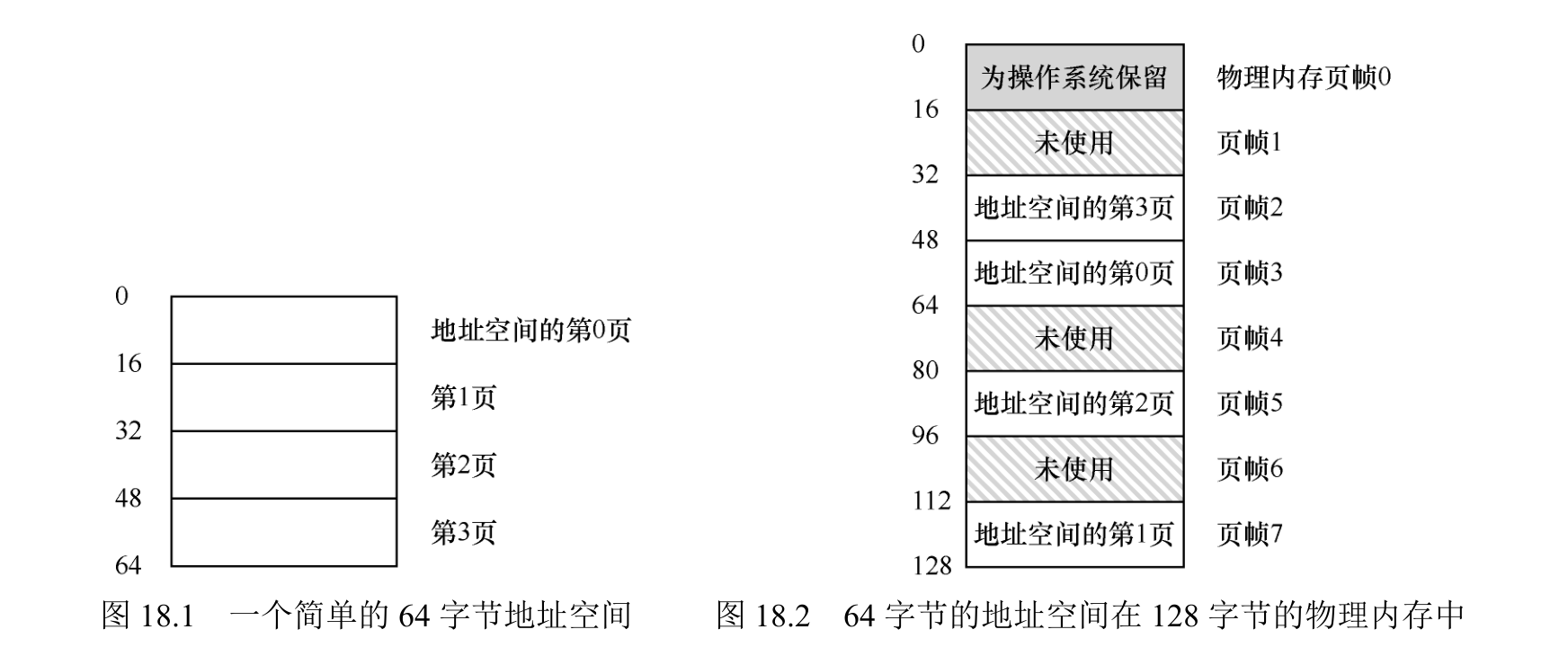
图 18.1 展示了一个只有 64字节的小地址空间,有 4 个 16 字节的页(虚拟页 0、1、2、3)。真实的地址空间肯定大得多,通常 32 位有 4GB 的地址空间,甚至有 64 位。
物理内存,如图所示,也由一组固定大小的槽块组成。在这个例子中,有 8 个页帧(由 128 字节物理内存构成,也是极小的)。从图中可以看出,虚拟地址空间的页放在物理内存的不同位置。图中还显示,操作系统自己用了一些物理内存。
通过完善的分页方法,操作系统能够高效地提供地址空间的抽象,不管进程如何使用地址空间。例如,我们不会假定堆和栈的增长方向,以及它们如何使用。
另一个优点是分页提供的空闲空间管理的简单性。
为了记录地址空间的每个虚拟页放在物理内存中的位置,操作系统通常为每个进程保存一个数据结构,称为页表(page table)。页表的主要作用是为地址空间的每个虚拟页面保存地址转换(address translation),从而让我们知道每个页在物理内存中的位置。如果在上面的示例中运行另一个进程,操作系统将不得不为它管理不同的页表,因为它的虚拟页显然映射到不同的物理页面(除了共享之外)。。
例子
设想拥有这个小地址空间(64 字节)的进程正在访问内存:
movl <virtual address>, %eax
为了转换(translate)该过程生成的虚拟地址,我们必须首先将它分成两个组件:虚拟页面号(virtual page number,VPN)和页内的偏移量(offset)。对于这个例子,因为进程的虚拟地址空间是 64 字节,我们的虚拟地址总共需要 6 位(26 = 64)。因此,虚拟地址可以表示如下:
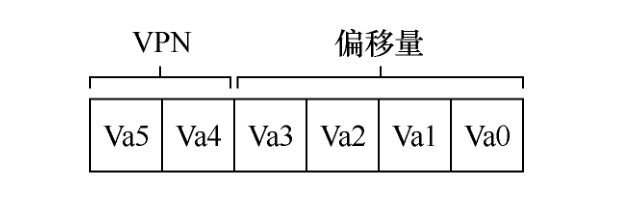
页面大小为 16 字节,位于 64 字节的地址空间。因此我们需要能够选择 4 个页,地址的前 2 位就是做这件事的。因此,我们有一个 2 位的虚拟页号(VPN)。其余的位告诉我们,感兴趣该页的哪个字节,在这个例子中是 4 位,我们称之为偏移量。
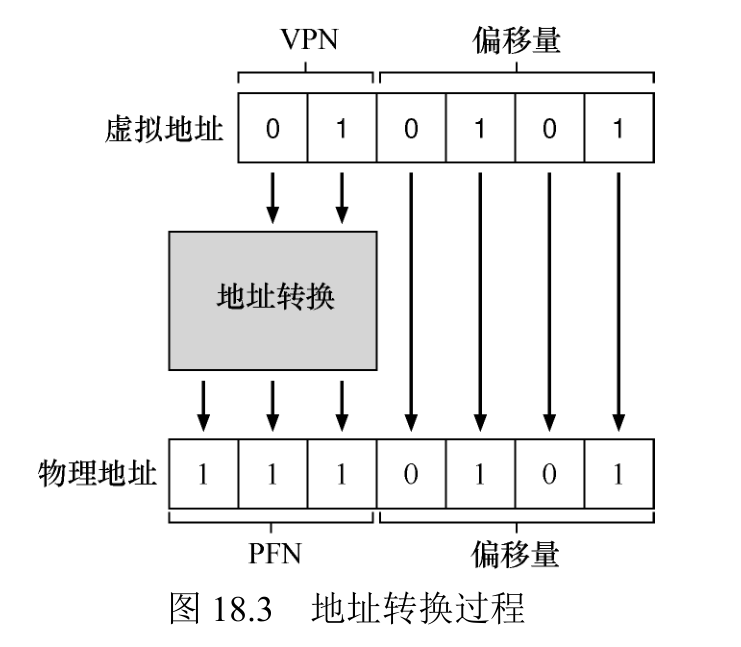
因此,我们可以通过用 PFN 替换 VPN 来转换此虚拟地址,然后将载入发送给物理内存,偏移量保持不变(即未翻译),因为偏移量只是告诉我们页面中的哪个字节是我们想要的。
页表存在哪里
由于页表如此之大,我们没有在 MMU 中利用任何特殊的片上硬件,来存储当前正在运行的进程的页表,而是将每个进程的页表存储在内存中。
列表中究竟有什么
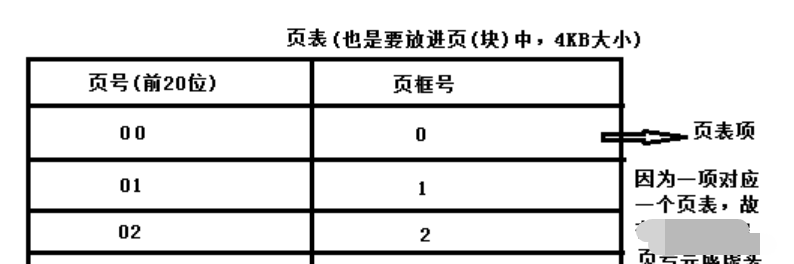
让我们来谈谈页表的组织。页表就是一种数据结构,用于将虚拟地址(或者实际上,是虚拟页号)映射到物理地址(物理帧号)。
最简单的形式称为线性页表(linear page table),就是一个数组。操作系统通过虚拟页号(VPN)检索该数组,并在该索引处查找页表项(PTE),以便找到期望的物理帧号(PFN)。
有效位(valid bit)通常用于指示特定地址转换是否有效。例如,当一个程序开始运行时,它的代码和堆在其地址空间的一端,栈在另一端。所有未使用的中间空间都将被标记为无效(invalid),如果进程尝试访问这种内存,就会陷入操作系统,可能会导致该进程终止。
我们还可能有保护位(protection bit),表明页是否可以读取、写入或执行。同样,以这些位不允许的方式访问页,会陷入操作系统。
图显示了来自 x86 架构的示例页表项。它包含一个存在位(P),确定是否允许写入该页面的读/写位(R/W) 确定用户模式进程是否可以访问该页面的用户/超级用户位(U/S),有几位(PWT、PCD、PAT 和 G)确定硬件缓存如何为这些页面工作,一个访问位(A)和一个脏位(D),最后是页帧号(PFN)本身。
内存追踪
1 | int array[1000]; |
补充:数据结构——页表
现代操作系统的内存管理子系统中最重要的数据结构之一就是页表(page table)。通常,页表存储虚拟—物理地址转换(virtual-to-physical address translation),从而让系统知道地址空间的每个页实际驻留在物理内存中的哪个位置。由于每个地址空间都需要这种转换,因此一般来说,系统中每个进程都有一个页表。页表的确切结构要么由硬件(旧系统)确定,要么由 OS(现代系统)更灵活地管理。
1 | 0x1024 movl $0x0,(%edi,%eax,4) |
第一条指令将零值(显示为$0x0)移动到数组位置的虚拟内存地址,这个地址是通过取%edi 的内容并将其加上%eax 乘以 4 来计算的。因此,%edi 保存数组的基址,而%eax 保存数组索引(i)。我们乘以 4,因为数组是一个整型数组,每个元素的大小为 4 个字节。
(%edi,%eax,4)是一种内存寻址模式,用于计算内存地址。
在这个模式中,%edi和%eax是寄存器,4是一个常数偏移量。它们的组合用于计算内存地址。
具体计算方式如下:
将%eax的值乘以4,得到偏移量。
将%edi的值加上步骤1中计算得到的偏移量,得到最终的内存地址。
第二条指令增加保存在%eax 中的数组索引
第三条指令将该寄存器的内容与十六进制值 0x03e8 或十进制数 1000 进行比较。如果比较结果显示两个值不相等(这就是 jne 指令测试)
第四条指令跳回到循环的顶部。
对于这个例子,我们假设一个大小为 64KB 的虚拟地址空间(不切实际地小)。我们还假定页面大小为 1KB。
我们现在需要知道页表的内容,以及它在物理内存中的位置。假设有一个线性(基于数组)的页表,它位于物理地址 1KB(1024)。
首先,存在代码所在的虚拟页面。由于页大小为 1KB,虚拟地址 1024 驻留在虚拟地址空间的第二页(VPN = 1,因为 VPN = 0 是第一页)。假设这个虚拟页映射到物理帧 4(VPN 1→PFN 4)。
接下来是数组本身。它的大小是 4000 字节(1000 整数),我们假设它驻留在虚拟地址40000 到 44000(不包括最后一个字节)。它的虚拟页的十进制范围是 VPN = 39……VPN =42。因此,我们需要这些页的映射。针对这个例子,让我们假设以下虚拟到物理的映射:(VPN 39 → PFN 7), (VPN 40 → PFN 8), (VPN 41 → PFN 9), (VPN 42 → PFN 10)
我们现在准备好跟踪程序的内存引用了。当它运行时,每个获取指将产生两个内存引用:一个访问页表以查找指令所在的物理框架,另一个访问指令本身将其提取到 CPU 进行处理。另外,在 mov 指令的形式中,有一个显式的内存引用,这会首先增加另一个页表访问(将数组虚拟地址转换为正确的物理地址),然后时数组访问本身。
作为虚拟内存挑战的解决方案。与以前的方法(如分段)相比,分页有许多优点。首先,它不会导致外部碎片,因为分页(按设计)将内存划分为固定大小的单元。其次,它非常灵活,支持稀疏虚拟地址空间。
分页:快速地址转换 (TLB)
使用分页作为核心机制来实现虚拟内存,可能会带来较高的性能开销。因为要使用分页,就要将内存地址空间切分成大量固定大小的单元(页),并且需要记录这些单元的地址映射信息。因为这些映射信息一般存储在物理内存中,所以在转换虚拟地址时,分页逻辑上需要一次额外的内存访问。每次指令获取、显式加载或保存,都要额外读一次内存以得到转换信息,这慢得无法接受。
我们要增加所谓的地址转换旁路缓冲存储器(translation-lookaside buffer,TLB,它就是频繁发生的虚拟到物理地址转换的硬件缓存(cache)。因此,更好的名称应该是地址转换缓存(address-translation cache)。对每次内存访问,硬件先检查 TLB,看看其中是否有期望的转换映射,如果有,就完成转换(很快),不用访问页表(其中有全部的转换映射)。
TLB(Translation Lookaside Buffer)是一个高速缓存,用于加速虚拟地址到物理地址的转换
TLB 的基本算法
1 | //首先从虚拟地址中提取页号(VPN) |
示例:访问数组
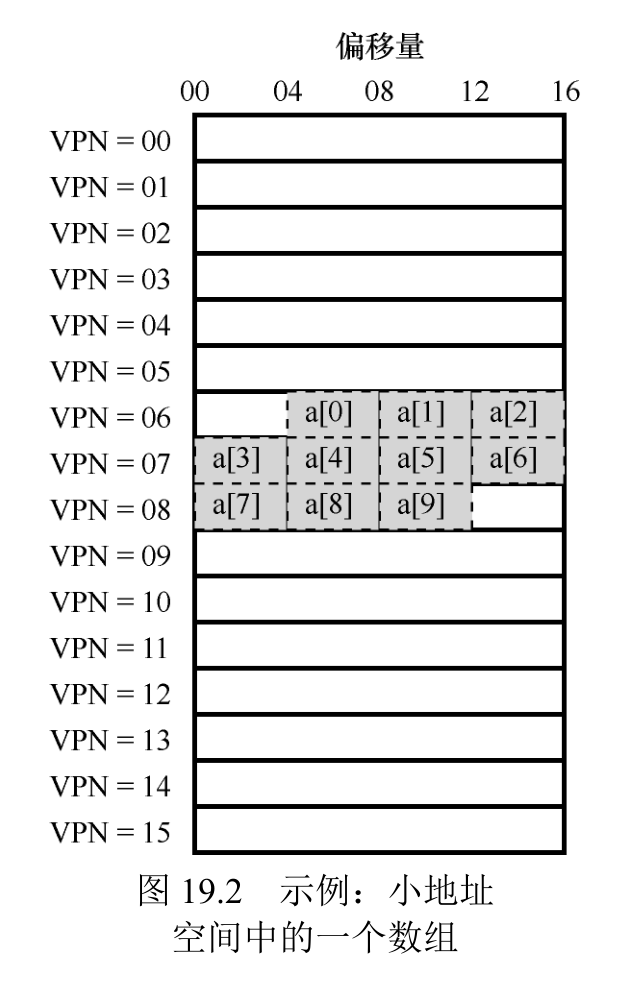
假设有一个由 10 个 4 字节整型数组成的数组,起始虚地址是 100。进一步假定,有一个 8 位的小虚地址空间,页大小为 16B。我们可以把虚地址划分为 4 位的 VPN(有 16 个虚拟内存页)和 4 位的偏移量(每个页中有 16 个字节)。
现在考虑一个简单的循环,访问数组中的每个元素:
1 | int sum = 0; |
- 简单起见,我们假装循环产生的内存访问只是针对数组(忽略变量 i 和 sum,以及指令本身)。当访问第一个数组元素(a[0])时,CPU 会看到载入虚存地址 100。硬件从中提取VPN(VPN=06),然后用它来检查 TLB,寻找有效的转换映射。假设这里是程序第一次访问该数组,结果是 TLB 未命中。
- 接下来访问 a[1],这里有好消息:TLB 命中!因为数组的第二个元素在第一个元素之后,它们在同一页。因为我们之前访问数组的第一个元素时,已经访问了这一页,所以 TLB中缓存了该页的转换映射。因此成功命中。访问 a[2]同样成功(再次命中),因为它和 a[0]、a[1]位于同一页。
- 遗憾的是,当程序访问 a[3]时,会导致 TLB 未命中。但同样,接下来几项(a[4] … a[6])都会命中 TLB,因为它们位于内存中的同一页。
- 最后,访问 a[7]会导致最后一次 TLB 未命中。系统会再次查找页表,弄清楚这个虚拟页在物理内存中的位置,并相应地更新 TLB。最后两次访问(a[8]、a[9])受益于这次 TLB更新,当硬件在 TLB 中查找它们的转换映射时,两次都命中。
TLB 还是提高了性能。数组的元素被紧密存放在几页中(即它们在空间中紧密相邻),因此只有对页中第一个元素的访问才会导致 TLB 未命中。
提示:尽可能利用缓存
缓存是计算机系统中最基本的性能改进技术之一,一次又一次地用于让“常见的情况更快”。
硬件缓存背后的思想是利用指令和数据引用的局部性(locality)。通常有两种局部性:时间局部性(temporal locality)和空间局部性(spatial locality)。
时间局部性是指,最近访问过的指令或数据项可能很快会再次访问。想想循环中的循环变量或指令,它们被多次反复访问。
空间局部性是指,当程序访问内存地址 x 时,可能很快会访问邻近 x 的内存。想想遍历某种数组,访问一个接一个的元素。当然,这些性质取决于程序的特点,并不是绝对的定律,而更像是一种经验法则。
硬件缓存,无论是指令、数据还是地址转换(如 TLB),都利用了局部性,在小而快的芯片内存储器中保存一份内存副本。处理器可以先检查缓存中是否存在就近的副本,而不是必须访问(缓慢的)内存来满足请求。如果存在,处理器就可以很快地访问它(例如在几个 CPU 时钟内),避免花很多时间来访问内存(好多纳秒)。
你可能会疑惑:既然像 TLB 这样的缓存这么好,为什么不做更大的缓存,装下所有的数据?
可惜的是,这里我们遇到了更基本的定律,就像物理定律那样。如果想要快速地缓存,它就必须小,因为光速和其他物理限制会起作用。大的缓存注定慢,因此无法实现目的。所以,我们只能用小而快的缓存。剩下的问题就是如何利用好缓存来提升性能。
谁来处理 TLB 未命中
以前的硬件有复杂的指令集(有时称为复杂指令集计算机,Complex-Instruction Set Computer,CISC),造硬件的人不太相信那些搞操作系统的人。因此,硬件全权处理 TLB未命中。为了做到这一点,硬件必须知道页表在内存中的确切位置(通过页表基址寄存器,page-table base register),以及页表的确切格式。发生未命中时,硬件会“遍历”页表,找到正确的页表项,取出想要的转换映射,用它更新 TLB,并重试该指令。
这种“旧”体系结构有硬件管理的 TLB,一个例子是 x86 架构,它采用固定的多级页表(multi-level page table),当前页表由 CR3 寄存器指出。
更现代的体系结构(例如,MIPS R10k[H93]、Sun 公司的 SPARC v9,都是精简指令集计算机,Reduced-Instruction Set Computer,RISC),有所谓的软件管理 TLB(software-managed TLB)。发生 TLB 未命中时,硬件系统会抛出一个异常,这会暂停当前的指令流,将特权级提升至内核模式,跳转至陷阱处理程序(trap handler)。接下来你可能已经猜到了,这个陷阱处理程序是操作系统的一段代码,用于处理 TLB 未命中。这段代码在运行时,会查找页表中的转换映射,然后用特别的“特权”指令更新 TLB,并从陷阱返回。此时,硬件会重试该指令(导致 TLB 命中)。
首先,这里的从陷阱返回指令稍稍不同于之前提到的服务于系统调用的从陷阱返回。在后一种情况下,从陷阱返回应该继续执行陷入操作系统之后那条指令,就像从函数调用返回后,会继续执行此次调用之后的语句。在前一种情况下,在从 TLB 未命中的陷阱返回后,硬件必须从导致陷阱的指令继续执行。这次重试因此导致该指令再次执行,但这次会命中 TLB。因此,根据陷阱或异常的原因,系统在陷入内核时必须保存不同的程序计数器,以便将来能够正确地继续执行。
第二,在运行 TLB 未命中处理代码时,操作系统需要格外小心避免引起 TLB 未命中的无限递归。有很多解决方案,例如,可以把 TLB 未命中陷阱处理程序直接放到物理内存中 [它们没有映射过(unmapped),不用经过地址转换]。或者在 TLB 中保留一些项,记录永久有效的地址转换,并将其中一些永久地址转换槽块留给处理代码本身,这些被监听的(wired)地址转换总是会命中 TLB。
软件管理的方法,主要优势是灵活性:操作系统可以用任意数据结构来实现页表,不需要改变硬件。另一个优势是简单性。从 TLB 控制流中可以看出,硬件不需要对未命中做太多工作,它抛出异常,操作系统的未命中处理程序会负责剩下的工作。
TLB 的内容
典型的 TLB 有 32 项、64 项或 128 项,并且是全相联的(fully associative)。基本上,这就意味着一条地址映射可能存在 TLB 中的任意位置,硬件会并行地查找 TLB,找到期望的转换映射。
VPN | PFN | 其他位
补充:TLB 的有效位!=页表的有效位
常见的错误是混淆 TLB 的有效位和页表的有效位。在页表中,如果一个页表项(PTE)被标记为无效,就意味着该页并没有被进程申请使用,正常运行的程序不应该访问该地址。当程序试图访问这样的页时,就会陷入操作系统,操作系统会杀掉该进程。
TLB 的有效位不同,只是指出 TLB 项是不是有效的地址映射。例如,系统启动时,所有的 TLB 项通常被初始化为无效状态,因为还没有地址转换映射被缓存在这里。一旦启用虚拟内存,当程序开始运行,访问自己的虚拟地址,TLB 就会慢慢地被填满,因此有效的项很快会充满 TLB。
上下文切换时对 TLB 的处理
TLB 中包含的虚拟到物理的地址映射只对当前进程有效,对其他进程是没有意义的。所以在发生进程切换时,硬件或操作系统(或二者)必须注意确保即将运行的进程不要误读了之前进程的地址映射。
假设有两个进程,都有虚拟页10,但是对应的物理页面不同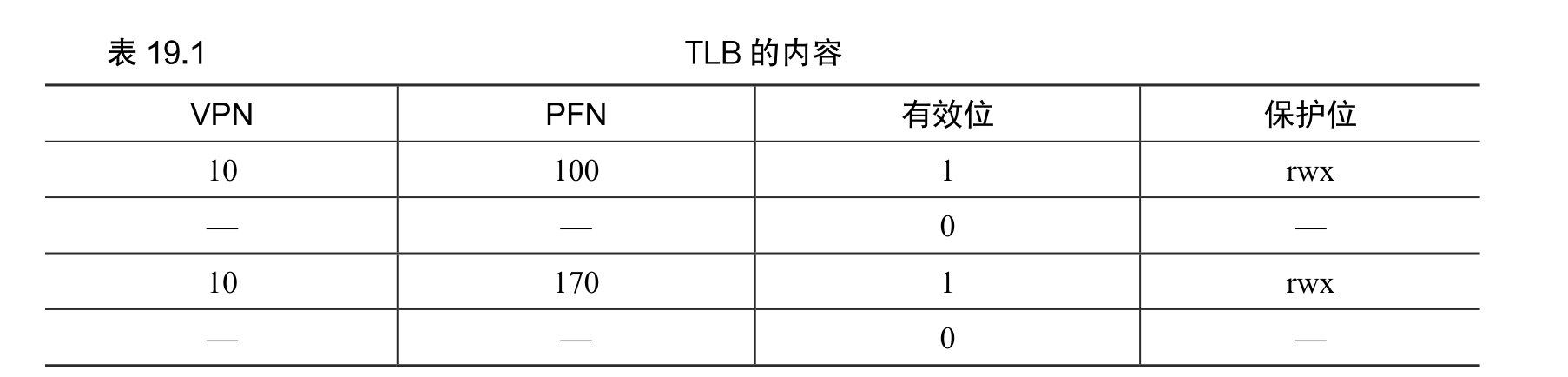
我们还需要做一些工作,让 TLB 正确而高效地支持跨多进程的虚拟化。
一种方法是在上下文切换时,简单地清空(flush)TLB,这样在新进程运行前 TLB 就变成了空的。如果是软件管理 TLB 的系统,可以在发生上下文切换时,通过一条显式(特权)指令来完成。
如果是硬件管理 TLB,则可以在页表基址寄存器内容发生变化时清空 TLB(注意,在上下文切换时,操作系统必须改变页表基址寄存器(PTBR)的值)。不论哪种情况,清空操作都是把全部有效位(valid)置为 0,本质上清空了 TLB。
但是,有一定开销:每次进程运行,当它访问数据和代码页时,都会触发 TLB 未命中。如果操作系统频繁地切换进程,这种开销会很高。
为了减少这种开销,一些系统增加了硬件支持,实现跨上下文切换的 TLB 共享。比如有的系统在 TLB 中添加了一个地址空间标识符(Address Space Identifier,ASID)。可以把ASID 看作是进程标识符(Process Identifier,PID),但通常比 PID 位数少(PID 一般 32 位,ASID 一般是 8 位)。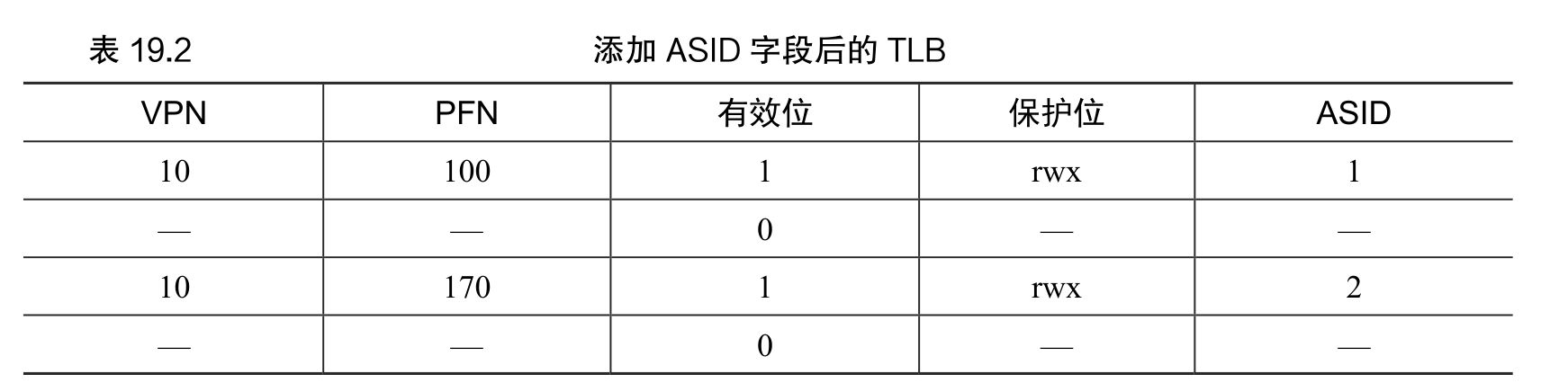
因此,有了地址空间标识符,TLB 可以同时缓存不同进程的地址空间映射,没有任何冲突。当然,硬件也需要知道当前是哪个进程正在运行,以便进行地址转换,因此操作系统在上下文切换时,必须将某个特权寄存器设置为当前进程的 ASID。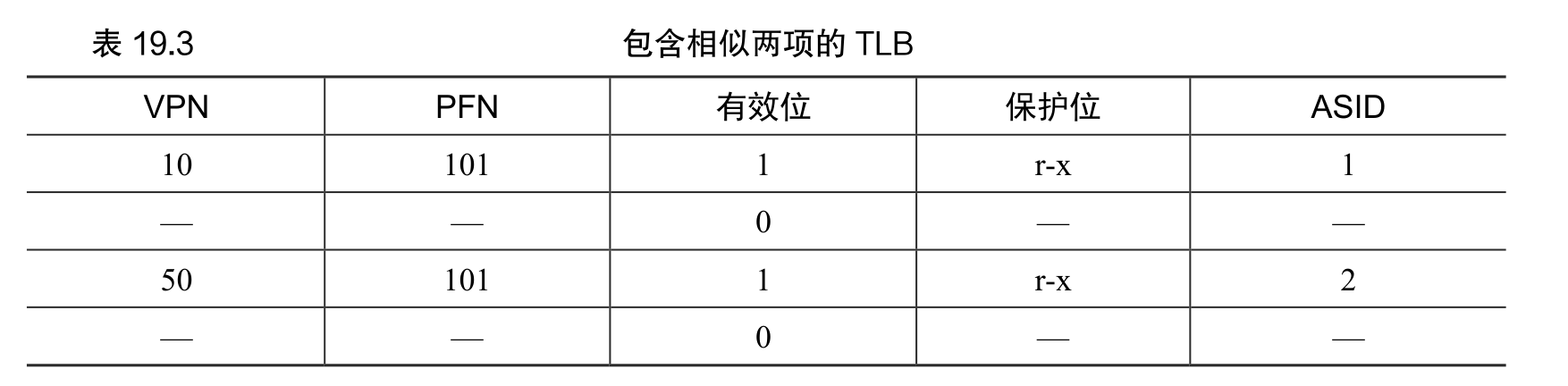
如果两个进程共享同一物理页(例如代码段的页),就可能出现这种情况。
实际系统的 TLB 表项

MIPS R4000 支持 32 位的地址空间,页大小为 4KB。所以在典型的虚拟地址中,预期会看到 20 位的 VPN 和 12 位的偏移量。但是,你可以在 TLB 中看到,只有 19 位的 VPN。事实上,用户地址只占地址空间的一半(剩下的留给内核),所以只需要 19 位的 VPN。VPN转换成最大 24 位的物理帧号(PFN),因此可以支持最多有 64GB 物理内存(224 个 4KB 内存页)的系统。
MIPS TLB 还有一些有趣的标识位。比如全局位(Global,G),用来指示这个页是不是所有进程全局共享的。因此,如果全局位置为 1,就会忽略 ASID。我们也看到了 8 位的 ASID,操作系统用它来区分进程空间(像上面介绍的一样)。
页、页表、页表项、偏移量、虚拟页号
假设一个 32 位地址空间(2^32 字节),4KB大小(2^12 字节)的页和4 字节大小的页表项。一个地址空间中大约有一百万个虚拟页面(2^32/2^12)。乘以页表项的大小,你会发现页表大小为 4MB。
页表中的每一项是页表项,每一个页表项对应一页.
在每个页中,他的大小要对应偏移量的位数,因为偏移量要能定位到页面中的每一处
vpn虚拟页号有很多个,他需要和页表项数量相同,一一对应
页的大小—偏移量
页的数量—页表项数—虚拟页号数量
页是虚拟内存和物理内存划分的最小单位,通常是固定大小的内存块,常见的大小是4KB或者2MB。虚拟地址空间被划分为多个页,每个页都有一个唯一的标识符,也称为虚拟页号。
页表是一个数据结构,用于管理虚拟内存中的页。它存储了每个虚拟页号与其对应的物理页框地址的映射关系。页表通常是一个二维数组,其中每个元素对应一个虚拟页号,并存储了与之对应的物理页框地址。
分页:更小的表
记住目的:他想要更小的页表❗❗❗
假设一个 32 位地址空间(2^32 字节),4KB大小(2^12 字节)的页和4 字节大小的页表项。一个地址空间中大约有一百万个虚拟页面(2^32/2^12)。乘以页表项的大小,你会发现页表大小为 4MB。
简单的解决方案:更大的页
再以 32 位地址空间为例,但这次假设用 16KB (2^14)的页。因此,会有 18 位的 VPN 加上 14 位的偏移量。假设每个页表项(4字节)的大小相同,现在线性页表中有 2^18 个项,因此每个页表的总大小为 1MB,页表缩到四分之一。
然而,大内存页会导致每页内的浪费,这被称为内部碎片(internal fragmentation)问题(因为浪费在分配单元内部)。因此,结果是应用程序会分配页,但只用每页的一小部分,而内存很快就会充满这些过大的页。因此,大多数系统在常见的情况下使用相对较小的页大小:4KB(如 x86)或 8KB(如 SPARCv9)。
混合方法:分页和分段
我们的杂合方法不是为进程的整个地址空间提供单个页表(不然中间有很多没用到的无效项,白白占空间),而是为每个逻辑分段提供一个。我们可能有 3 个页表,地址空间的代码、堆和栈部分各有一个。
假设 32 位虚拟地址空间包含 4KB 页面,并且地址空间分为 4 个段。在这个例子中,我们只使用 3 个段:一个用于代码,另一个用于堆,还有一个用于栈。
要确定地址引用哪个段,我们会用地址空间的前两位。假设 00 是未使用的段,01 是代码段,10 是堆段,11 是栈段。

在硬件中,假设有 3 个基本/界限对,代码、堆和栈各一个。在上下文切换时,必须更改这些寄存器,以反映新运行进程的页表的位置。
在 TLB 未命中时(假设硬件管理的 TLB,即硬件负责处理 TLB 未命中),硬件使用分段位(SN)来确定要用哪个基址和界限对。然后硬件将其中的物理地址与 VPN 结合起来,形成页表项(PTE)的地址:
1 | SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT |
杂合方案的关键区别在于,每个分段都有界限寄存器,每个界限寄存器保存了段中最大有效页的值。例如,如果代码段使用它的前 3 个页(0、1 和 2),则代码段页表将只有 3个项分配给它,并且界限寄存器将被设置为 3。内存访问超出段的末尾将产生一个异常,并可能导致进程终止。
栈和堆之间未分配的页不再占用页表中的空间(仅将其标记为无效)。(页表中有一项记忆该项是否有效)
记住目的:他想要更小的页表❗❗❗
多级页表
另一种方法并不依赖于分段,但也试图解决相同的问题:如何去掉页表中的所有无效区域,而不是将它们全部保留在内存中? 我们将这种方法称为多级页表(multi-level page table),因为它将线性页表变成了类似树的东西。这种方法非常有效,许多现代系统都用它(例如 x86 )。
多级页表的基本思想很简单。首先,将页表分成页大小的单元。然后,如果整页的页表项(PTE)无效,就完全不分配该页的页表。为了追踪页表的页是否有效(以及如果有效,它在内存中的位置),使用了名为页目录(page directory)的新结构。页目录因此可以告诉你页表的页在哪里,或者页表的整个页不包含有效页。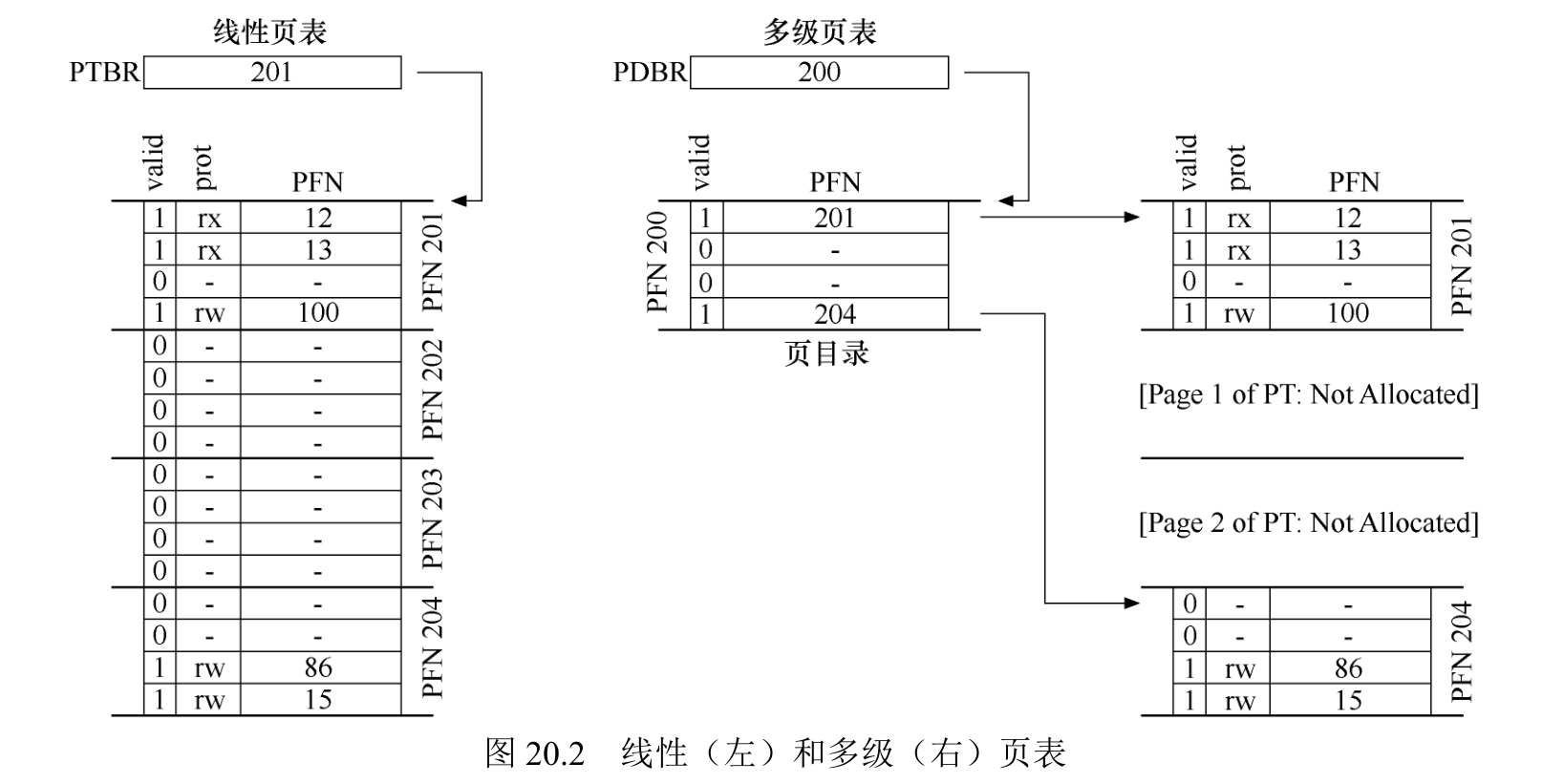
理解时空折中
在构建数据结构时,应始终考虑时间和空间的折中(time-space trade-off)。通常,如果你希望更快地访问特定的数据结构,就必须为该结构付出空间的代价。
应该指出,多级页表是有成本的。在 TLB 未命中时,需要从内存加载两次,才能从页表中获取正确的地址转换信息(一次用于页目录,另一次用于 PTE 本身),而用线性页表只需要一次加载。
在多级表的情况下,为了节省宝贵的内存,我们使页表查找更加复杂。
详细的多级示例
设想一个大小为 16KB 的小地址空间,其中包含 64 个字节的页。因此,我们有一个 14 位的虚拟地址空间,VPN 有 8位,偏移量有 6 位。即使只有一小部分地址空间正在使用,线性页表也会有 28(256)个项。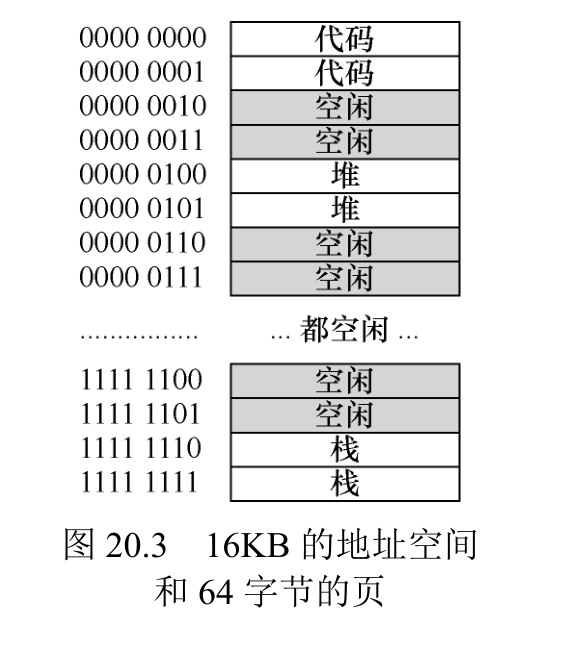
在这个例子中,虚拟页 0 和 1 用于代码,虚拟页 4 和 5 用于堆,虚拟页 254 和 255 用于栈。地址空间的其余页未被使用。
要为这个地址空间构建一个两级页表,我们从完整的线性页表开始,将它分解成页大小的单元。回想一下我们的完整页表(在这个例子中)有 256 个项;假设每个 PTE 的大小是 4个字节。因此,我们的页表大小为 1KB(256×4 字节)。鉴于我们有 64 字节的页,1KB 页表可以分为 16 个 64 字节的页,每个页可以容纳 16 个 PTE。
我们首先索引到页目录。这个例子中的页表很小:256 个项,分布在 16 个页上。页目录需要为页表的每页提供一个项。因此,它有 16 个项。结果,我们需要 4 位 VPN 来索引目录。我们使用 VPN 的前 4 位,如下所示:
一旦从 VPN 中提取了页目录索引(简称 PDIndex),我们就可以通过简单的计算来找到页目录项(PDE)的地址:PDEAddr = PageDirBase +(PDIndex×sizeof(PDE))。这就得到了页目录,现在我们来看它,在地址转换上取得进一步进展。
如果页目录项标记为无效,则我们知道访问无效,从而引发异常。但是,如果 PDE 有效,我们还有更多工作要做。具体来说,我们现在必须从页目录项指向的页表的页中获取页表项(PTE)。要找到这个 PTE,我们必须使用 VPN 的剩余位索引到页表的部分: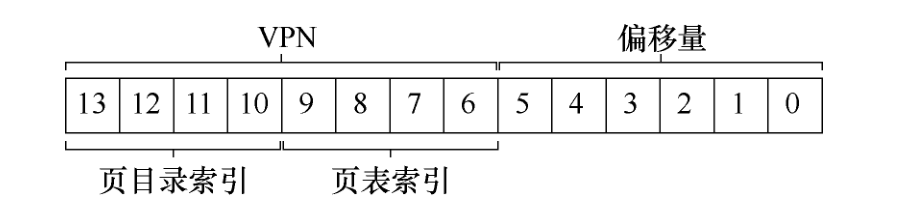
这个页表索引(Page-Table Index,PTIndex)可以用来索引页表本身,给出 PTE 的地址:
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
请注意,从页目录项获得的页帧号(PFN)必须左移到位,然后再与页表索引组合,才能形成 PTE 的地址。
在物理页 100(页表的第 0 页的物理帧号)中,我们有 1 页,包含 16 个页表项,记录了地址空间中的前 16 个 VPN。请参见表 20.2(中间部分)。
页表的另一个有效页在 PFN 101 中。该页包含地址空间的最后 16 个 VPN 的映射。具体见表 20.2(右侧)。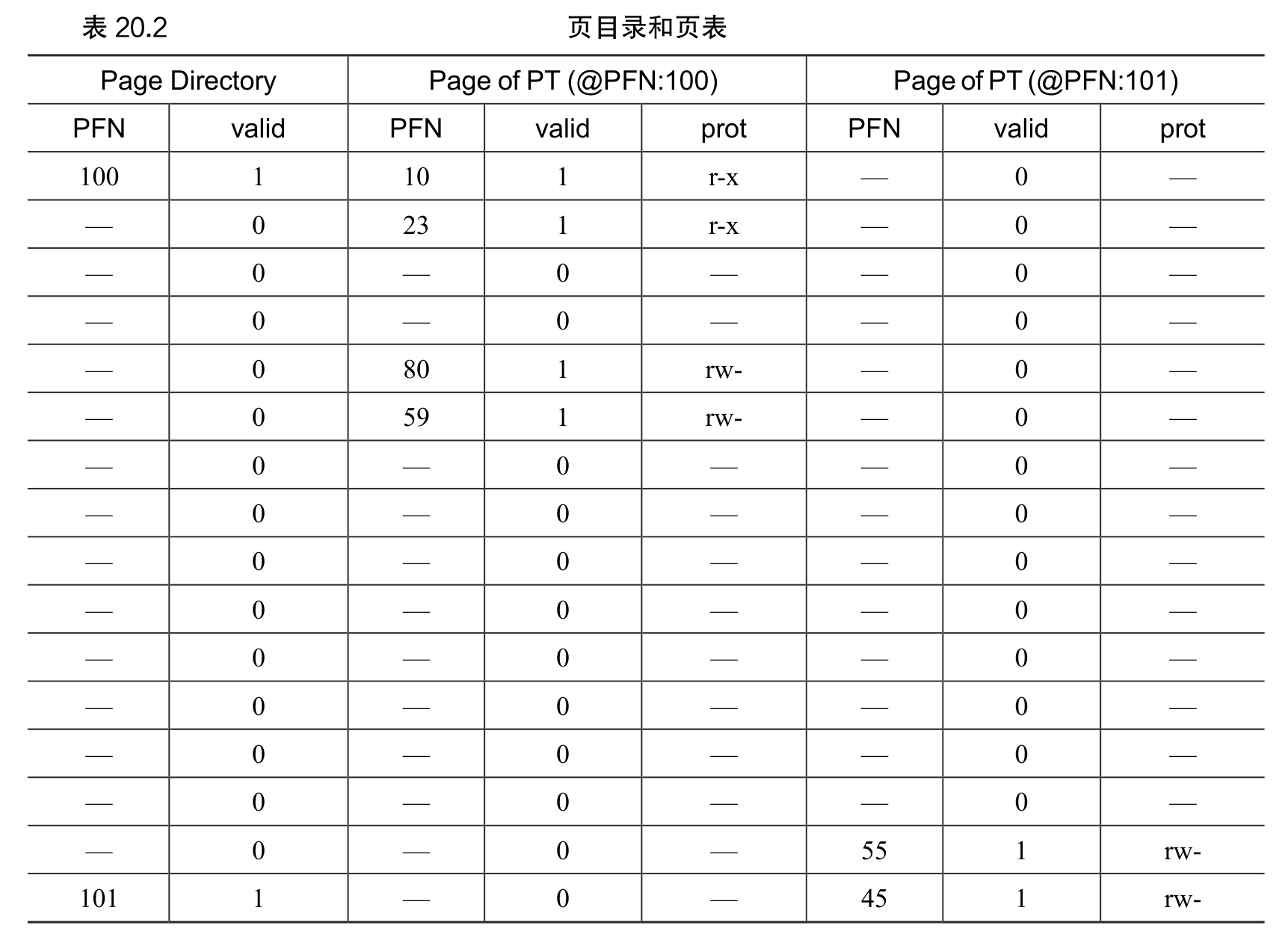
在这个例子中,我们不是为一个线性页表分配完整的 16页,而是分配 3 页:一个用于页目录,两个用于页表的具有有效映射的块。
实例
最后,让我们用这些信息来进行地址转换。这里是一个地址,指向 VPN 254 的第 0 个字节:0x3F80,或二进制的 11 1111 1000 0000。
我们将使用 VPN 的前 4 位来索引页目录。因此,1111 会从上面的页目录中选择最后一个(第 15 个,如果你从第 0 个开始)。这就指向了位于地址 101 的页表的有效页。然后,我们使用 VPN 的下 4 位(1110)来索引页表的那一页并找到所需的 PTE。1110 是页面中的倒数第二(第 14 个)条,并告诉我们虚拟地址空间的页 254 映射到物理页 55。通过连接 PFN = 55(或十六进制 0x37)和 offset = 000000,可以形成我们想要的物理地址,并向内存系统发出请求:PhysAddr =(PTE.PFN << SHIFT)+ offset = 00 1101 1100 0000 = 0x0DC0。
超过两级
在至今为止的例子中,我们假定多级页表只有两个级别:一个页目录和几页页表。在某些情况下,更深的树是可能的。
假设我们有一个 30 位的虚拟地址空间和一个小的(512 字节)页。因此我们的虚拟地址有一个 21 位的虚拟页号和一个 9 位偏移量。
构建多级页表的目标:使页表的每一部分都能放入一个页。到目前为止,
我们只考虑了页表本身。但是,如果页目录太大,该怎么办?
首先要确定多少页表项可以放入一页。鉴于页大小为 512 字节,并且假设 PTE 大小为 4 字节,你应该看到,可以在单个页上放入 128 个 PTE。当我们索引页表时,我们可以得出结论,我们需要 VPN的最低有效位 7 位(log2128)作为索引:
如果我们的页目录有 214个项,那么它不是一个页,而是 128 个,因此我们让多级页表的每一个部分放入一页目标失败了。
为了解决这个问题,我们为树再加一层,将页目录本身拆成多个页,然后在其上添加另一个页目录,指向页目录的页。我们可以按如下方式分割虚拟地址:
现在,当索引上层页目录时,我们使用虚拟地址的最高几位(图中的 PD 索引 0)。该索引用于从顶级页目录中获取页目录项。如果有效,则通过组合来自顶级 PDE 的物理帧号和 VPN 的下一部分(PD 索引 1)来查阅页目录的第二级。最后,如果有效,则可以通过使用与第二级 PDE 的地址组合的页表索引来形成 PTE 地址。
地址转换过程:记住 TLB
在任何复杂的多级页表访问发生之前,硬件首先检查 TLB。在命中时,物理地址直接形成,而不像之前一样访问页表。只有在 TLB 未命中时,硬件才需要执行完整的多级查找。
1 | VPN = (VirtualAddress & VPN_MASK) >> SHIFT |
反向页表
在反向页表(inverted page table)中,可以看到页表世界中更极端的空间节省。在反向页表中,只保留了一个全局的页表。这个全局页表中的每一项代表系统的一个物理页,而不是一个进程的内存映射。每个页表项包含了两个重要的信息:哪个进程正在使用该物理页,以及该进程的哪个虚拟页映射到该物理页。
现在,要找到正确的项,就是要搜索这个数据结构。线性扫描是昂贵的,因此通常在此基础结构上建立散列表,以加速查找。PowerPC 就是这种架构的一个例子
作业
1.对于线性页表,假设硬件在 TLB 未命中时进行查找,则需要一个寄存器来定位页表。 您需要多少个寄存器才能找到两级页表? 三级页表?
对于线性页表,每个页表级别都需要一个寄存器来定位页表。
对于两级页表,需要2个寄存器来找到页表。第一个寄存器用于找到一级页表,第二个寄存器用于找到二级页表。
对于三级页表,需要3个寄存器来找到页表。第一个寄存器用于找到一级页表,第二个寄存器用于找到二级页表,第三个寄存器用于找到三级页表。
3.根据你对缓存内存的工作原理的理解,你认为对页表的内存引用如何在缓存中工作?它们是否会导致大量的缓存命中(并导致快速访问)或者很多未命中(并导致访问缓慢)?
缓存置换算法也会影响缓存的命中率。常见的缓存置换算法如LRU(Least Recently Used)、LFU(Least Frequently Used)和随机置换等。这些算法决定了哪些页表项会被保留在TLB中,哪些会被替换出去。
内存虚拟化名词解释
| 英文缩写 | 英文全称 | 中文名称 |
|---|---|---|
| VPN | Virtual Page Number | 虚拟页号 |
| MMU | Memory Management Unit | 内存管理单元 |
| PCB | Process Control Block | 进程控制块 |
| PFN | Page Frame Number | 页帧号 |
| PTE | Page Table Entry | 页表项 |
| PTBR | page-table base register | 页表基址寄存器 |
| TLB | translation-lookaside buffer | 地址转换旁路缓冲存储器 |
| PDE | Page Directory Entries | 页目录项 |
超越物理内存:机制
到目前为止,我们一直假设所有页都常驻在物理内存中。但是,为了支持更大的地址空间,操作系统需要把当前没有在用的那部分地址空间找个地方存储起来。
在现代系统中,硬盘(hard disk drive)通常能够满足这个需求。
为什么我们要为进程支持巨大的地址空间?
可以提供更多的内存使用空间、支持更多的并发性、实现动态内存分配和支持虚拟内存技术等重要功能。
不仅是一个进程,增加交换空间让操作系统为多个并发运行的进程都提供巨大地址空间的假象。
交换空间
第一件事情就是,在硬盘上开辟一部分空间用于物理页的移入和移出。这样的空间称为交换空间(swap space)
我们将内存中的页交换到其中,并在需要的时候又交换回去。因此,我们会假设操作系统能够以页大小为单元读取或者写入交换空间。操作系统需要记住给定页的硬盘地址(disk address)。
交换空间的大小是非常重要的,它决定了系统在某一时刻能够使用的最大内存页数。
在这个例子中,3 个进程(进程 0、进程 1 和进程 2)主动共享物理内存。但 3 个中的每一个,都只有一部分有效页在内存中,剩下的在硬盘的交换空间中。第 4 个进程(进程 3)的所有页都被交换到硬盘上,因此很清楚它目前没有运行。有一块交换空间是空闲的。
要么在程序开始运行时全部加载,要么在现代操作系统中,按需要一页一页加载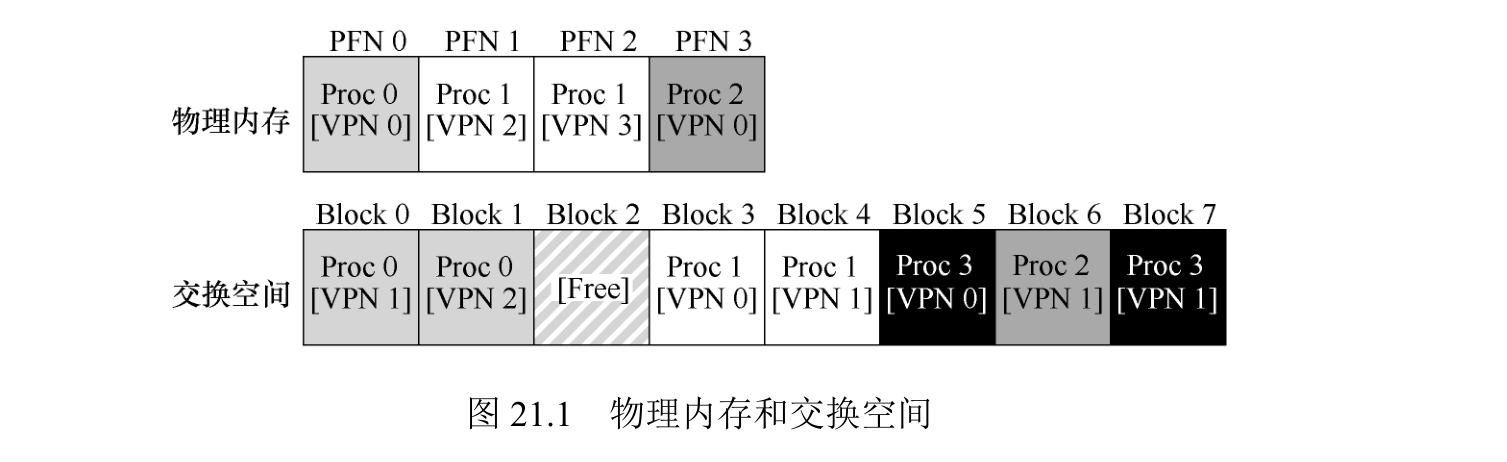
存在位
内存引用发生了什么?
正在运行的进程生成虚拟内存引用(用于获取指令或访问数据),在这种情况下,硬件将其转换为物理地址,再从内存中获取所需数据。
硬件首先从虚拟地址获得 VPN,检查 TLB 是否匹配(TLB 命中),如果命中,则获得最终的物理地址并从内存中取回。这希望是常见情形,因为它很快(不需要额外的内存访问)。
如果在 TLB 中找不到 VPN(即 TLB 未命中),则硬件在内存中查找页表(使用页表基址寄存器),并使用 VPN 查找该页的页表项(PTE)作为索引。如果页有效且存在于物理内存中,则硬件从 PTE 中获得 PFN,将其插入 TLB,并重试该指令,这次产生 TLB 命中。到现在为止还挺好。
如果希望允许页交换到硬盘,必须添加更多的机制。具体来说,当硬件在 PTE中查找时,可能发现页不在物理内存中。硬件(或操作系统,在软件管理 TLB 时)判断是否在内存中的方法,是通过页表项中的一条新信息,即存在位(present bit)。如果存在位设置为 1,则表示该页存在于物理内存中,并且所有内容都如上所述进行。如果存在位设置为零,则页不在内存中,而在硬盘上。访问不在物理内存中的页,这种行为通常被称为页错误(page fault)。
一个程序“页错误”时,意味着它正在访问的虚拟地址空间的一部分,被操作系统交换到了硬盘上。
在页错误时,操作系统被唤起来处理页错误。一段称为“页错误处理程序(page-fault handler)”的代码会执行,来处理页错误。
页错误
在 TLB 未命中的情况下,我们有两种类型的系统:硬件管理的 TLB(硬件在页表中找到需要的转换映射)和软件管理的 TLB(操作系统执行查找过程)。不论在哪种系统中,如果页不存在,都由操作系统负责处理页错误。操作系统的页错误处理程序(page-fault handler)确定要做什么。几乎所有的系统都在软件中处理页错误。即使是硬件管理的 TLB,硬件也信任操作系统来管理这个重要的任务。
操作系统如何知道所需的页在哪儿?
在许多系统中,页表是存储这些信息最自然的地方。因此,操作系统可以用 PTE 中的某些位来存储硬盘地址,这些位通常用来存储像页的 PFN 这样的数据。当操作系统接收到页错误时,它会在 PTE 中查找地址,并将请求发送到硬盘,将页读取到内存中。
当硬盘 I/O 完成时,操作系统会更新页表,将此页标记为存在,更新页表项(PTE)的PFN 字段以记录新获取页的内存位置,并重试指令。下一次重新访问 TLB 还是未命中,然而这次因为页在内存中,因此会将页表中的地址更新到 TLB 中(也可以在处理页错误时更新 TLB 以避免此步骤)。最后的重试操作会在 TLB 中找到转换映射,从已转换的内存物理地址,获取所需的数据或指令。
请注意,当 I/O 在运行时,进程将处于阻塞(blocked)状态。因此,当页错误正常处理时,操作系统可以自由地运行其他可执行的进程。因为 I/O 操作是昂贵的,一个进程进行I/O(页错误)时会执行另一个进程,这种交叠(overlap)是多道程序系统充分利用硬件的一种方式。
内存满了怎么办
操作系统可能希望先交换出(page out)一个或多个页,以便为操作系统即将交换入的新页留出空间。选择哪些页被交换出或被替换(replace)的过程,被称为页交换策略(page-replacementpolicy)。
页错误处理流程
1 | VPN = (VirtualAddress & VPN_MASK) >> SHIFT |
当 TLB 未命中发生的时候有 3 种重要情景。
第一种情况,该页存在(present)且有效(valid)(第 18~21 行)。在这种情况下,TLB 未命中处理程序可以简单地从 PTE 中获取 PFN,然后重试指令(这次 TLB 会命中),并因此继续前面描述的流程。
第二种情况(第 22~23 行),页错误处理程序需要运行。虽然这是进程可以访问的合法页(毕竟是有效的),但它并不在物理内存中。
第三种情况,访问的是一个无效页,可能由于程序中的错误(第 13~14 行)。在这种情况下,PTE 中的其他位都不重要了。硬件捕获这个非法访问,操作系统陷阱处理程序运行,可能会杀死非法进程。
为了处理页错误,操作系统大致做了什么?
首先,操作系统必须为将要换入的页找到一个物理帧,如果没有这样的物理帧,我们将不得不等待交换算法运行,并从内存中踢出一些页,释放帧供这里使用。在获得物理帧后,处理程序发出 I/O 请求从交换空间读取页。最后,当这个慢操作完成时,操作系统更新页表并重试指令。重试将导致 TLB 未命中,然后再一次重试时,TLB 命中,此时硬件将能够访问所需的值。
交换何时真正发生
为了保证有少量的空闲内存,大多数操作系统会设置高水位线(High Watermark,HW)和低水位线(Low Watermark,LW),来帮助决定何时从内存中清除页。原理是这样:当操作系统发现有少于 LW 个页可用时,后台负责释放内存的线程会开始运行,直到有 HW 个可用的物理页。这个后台线程有时称为交换守护进程(swap daemon)或页守护进程(page daemon),它然后会很开心地进入休眠状态,因为它毕竟为操作系统释放了一些内存。
通过同时执行多个交换过程,我们可以进行一些性能优化。例如,许多系统会把多个要写入的页聚集(cluster)或分组(group),同时写入到交换区间,从而提高硬盘的效率。
超越物理内存:策略
由于内存压力(memory pressure)迫使操作系统换出(paging out)一些页,为常用的页腾出空间。确定要踢出(evict)哪个页(或哪些页)封装在操作系统的替换策略(replacement policy)中。
缓存管理
由于内存只包含系统中所有页的子集,因此可以将其视为系统中虚拟内存页的缓存(cache)。因此,在为这个缓存选择替换策略时,我们的目标是让缓存未命中(cache miss)最少,即使得从磁盘获取页的次数最少。或者,可以将目标看成让缓存命中(cache hit)最多,即在内存中找到待访问页的次数最多。
知道了缓存命中和未命中的次数,就可以计算程序的平均内存访问时间(Average Memory Access Time,AMAT,计算机架构师衡量硬件缓存的指标 )
AMAT = (PHit·TM) + (PMiss·TD)
其中 TM 表示访问内存的成本,TD 表示访问磁盘的成本,PHit 表示在缓存中找到数据的概率(命中),PMiss表示在缓存中找不到数据的概率(未命中)。PHit和 PMiss从 0.0 变化到 1.0,并且 PMiss + PHit = 1.0。
最优替换策略(无法实现)
替换内存中在最远将来才会被访问到的页,可以达到缓存未命中率最低。
根据即将执行的队列元素顺序进行踢出,缓存里的元素在后续队列中谁离得远踢谁
举例
假设一个程序按照以下顺序访问
虚拟页:0,1,2,0,1,3,0,3,1,2,1。
前 3 个访问是未命中,因为缓存开始是空的。这种未命中有时也称作冷启动未命中(cold-start miss,或强制未命中,compulsory miss)。
然后我们再次引用页 0 和 1,它们都在缓存中。
最后,我们又有一个缓存未命中(页3),但这时缓存已满,必须进行替换!
使用最优策略,我们检查当前缓存中每个页(0、1 和 2)未来访问情况,可以看到页 0 马上被访问,页 1 稍后被访问,页 2 在最远的将来被访问。
未来的访问是无法知道的,你无法为通用操作系统实现最优策略。
补充:缓存未命中的类型
在计算机体系结构世界中,架构师有时会将未命中分为 3 类:强制性、容量和冲突未命中,有时称为3C [H87]。发生强制性(compulsory miss)未命中(或冷启动未命中,cold-start miss [EF78])是因为缓存开始是空的,而这是对项目的第一次引用。与此不同,由于缓存的空间不足而不得不踢出一个项目以将新项目引入缓存,就发生了容量未命中(capacity miss)。第三种类型的未命中(冲突未命中,conflict miss)出现在硬件中,因为硬件缓存中对项的放置位置有限制,这是由于所谓的集合关联性(set-associativity)。它不会出现在操作系统页面缓存中,因为这样的缓存总是完全关联的(fully-associative),即对页面可以放置的内存位置没有限制。详情请见 H&P [HP06]。
简单策略:FIFO
页在进入系统时,简单地放入一个队列。当发生替换时,最先进入的被踢出。FIFO 有一个很大的优势:实现相当简单。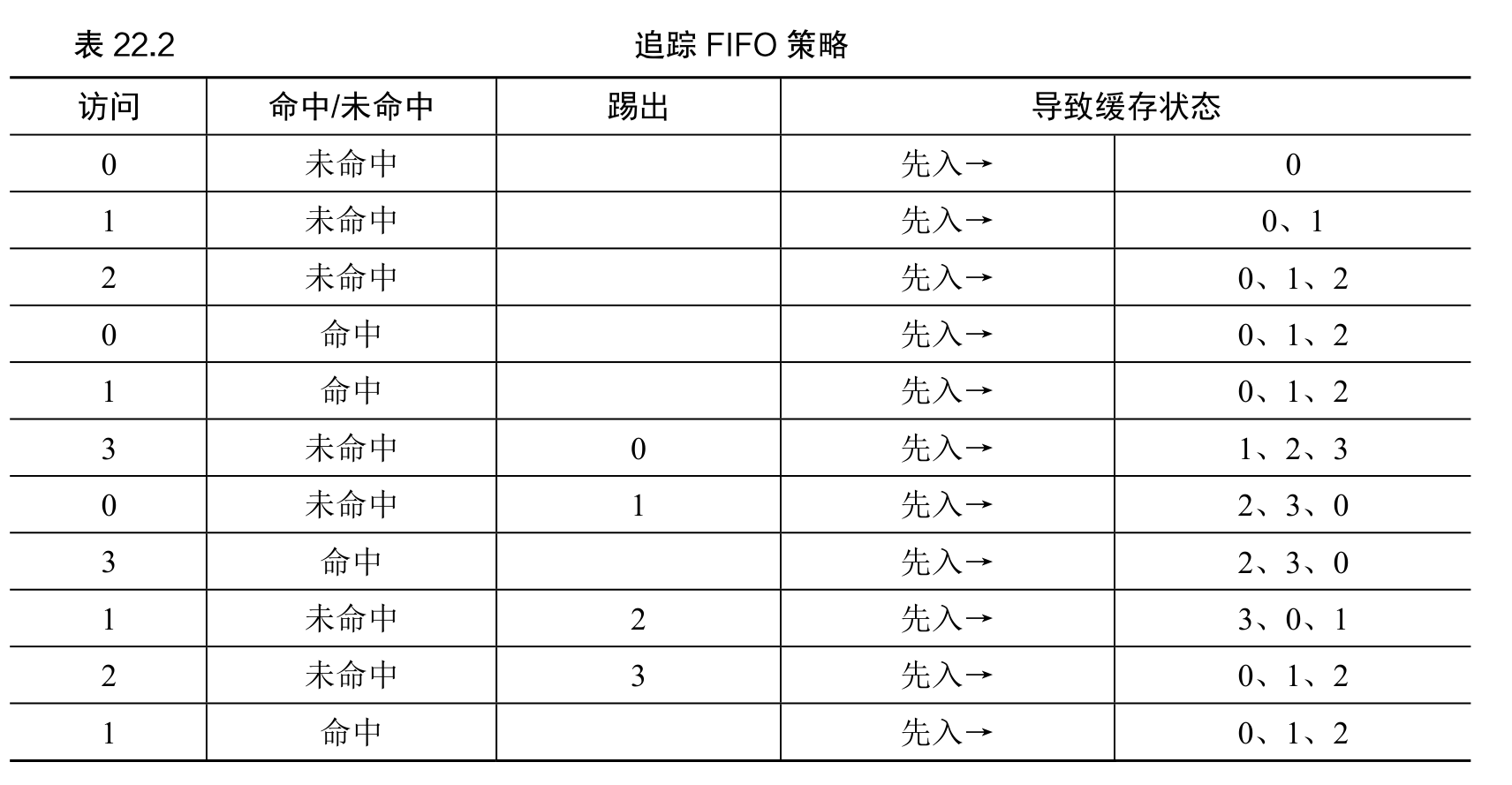
一般来说,当缓存变大时,缓存命中率是会提高的。但在这个例子,采用 FIFO,命中率反而下降了! 这种奇怪的现象被称为 Belady 的异常(Belady’s Anomaly)。
其他一些策略,比如 LRU,不会遇到这个问题。可以猜猜为什么?
LRU 具有所谓的栈特性(stack property)。对于具有这个性质的算法,大小为 N + 1 的缓存自然包括大小为 N 的缓存的内容。因此,当增加缓存大小时,缓存命中率至少保证不变,有可能提高。先进先出(FIFO)和随机(Random)等显然没有栈特性,因此容易出现异常行为。
另一简单策略:随机
另一个类似的替换策略是随机,在内存满的时候它随机选择一个页进行替换。随机具有类似于 FIFO 的属性。实现我来很简单,但是它在挑选替换哪个页时不够智能。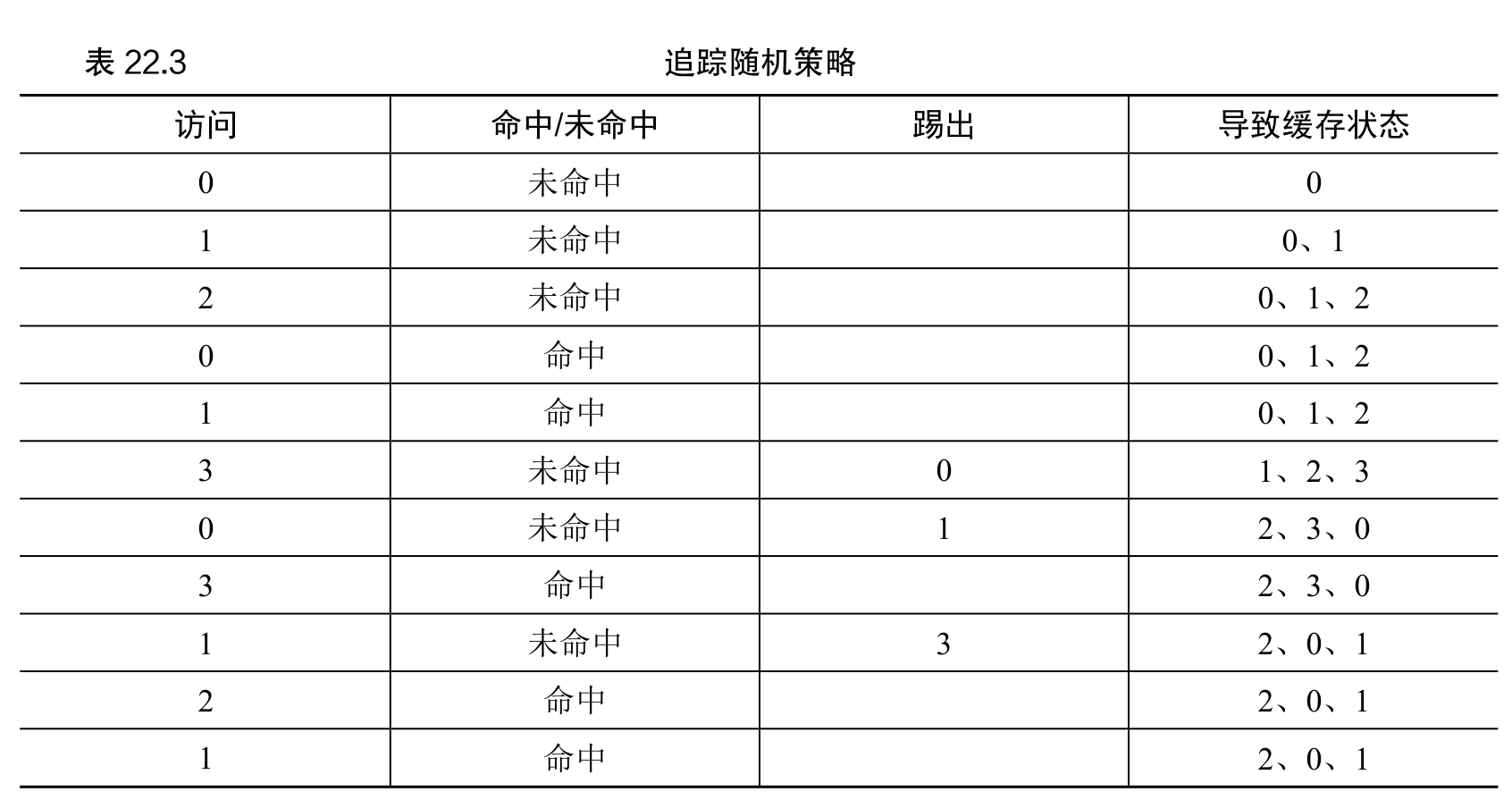
随机策略取决于当时的运气。
利用历史数据:LRU
为了提高后续的命中率,我们再次通过历史的访问情况作为参考。例如,如果某个程序在过去访问过某个页,则很有可能在不久的将来会再次访问该页。
页更常用的属性是访问的近期性(recency),越近被访问过的页,也许再次访问的可能性也就越大。
一系列简单的基于历史的算法诞生了。“最不经常使用”(Least-Frequently-Used,LFU)策略会替换最不经常使用的页。
同样,“最少最近使用”(Least-Recently-Used,LRU)策略替换最近最少使用的页面。
补充:局部性类型
程序倾向于表现出两种类型的局部。第一种是空间局部性(spatial locality),它指出如果页 P 被访问,可能围绕它的页(比如 P−1 或 P + 1)也会被访问。
第二种是时间局部性(temporal locality),它指出近期访问过的页面很可能在不久的将来再次访问。
假设存在这些类型的局部性,对硬件系统的缓存层次结构起着重要作用,硬件系统部署了许多级别的指令、数据和地址转换缓存,以便在存在此类局部性时,能帮助程序快速运行。
在这个例子中,当第一次需要替换页时,LRU 会踢出页 2,因为 0 和 1 的访问时间更近。然后它替换页 0,因为 1 和 3 最近被访问过。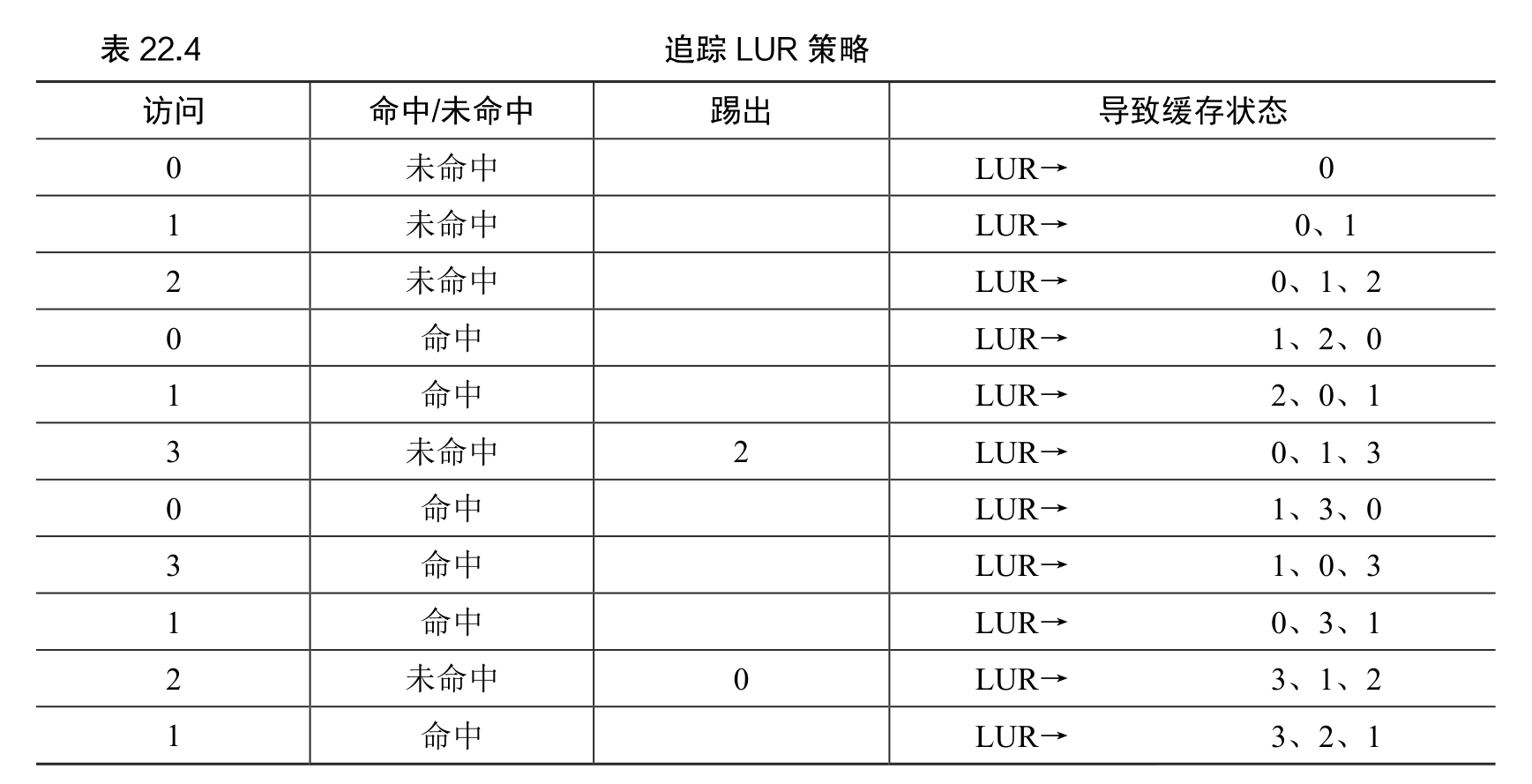
从当前位置往前看,缓存中谁在最前面就踢谁。
与这些算法完全相反的算法也是存在:最经常使用策略(Most-Frequently-Used,MFU)和最近使用策略(Most-Recently-Used,MRU)。在大多数情况下(不是全部!),这些策略效果都不好,因为它们忽视了大多数程序都具有的局部性特点。
工作负载示例
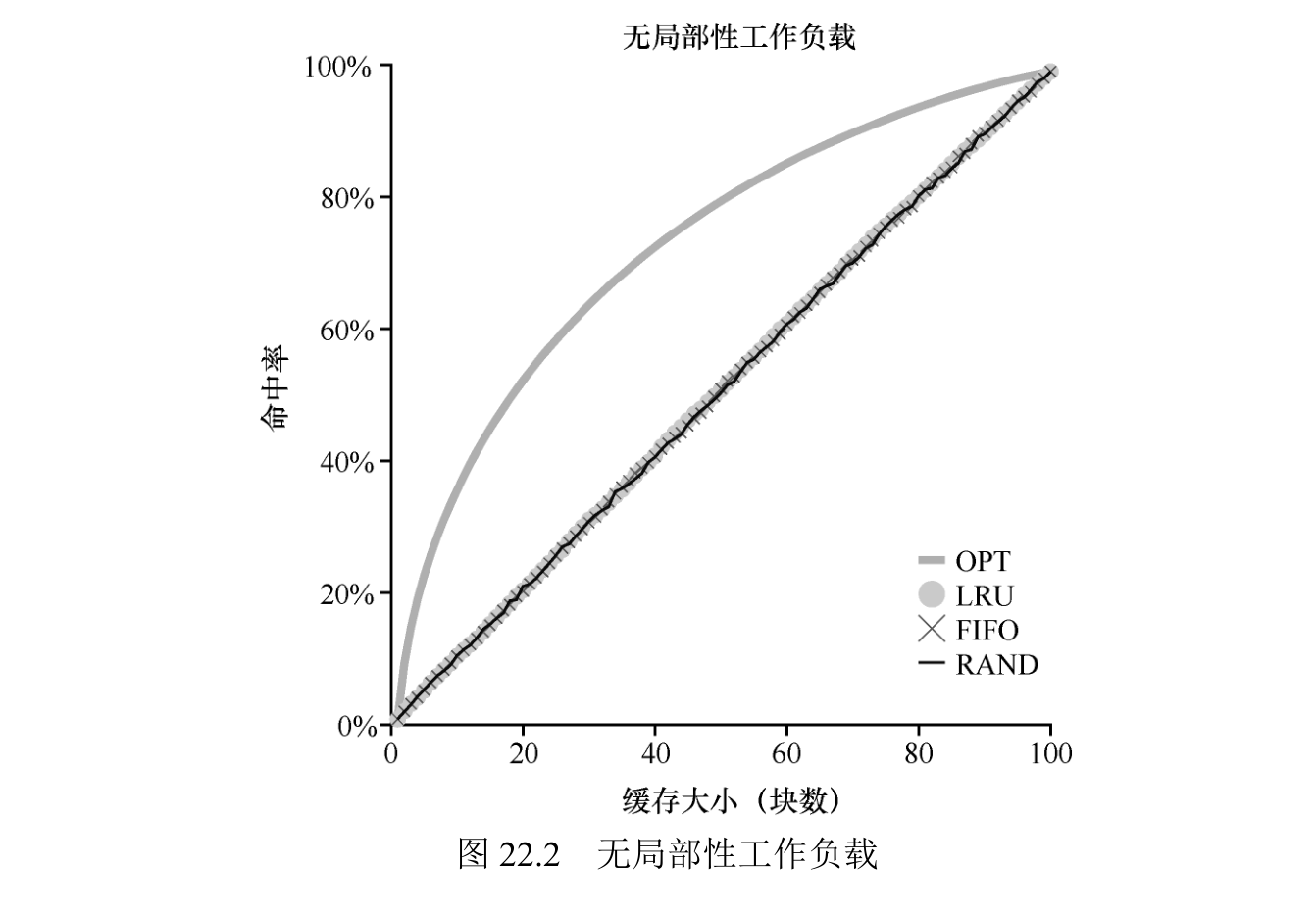
当工作负载不存在局部性时,使用的策略区别不大。LRU、FIFO 和随机都执行相同的操作,命中率完全由缓存的大小决定。其次,当缓存足够大到可以容纳所有的数据时,使用哪种策略也无关紧要,所有的策略(甚至是随机的)都有 100%的命中率。
我们下一个工作负载就是所谓的“80—20”负载场景,它表现出局部性:80%的引用是访问 20%的页(“热门”页)。剩下的 20%是对剩余的 80%的页(“冷门”页)访问。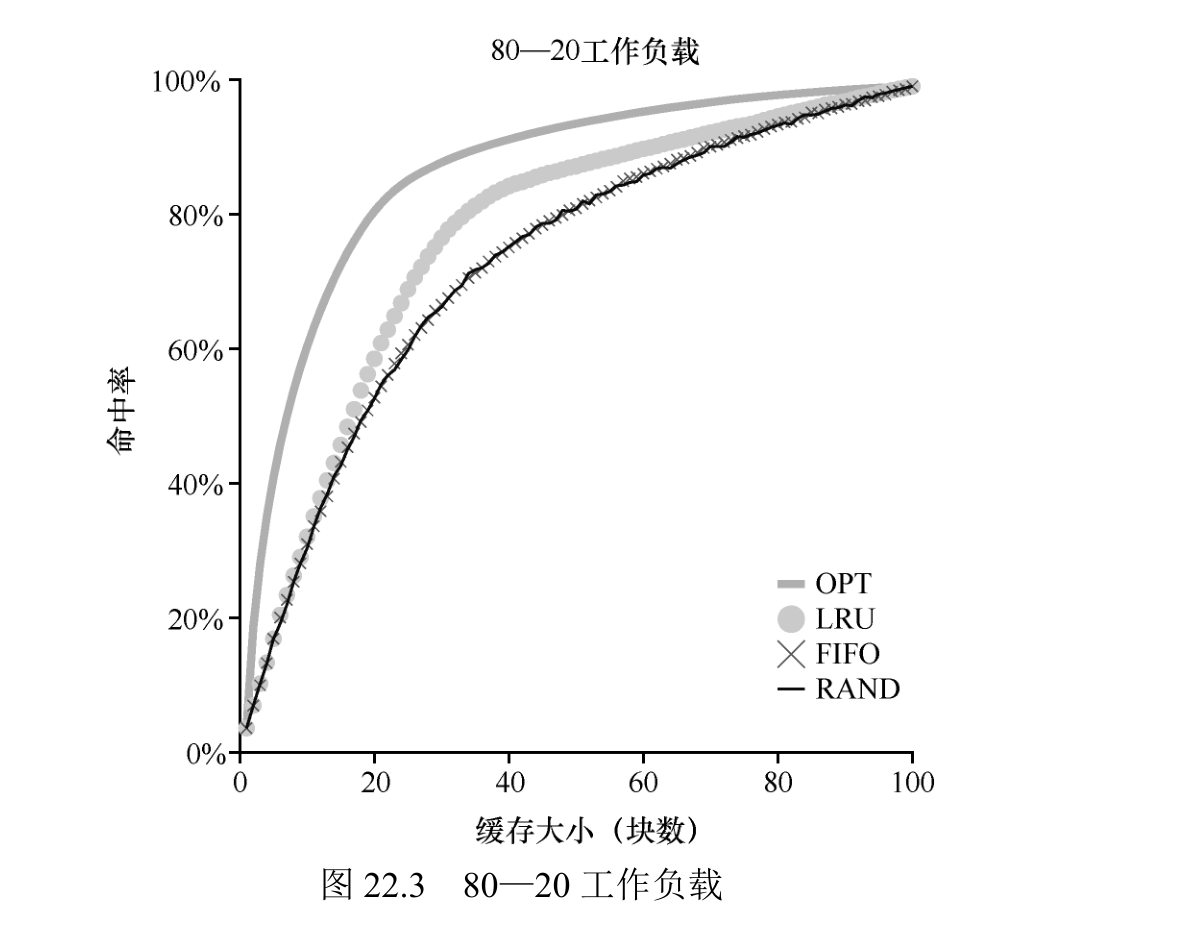
尽管随机和 FIFO 都很好地运行,但 LRU 更好,因为它更可能保持热门页。由于这些页面过去经常被提及,它们很可能在不久的将来再次被提及。优化再次表现得更好,表明 LRU 的历史信息并不完美。
我们称之为“循环顺序”工作负载,其中依次引用 50个页,从 0 开始,然后是 1,…,49,然后循环,重复访问,总共有 10000 次访问 50 个单独页。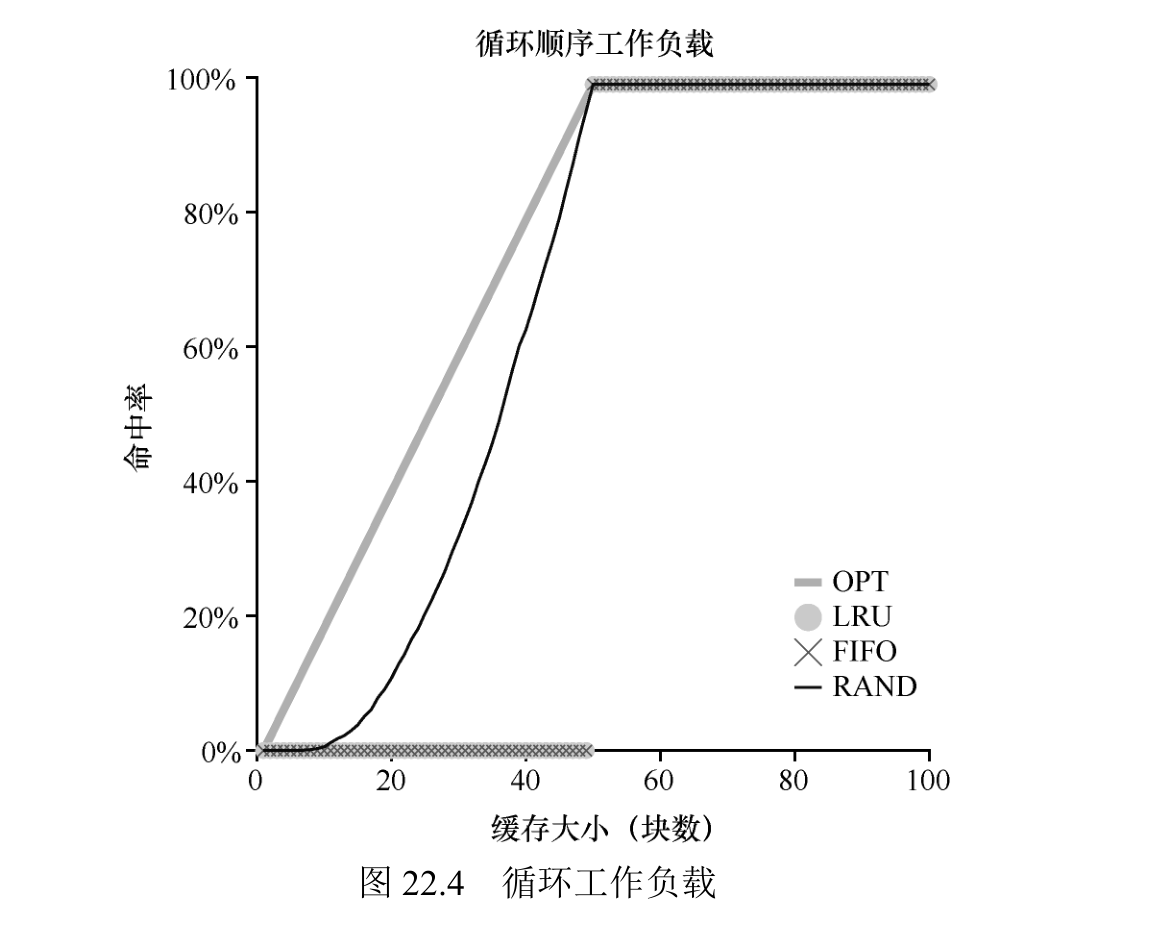
展示了 LRU 或者 FIFO 的最差情况。
实现基于历史信息的算法
以 LRU 为例。具体地说,在每次页访问(即每次内存访问,不管是取指令还是加载指令还是存储指令)时,我们都必须更新一些数据,从而将该页移动到列表的前面(即 MRU 侧)。与 FIFO 相比,FIFO 的页列表仅在页被踢出(通过移除最先进入的页)或者当新页添加到列表(已到列表尾部)时才被访问。为了记录哪些页是最少和最近被使用,系统必须对每次内存引用做一些记录工作。
有一种方法有助于加快速度,就是增加一点硬件支持。例如,硬件可以在每个页访问时更新内存中的时间字段(时间字段可以在每个进程的页表中,或者在内存的某个单独的数组中,每个物理页有一个)。因此,当页被访问时,时间字段将被硬件设置为当前时间。然后,在需要替换页时,操作系统可以简单地扫描系统中所有页的时间字段以找到最近最
少使用的页。
随着系统中页数量的增长,扫描所有页的时间字段只是为了找到最精确最
少使用的页,这个代价太昂贵。
由于实现完美的 LRU 代价非常昂贵,我们能否实现一个近似的 LRU 算法,并且依然能够获得预期的效果?
近似 LRU
系统的每个页有一个使用位,然后这些使用位存储在某个地方(例如,它们可能在每个进程的页表中,或者只在某个数组中)。每当页被引用(即读或写)时,硬件将使用位设置为 1。但是,硬件不会清除该位(即将其设置为 0),这由操作系统负责。
系统中的所有页都放在一个循环列表中。时钟指针(clock hand)开始时指向某个特定的页(哪个页不重要)。当必须进行页替换时,操作系统检查当前指向的页 P 的使用位是 1 还是 0。如果是 1,则意味着页面 P 最近被使用,因此不适合被替换。然后,P 的使用位设置为 0,时钟指针递增到下一页(P + 1)。该算法一直持续到找到一个使用位为 0 的页,使用位为 0 意味着这个页最近没有被使用过(在最坏的情况下,所有的页都已经被使用了,那么就将所有页的使用位都设置为 0)。
时钟算法:该变种在需要进行页替换时随机扫描各页,如果遇到一个页的引用位为 1,就清除该位(即将它设置为 0)。直到找到一个使用位为 0的页,将这个页进行替换。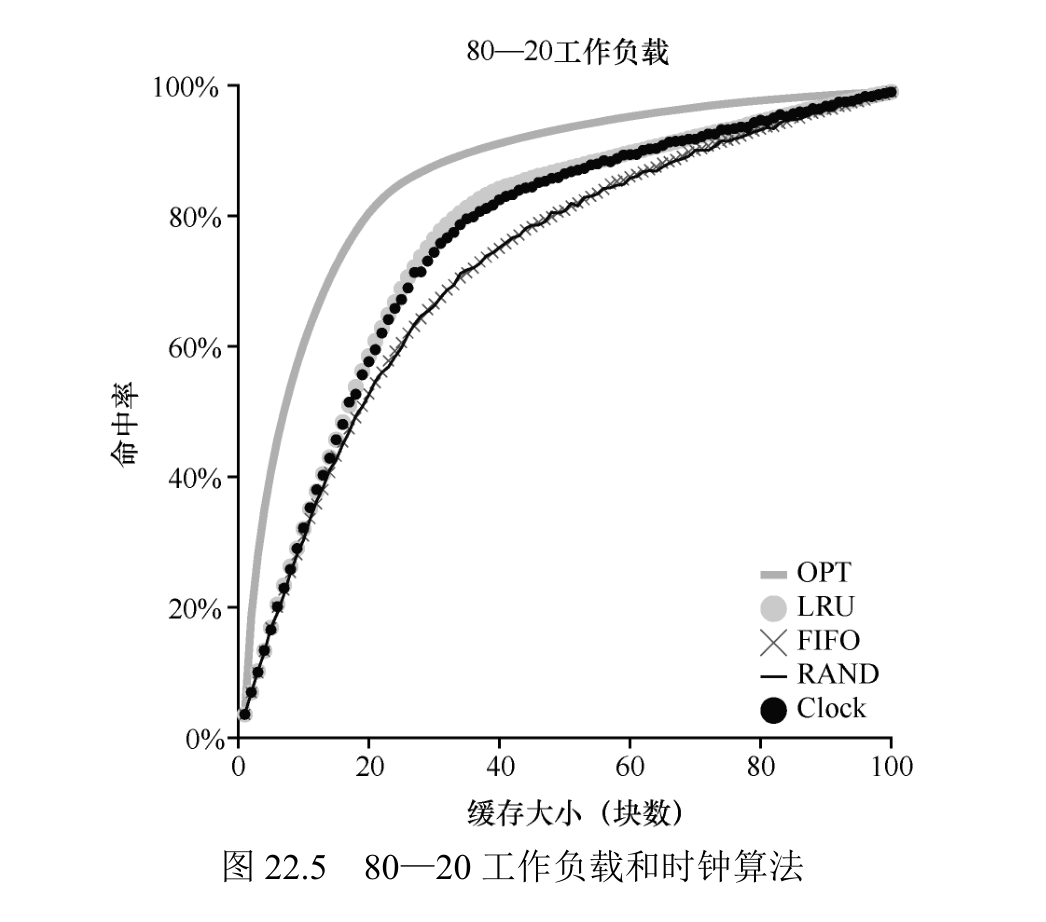
考虑脏页
如果页已被修改(modified)并因此变脏(dirty),则踢出它就必须将它写回磁盘,这很昂贵。如果它没有被修改(因此是干净的,clean),踢出就没成本。物理帧可以简单地重用于其他目的而无须额外的 I/O。因此,一些虚拟机系统更倾向于踢出干净页,而不是脏页。
其他虚拟内存策略
页面替换不是虚拟内存子系统采用的唯一策略(尽管它可能是最重要的)。例如,操作系统还必须决定何时将页载入内存。该策略有时称为页选择(page selection)策略。
另一个策略决定了操作系统如何将页面写入磁盘。许多系统会在内存中收集一些待完成写入,并以一种(更高效)的写入方式将它们写入硬盘。这种行为通常称为聚集(clustering)写入,或者就是分组写入(grouping),这样做有效是因为硬盘驱动器的性质,执行单次大的写操作,比许多小的写操作更有效。
抖动
当内存就是被超额请求时,在这种情况下,系统将不断地进行换页,这种情况有时被称为抖动(thrashing)。
当内存被超额请求时,系统内存不足以容纳所有需要运行的进程和数据,因此系统需要不断进行换页操作。换页是指将内存中的某些页面(页框)置换到磁盘上,以释放内存空间给新的页面使用。
VAX//VVM虚拟内存系统
内存管理硬件
VAX-11 为每个进程提供了一个 32 位的虚拟地址空间,分为 512 字节的页。因此,虚拟地址由 23 位 VPN 和 9 位偏移组成。此外,VPN 的高两位用于区分页所在的段。因此,如前所述,该系统是分页和分段的混合体。
地址空间的下半部分称为“进程空间”,对于每个进程都是唯一的。在进程空间的前半部分(称为 P0)中,有用户程序和一个向下增长的堆。在进程空间的后半部分(P1),有向上增长的栈。地址空间的上半部分称为系统空间(S),尽管只有一半被使用。受保护的操作系统代码和数据驻留在此处,操作系统以这种方式跨进程共享。
一个真实的地址空间
补充:为什么空指针访问会导致段错误
你现在应该很好地理解一个空指针引用会发生什么。通过这样做,进程生成了一个虚拟地址 0:
int *p = NULL; // set p = 0
*p = 10; // try to store value 10 to virtual address 0
硬件试图在 TLB 中查找 VPN(这里也是 0),遇到 TLB 未命中。查询页表,并且发现 VPN 0 的条目被标记为无效。因此,我们遇到无效的访问,将控制权交给操作系统,这可能会终止进程(在 UNIX 系统上,会向进程发出一个信号,让它们对这样的错误做出反应。但是如果信号未被捕获,则会终止进程)。
代码段永远不会从第 0 页开始。相反,该页被标记为不可访问,以便为检测空指针(null-pointer)访问提供一些支持。
页替换
VAX 中的页表项(PTE)包含以下位:一个有效位,一个保护字段(4 位),一个修改(或脏位)位,为 OS 使用保留的字段(5 位),最后是一个物理帧号码(PFN)将页面的位置存储在物理内存中。
分段的 FIFO
每个进程都有一个可以保存在内存中的最大页数,称为驻留集大小(Resident Set Size,RSS)。每个页都保存在 FIFO 列表中。当一个进程超过其 RSS 时,“先入”的页被驱逐。FIFO 显然不需要硬件的任何支持,因此很容易实现。
其他漂亮的虚拟内存技巧
按需置零和写入时复制。
在一个初级实现中,操作系统响应一个请求,在物理内存中找到页,将该页添加到你的堆中,并将其置零(安全起见,这是必需的。否则,你可以看到其他进程使用该页时的内容。),然后将其映射到你的地址空间(设置页表以根据需要引用该物理页)。但是初级实现可能是昂贵的,特别是如果页没有被进程使用.
利用按需置零,当页添加到你的地址空间时,操作系统的工作很少。它会在页表中放入一个标记页不可访问的条目。如果进程读取或写入页,则会向操作系统发送陷阱。在处理陷阱时,操作系统注意到(通常通过页表项中“保留的操作系统字段”部分标记的一些位),这实际上是一个按需置零页。此时,操作系统会完成寻找物理页的必要工作,将它置零,并映射到进程的地址空间。如果该进程从不访问该页,则所有这些工作都可以避免,从而体现按需置零的好处。
如果操作系统需要将一个页面从一个地址空间复制到另一个地址空间,不是实际复制它,而是将其映射到目标地址空间,并在两个地址空间中将其标记为只读。如果两个地址空间都只读取页面,则不会采取进一步的操作,因此操作系统已经实现了快速复制而不实际移动任何数据。但是,如果其中一个地址空间确实尝试写入页面,就会陷入操作系统。操作系统会注意到该页面是一个 COW 页面,因此(惰性地)分配一个新页,填充数据,并将这个新页映射到错误处理的地址空间。该进程然后继续,现在有了该页的私人副本。

