应用层
应用层协议原理
网络应用体系结构
客户服务器体系结构
P2P体系结构
套接字
socket(套接字)
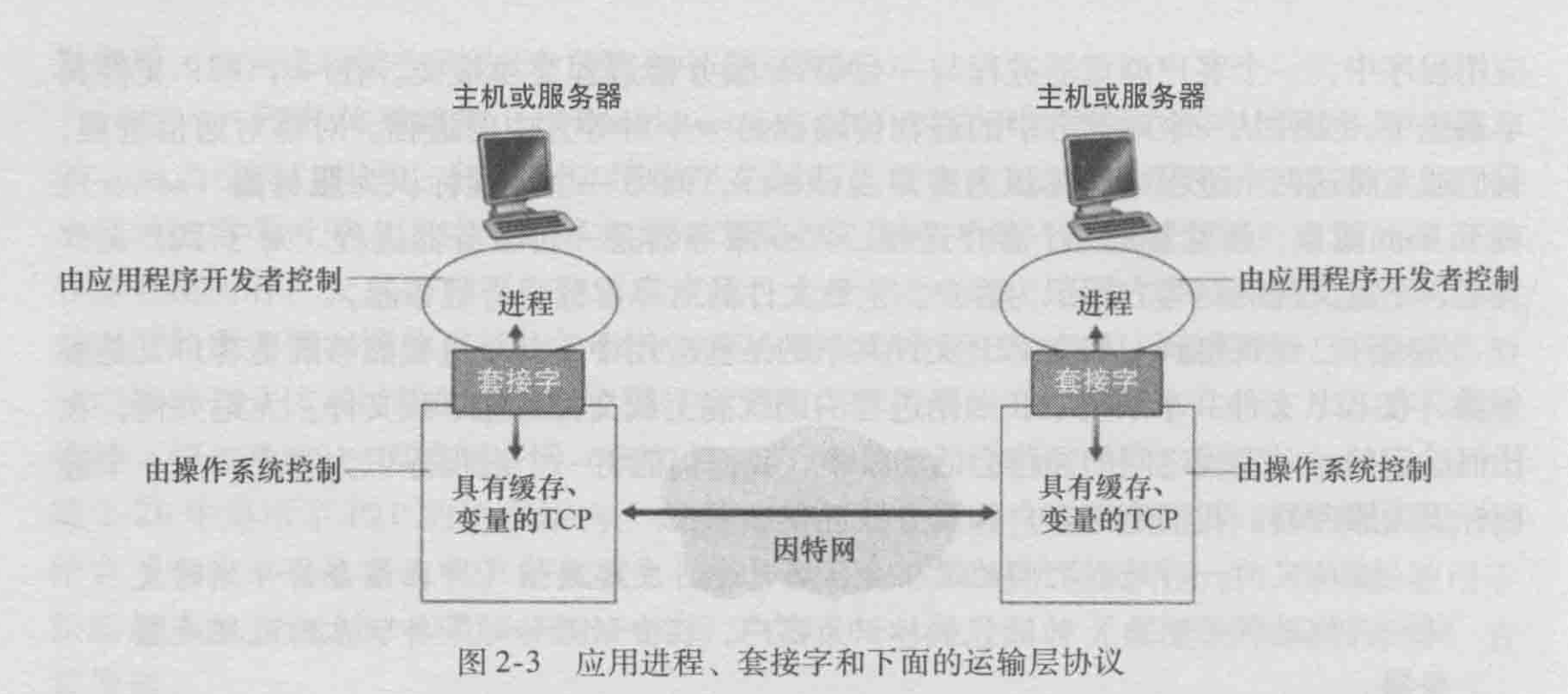
运输层协议的关键指标
如果一个协议提供了确保数据交付服务,就认为提供了可靠数据传输。
具有吞吐量要求的应用程序被称为带宽敏感的应用(bandwidth-sensitive application),许多当前的多媒体应用是带宽敏感的。
定时,这种服务将对交互式实时应用程序有吸引力。
安全性,运输协议能够为应用程序提供一种或多种安全性服务。

TCP:
面向连接,可靠的网络传输
安全套接字层(secure socket layer)ssl:
他不是传输层上的第三种协议,而是tcp协议的加强版。
用 SSL 加强后的 TCP不仅能够做传统的TCP所能做的一切,而且提供了关键的进程到进程的安全性服务,包括加密、数据完整性和端点鉴别。
SSL有它自己的套接字API,这类似于传统的TCP套接字API。当一个应用使用SSL时,发送进程向SSL套接字传递明文数据;在发送主机中的SSL则加密该数据并将加密的数据传递给TCP套接字。加密的数据经因特网传送到接收进程中的TCP套接字。该接收套接字将加密数据传递给SSL,由其进行解密。
UDP:
无连接,不可靠的网络传输
应用层协议

web和http
http协议
Web的应用层协议是超文本传输协议(HyperText Transfe Protocol,HTTP)
因为 Web浏览器(Web browser)(例如 Internet Explorer 和 Firefox)实现了HTTP 的客户端,所以在 Web环境中我们经常交替使用。
“浏览器”和“客户”这两个术语。 Web服务器(Web server)实现了HTTP的服务器端,它用于存储Web对象,每个对象由 URL寻址。流行的Web服务器有 Apache和 Microso
Internet Information Server。
http的底层是tcp协议
这里我们看到了分层体系结构最大的优点,即 HTTP 协议不用担心数据丢失,也不关注TCP 从网络的数据丢失和乱序故障中恢复的细节。那是 TCP以及协议栈较低层协议的工作。
http协议不会保存用户的信息,所以他是无状态的。
持续响应和非持续响应
对响应或者请求都使用一个tcp进行连接发送是持续响应,否则是非持续响应。
往返时间 (Round-Trip Time, RTT)的定义,该时间是指一个短分组从客户到服务器然后再返回客户所花费的时间。
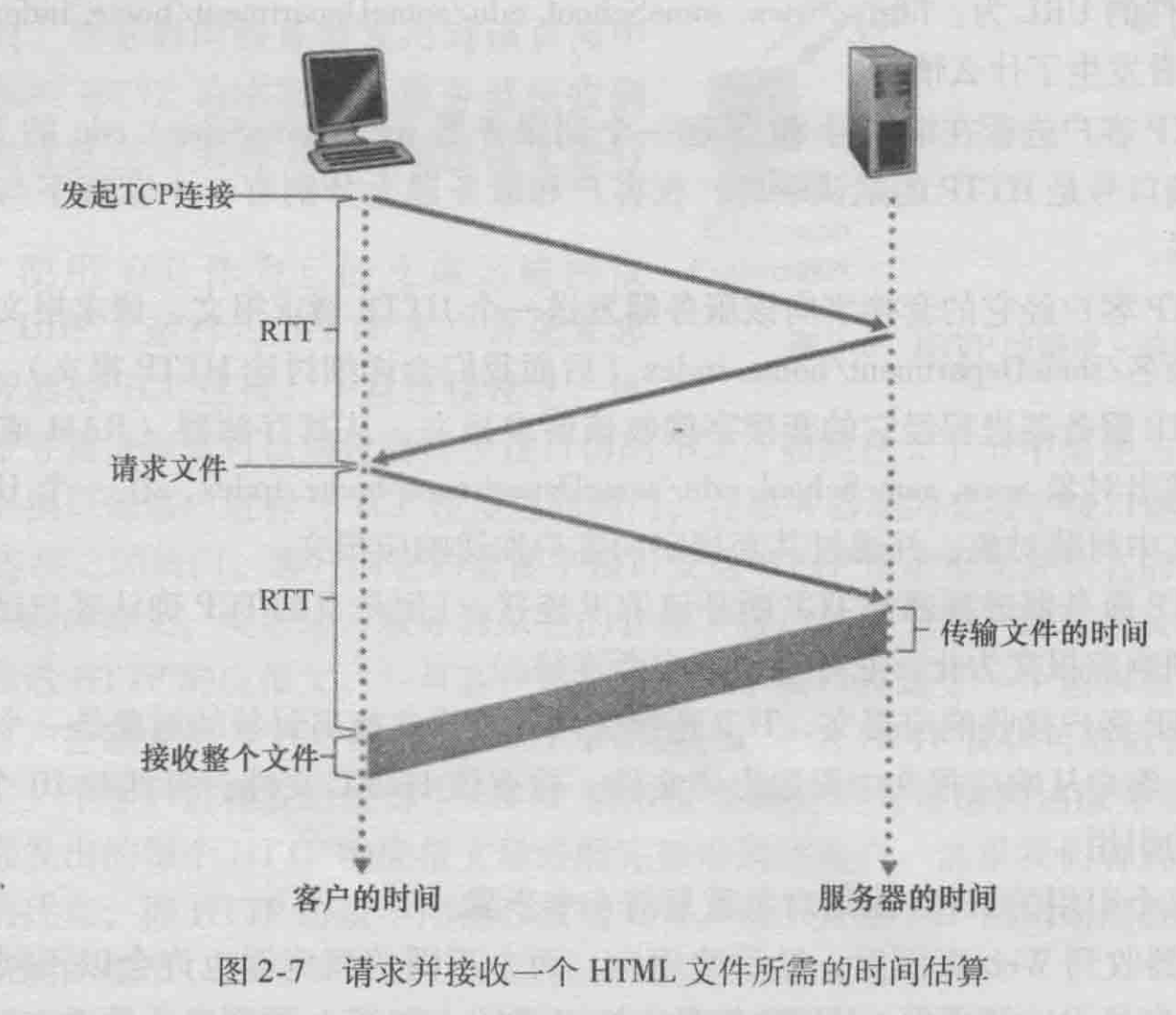
http的报文格式
http请求报文
请求行包括:方法字段(get、put、head、delete、post)、URL字段(请求字段)和 HTTP版本字段
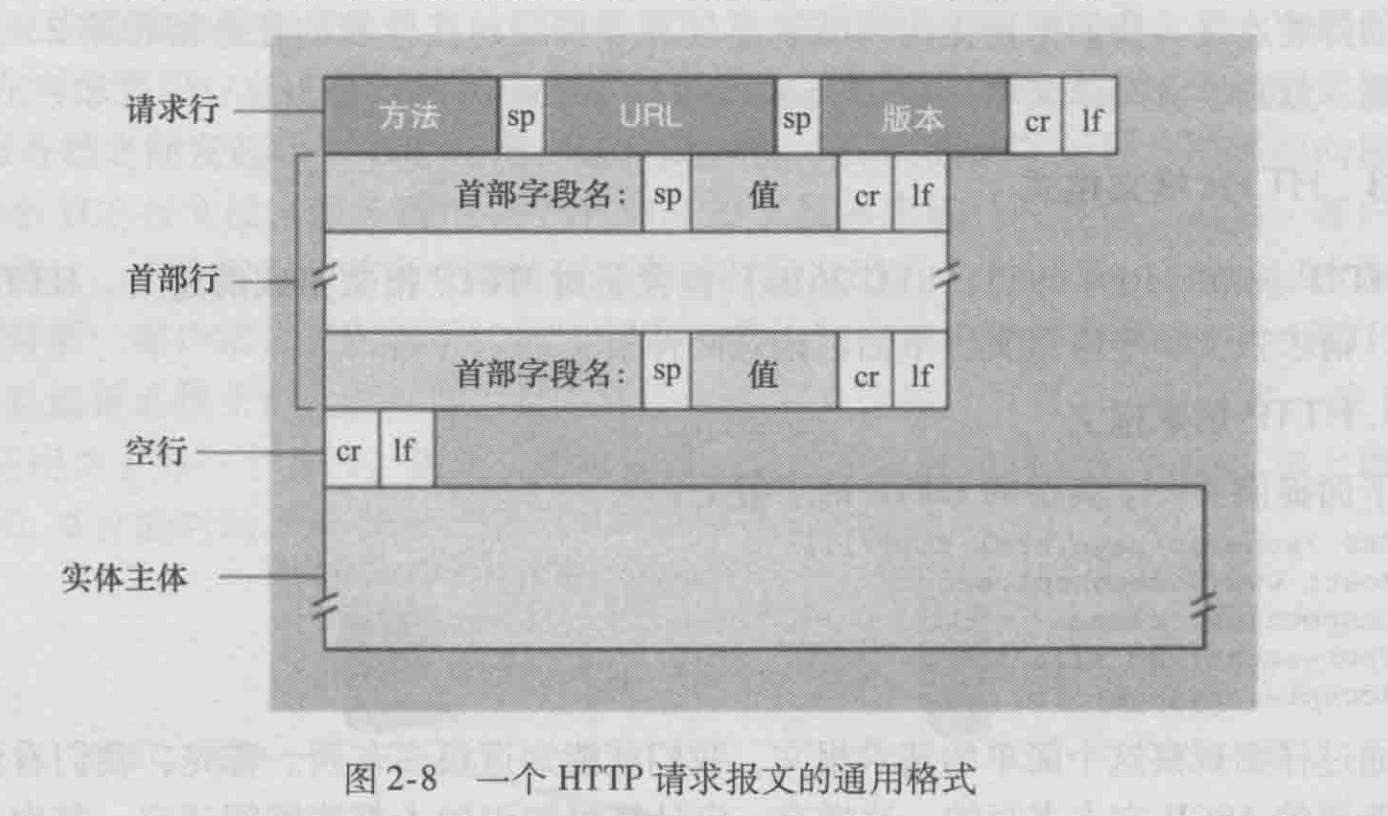

通过包含 Connection:close首部行,该浏览器告诉服务器不希望麻烦地使用持续连接,它要求服务器在发送完被请求的对象后就关闭这条连接。
User-agent:首部行用来指明用户代理,即向服务器发送请求的浏览器的类型,这里浏览器类型是 Mozilla/5.0,即Firefox浏览器。
注意到了在首部行(和附加的回车和换行)后有一个实体主体(entity body)。使用GET方法时实体主体为空,而使用POST方法时才使用该实体体。当用户提交表单时,HTTP客户常常使用POST方法,例如当用户向搜索引擎提供搜索关键词时。使用 POST 报文时,用户仍可以向服务器请求一个Web页面,但Web页面的特定内容依赖于用户在表单字段中输人的内容。如果方法字段的值为POST时,则实体体中包含的就是用户在表单字段中的输入值。
用表单生成的请求报文不是必须使用POST方法。HTML表单经常使用GET方法,并在(表单字段中)所请求的URL中包括输入的数据。例如,一个表单使用GET方法有一个字段填写的是monkeys(https://www.baidu.com/s?wd=monkey)。
HEAD方法类似于GET方法。当服务器收到使用HEAD方法的请求时,将会用一个HTTP报文进行响应,但是并不返回请求对象。应用程序开发者常用HEAD方法进行调试跟踪。
PUT方法常与Web发行工具联合使用,它允许上传指定的路径(目录)。PUT 方法也被那些需要向Web服务器上传对象的应用程序使用。
DELETE方法允许用户或者应用程序删除Web服务器上的对象。
http响应报文
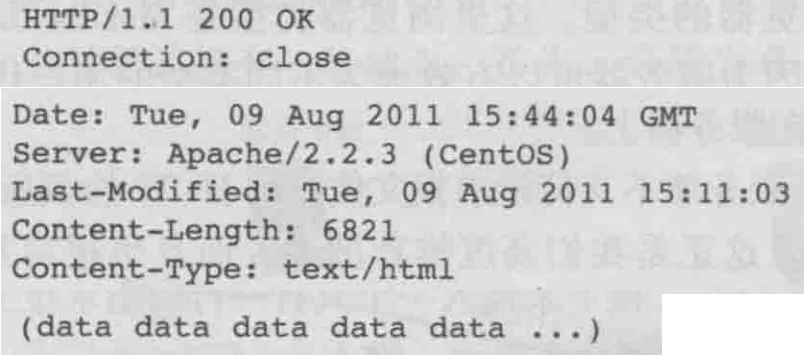
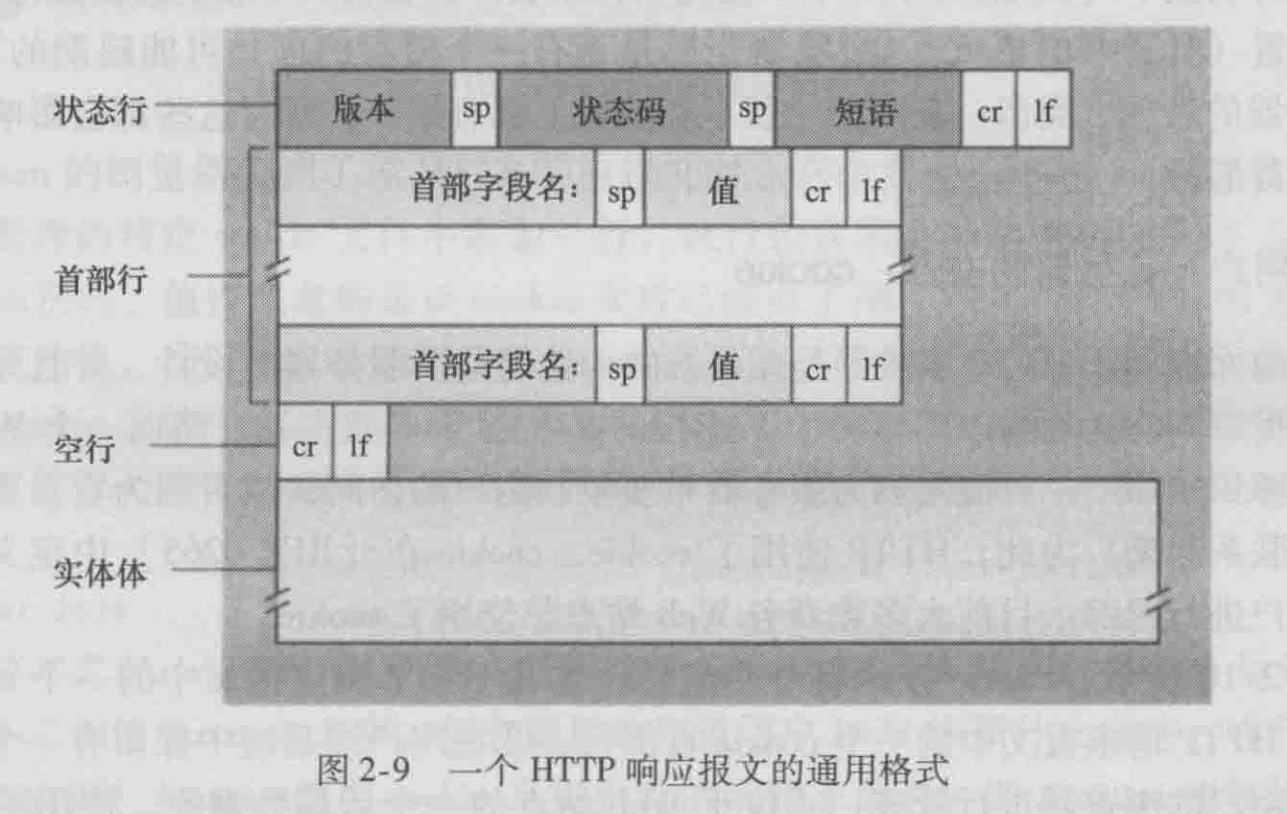
我们仔细看一下这个响应报文。它有三个部分:
初始状态行(status line),首部行(header line),然后是实体体(entity body)。
实体体部分是报文的主要部分,即它包含了所请求的对象本身(表示为data data data data…)。
状态行有3个字段:协议版本字段、状态码和相应状态信息。在这个例子中,状态行指示服务器正在使用 HTTP/1.1,并且一切正常(即服务器已经找到并正在发送所请求的对象)。
我们现在来看看首部行。服务器用Connection: close首部行告诉客户,发送完报文后将关闭该TCP连接。
Date:首部行指示服务器产生并发送该响应报文的日期和时间。值得一提的是,这个时间不是指对象创建或者最后修改的时间,而是服务器从它的文件系统中检索到该对象,插入到响应报文,并发送该响应报文的时间。
Server:首部行指示该报文是由一台 Apache Web 服务器产生的,它类似于HTTP请求报文中的 User- agent:首部行。
Last-Modified:首部行指示了对象创建或者最后修改的日期和时间。
Last- Modified:首部行对既可能在本地客户也可能在网络缓存服务器上的对象缓存来说非常重要。
Content- Length:首部行指示了被发送对象中的字节数。
Content-Type:首部行指示了实体体中的对象是HTML文本。
响应状态码
200 OK:请求成功,信息在返回的响应报文中。
301 Moved Permanently:请求的对象已经被永久转移了新的URL定义在响应报文的Location:首部行中,客户软件将自动获取新的URL。
400 Bad Request:一个通用差错代码,指示该请求不能被服务器理解。
404 Not Found:被请求的文档不在服务器上。
505 HTTP Version Not Supported:服务器不支持请求报
文使用的HTTP协议版本。
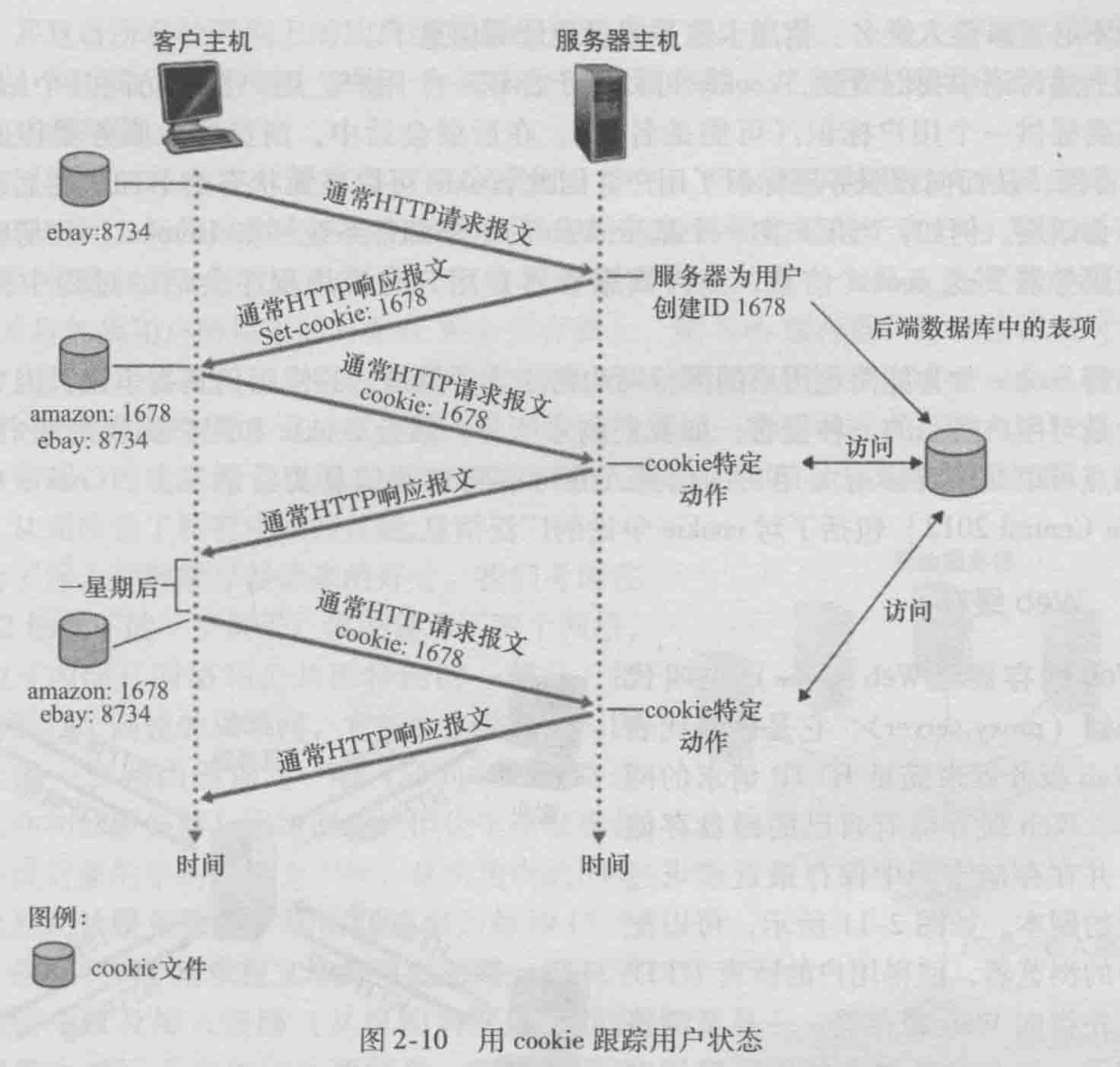
用户与服务器的交互:cookie
http是无状态的,要获取用户登录信息,故使用cookie
web缓存
Web 缓存器(Web cache)也叫代理服务器(proxy server),它是能够代表初始Web服务器来满足 HTTP请求的网络实体。Web缓存器有自己的磁盘存储空间,并在存储空间中保存最近请求过的对象的副本。
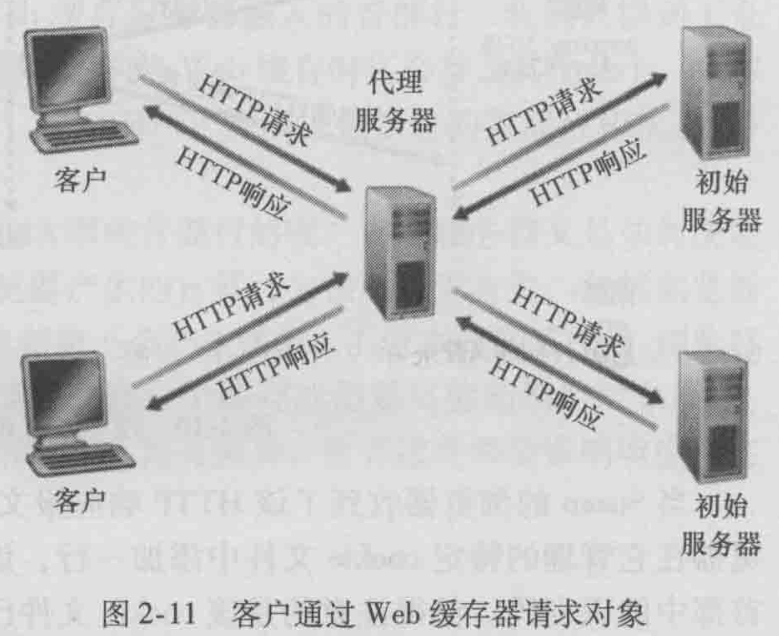
在因特网上部署Web缓存器有两个原因。首先,Web缓存器可以大大减少对客户请求的响应时间,特别是当客户与初始服务器之间的瓶颈带宽远低于客户与Web缓存器之间的瓶颈带宽时更是如此。如果在客户与Web缓存器之间有一个高速连接(情况常常如此),并且如果用户所请求的对象在Web缓存器上,则Web缓存器可以迅速将该对象交付给用户。
其次,如我们马上用例子说明的那样,Web缓存器能够大大减少一个机构的接人链路到因特网的通信量。通过减少通信量,该机构(如一家公司或者一所大学)就不必急于增加带宽,因此降低了费用。此外,Web缓存器能从整体上大大减低因特网上的 Web流量,从而改善了所有应用的性能。
内容分发网络(Content Distri-bution Network, CDN)
条件get
为了防止代理服务器上的内容是过时的,允许代理服务器使用条件get
如果:请求报文使用GET方法,并且请求报文中包含一个If-Modified-Since:首部行。
那么,这个 HTTP请求报文就是一个条件GET请求报文。

文件传输协议:FTP
ftp是有状态的
用户通过FTP用户代理与FTP交互。该用户首先提供远程主机的主机名,使本地主机的FTP客户进程建立一个到远程主机FTP服务器进程的TCP连接。该用户接着提供用户标识和口令,作为FTP命令的一部分在该 TCP连接上传送。一旦该服务器向该用户授权,用户可以将存放在本地文件系统中的一个或者多个文件复制到远程文件系统(反之亦然)。
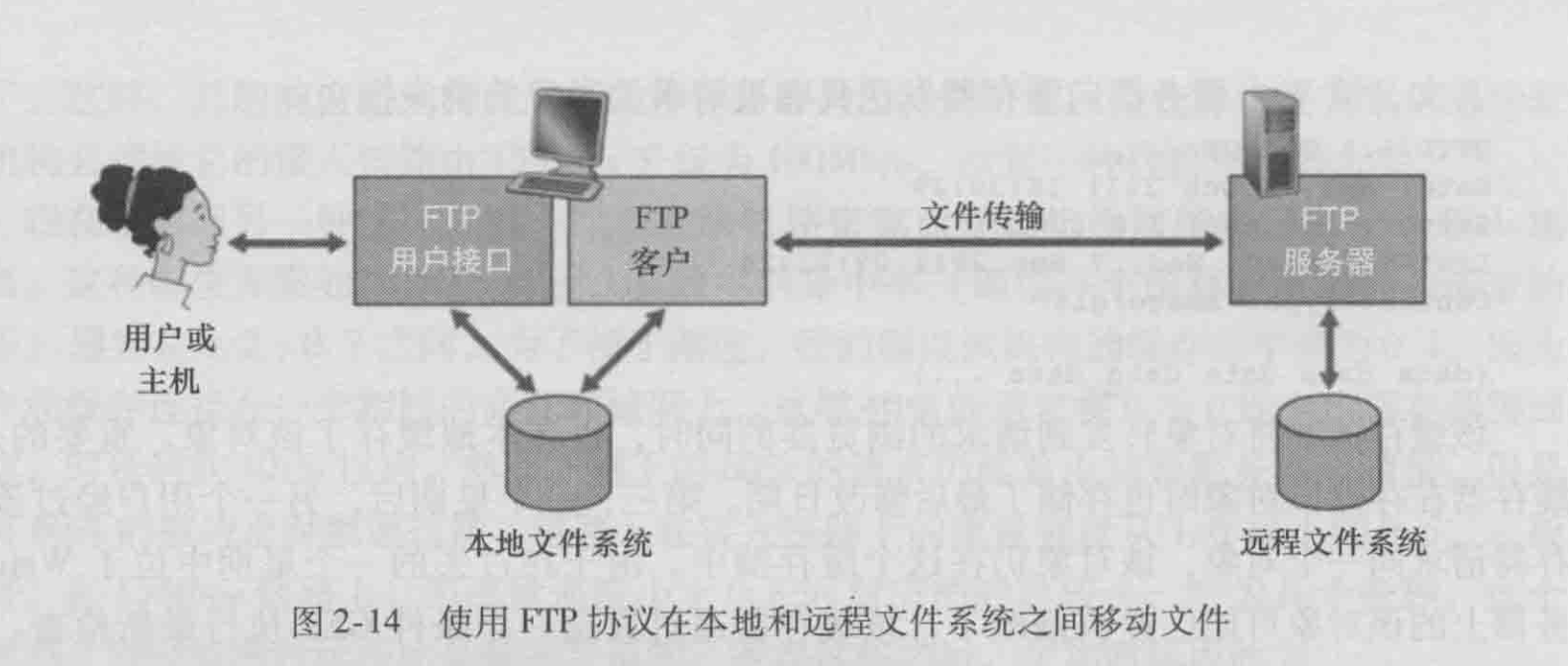
FTP使用了两个并行的TCP连接来传输文件,一个是控制连接(control connection),一个是数据连接(data connection)。connection)。
控制连接用于在两主机之间传输控制信息如用户标识、口令、改变远程目录的命令以及“存放(put)”和“获取(get)”文件的命令。
数据连接用于实际发送一个文件。因为FTP协议使用一个独立的控制连接,所以我们也称FTP的控制信息是带外(out-of-band)传送的。
当用户主机与远程主机开始一个FTP会话时,FTP的客户(用户)端首先在服务器21号端口与服务器(远程主机)端发起一个用于控制的 TCP连接。FTP的客户端也通过该控制连接发送用户的标识和口令,发送改变远程目录的命令。当FTP 的服务器端从该连接上收到文件传输的命令后(无论是向还是来自远程主机),就发起一个到客户端的TCP 数据连接。FTP在该数据连接上准确地传送一个文件,然后关闭该连接。在同一个会话期间,如果用户还需要传输另一个文件,FTP则打开另一个数据连接。因而对FTP传输而言,控制连接贯穿了整个用户会话期间,但是对会话中的每一次文件传输都需要建立一个新的数据连接(即数据连接是非持续的)。
ftp每个命令由4个ascii码组成\n分割
USER username:用于向服务器传送用户标识。PASS password:用于向服务器发送用户口令。
LIST:用于请求服务器回送当前远程目录中的所有文件列表。该文件列表是经一个(新建且非持续连接)数据连接传送的,而不是在控制TCP连接上传送。
RETR filename:用于从远程主机当前目录检索(即 get文件。该命令引起远程主机发起一个数据连接,并经该数据连接发送所请求的文件。
STOR filename:用于在远程主机的当前目录上存放(即put)文件。
Ftp状态码
331 Username OK, Password required(用户名OK,需要口令).
125 Data connection already open;transfer starting(数据连接已经打开,开始传送)。
425 Can’t open data connection(无法打开数据连接)。
452 Error writing file(写文件差错)。
因特网中的电子邮件
smtp使用持续连接
它有3个主要组成部分:用户代理(user agent)、邮件服务器(mail server)和简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)。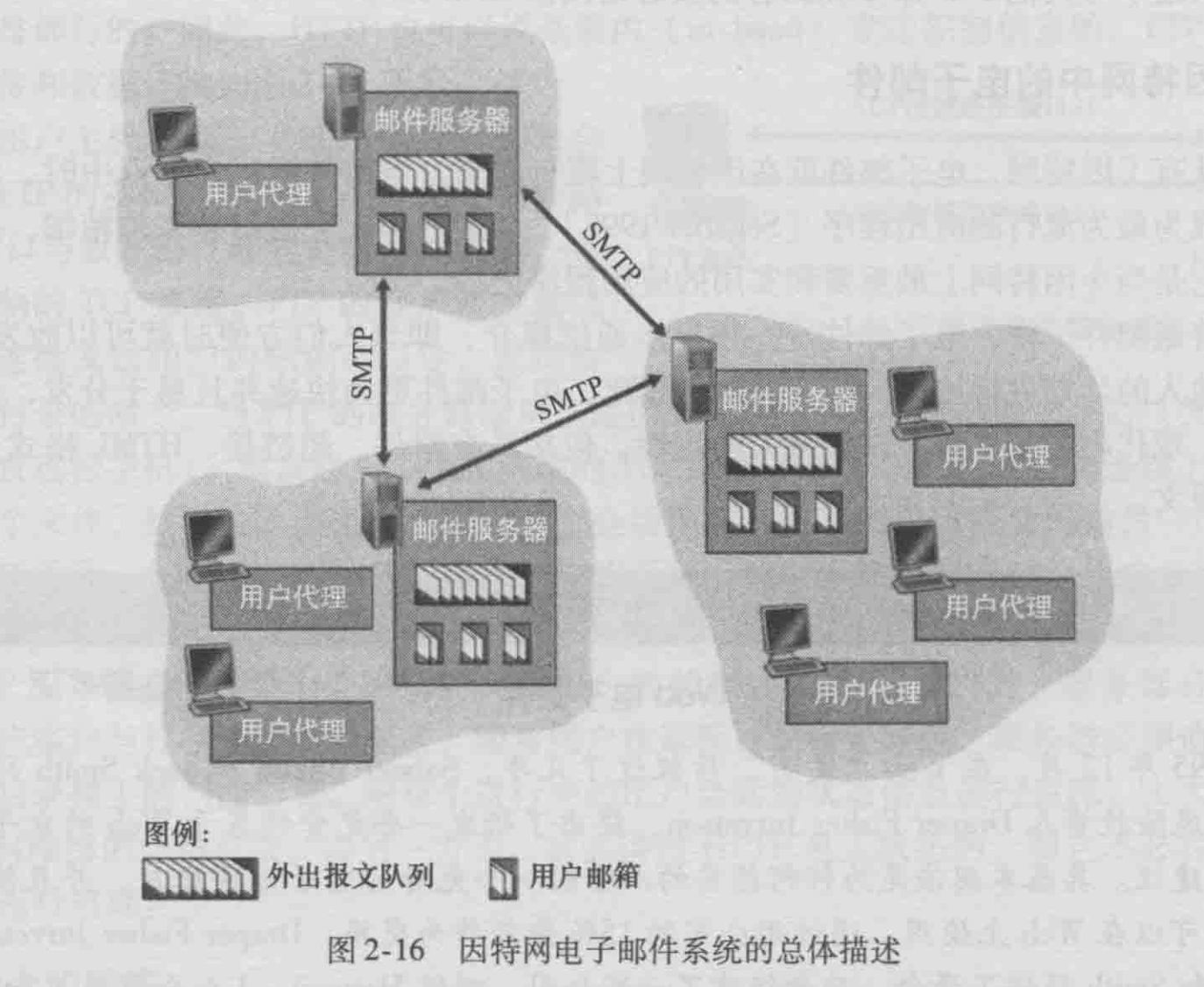
SMTP是如何将一个报文从发送邮件服务器传送到接收邮件服务器的?
首先,客户端SMTP(运行在发送邮件服务器上)在25号端口建立一个到服务器SMTP(在按收邮件服务器上)的TCP 连接。如果服务器没有开机,客户会在稍后继续尝试连接。一旦连接建立,服务器和客户执行某些应用层的握手。SMTP的客户和服务器在传输信息前先相互介绍。在SMTP握手的阶段,SMTP 客户指示发送方的邮件地址(产生报文的那个人)和接收方的邮件地址。一旦该SMTP 客户和服务器彼此介绍之后,客户发送该报文。SMTP 能依赖TCP提供的可靠数据传输无差错地将邮件投递到接收服务器。该客户如果有另外的报文要发送到该服务器,就在该相同的TCP连接上重复这种处理;否则,它指示TCP 关闭连接。
http和smtp
http是拉协议,从服务器往我们这里拉,smtp是推协议,从服务器往另一个服务器推。
smtp双方各有一个服务器,逻辑上a向b发文件,a是客户端,b是服务端,反之亦然。
邮件访问协议



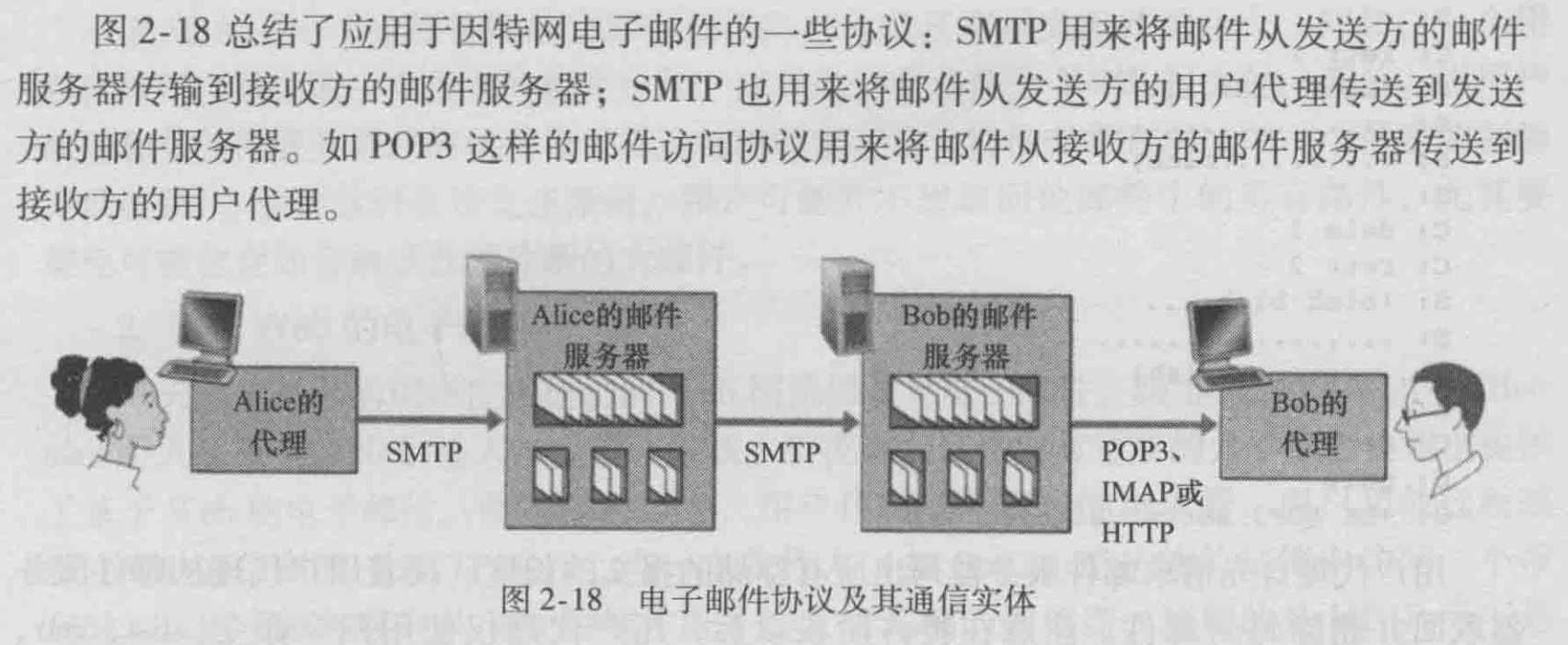
基于web的电子邮件
使用这种服务,用户代理就是普通的浏览器,用户和他远程邮箱之间的通信则通过HTTP进行。
当一个收件人,想从他的邮箱中访问一个报文时,该电子邮件报文从他邮件服务器发送到他的浏览器,使用的是HTTP而不是POP3或者IMAP协议。
当发件人要发送封电子邮件报文时,该电子邮件报文从他的浏览器发送到她的邮件服务器,使用的是 HTTP而不是SMTP。然而,他的邮件服务器在与其他的邮件服务器之间发送和接收邮件时,仍然使用的是SMTP。
DNS(Domain Name System, DNS)
DNS是:
一个由分层的 DNS 服务器(DNSserver)实现的分布式数据库;
一个使得主机能够查询分布式数据库的应用层协议。
DNS 服务器通常是运行 BIND (Berkeley Internet Name Domain)软件[BIND 2012]的UNIX 机器。DNS协议运行在UDP之上,使用53号端口。
dns服务

主机别名 (host aliasing)。有着复杂主机名的主机能拥有一个或者多个别名。
邮件服务器别名(mail server aliasing)。显而易见,人们也非常希望电子邮件地址好记忆。
负载分配(load distribution)。DNS也用于在冗余的服务器(如冗余的Web服务器等)之间进行负载分配。繁忙的站点(如 cnn.com)被冗余分布在多台服务器上。
dns工作原理



dns缓存
为了改善时延性能并减少在因特网上到处传输的DNS报文数量,DNS 广泛使用了缓存技术。DNS 缓存的原理非常简单。在一个请求链中,当某DNS服务器接收一个DNS 回答(例如,包含主机名到IP地址的映射)时,它能将该回答中的信息缓存在本地存储器中。
举—个例子,假定主机 apricot. poly. edu向 dns. poly.
edu 查询主机名 cnn.com 的IP地址。此后,假定过了几个小时,Polytechnic理工大学的另外一台主机如 kiwi. poly. edu也向dns. poly. edu查询相同的主机名。因为有了缓存,该本地DNS服务器可以立即返回cnn.com的IP地址,而不必查询任何其他DNS服务器。本地DNS服务器也能够缓存TLD服务器的iP地址,因而允许本地DNS绕过查询链中的根DNS服务器(这经常发生)。
dns记录和报文
共同实现 DNS分布式数据库的所有DNS服务器存储了资源记录(Resource Record,RR).RR提供了主机名到P地址的映射。
资源记录是一个包含了下列字段的4元组:(Name,Value, Type, TTL)
设一台edu TLD服务器不是主机 gaia. cs. umass. edu的权威DNS服务器,则该服务器将包含一条包括主机 cs. umass. edu的域记录,如 (umass. edu, dns. umass. edu, NS);该eduTLD服务器还将包含一条类型A记录,如(dns. umass.edu,128.119. 40.111, A),该记录将名字dns. umass.edu映射为一个iP地址。
ns就是本dns服务器没有你这个主机的ip,我告诉你一个dns服务器,你去那里找,我这里还有这个dns的服务器的ip
dns的查询和回答报文相同

dns攻击
对DNS 的潜在更为有效的DDoS攻击将是向顶级域名服务器(例如向所有处理.com域的顶级域名服务器)发送大量的 DNS请求。过滤指向DNS服务器的 DNS 请求将更为困难,并且顶级域名服务器不像根服务器那样容易绕过。但是这种攻击的严重性通过本地 DNS 服务器中的缓存技术可将部分地被缓解。
DNS能够潜在地以其他方式被攻击。在中间人攻击中,攻击者截获来自主机的请求并返回伪造的回答。在DNS毒害攻击中,攻击者向一台DNS服务器发送伪造的回答,诱使服务器在它的缓存中接收伪造的记录。这些攻击中的任一种,都能够将满怀信任的Web用户重定向到攻击者的Web 站点。然而,这些攻击难以实现,因为它们要求截获分组或扼制住服务器。
另一种重要的DNS攻击本质上并不是一种对DNS服务的攻击,而是充分利用 DNS基础设施来对目标主机发起 DDoS攻击(例如,你所在大字的邮件服分斋)。仕这利坟击中,攻击者向许多权威DNS服务器发送DNS请求,每个请求具有目标主机的假冒源地址。这些DNS服务器则直接向目标主机发送它们的回答。如果这些请求能够精心制作成下述方式的话,即响应比请求(字节数)大得多(所谓放大),则攻击者不必自行产生大量的流量就有可能淹没目标主机。这种利用 DNs的反射攻击至今为止只取得了有限的成功。
P2P
p2p文件分发


我们现在来对P2P体系结构进行简单的分析,其中每个对等方能够帮助服务器分发该文件。特别是,当一个对等方接收到某些文件数据,它能够使用自己的上载能力重新将数据分发给其他对等方。计算P2P体系结构的分发时间在某种程度上比计算客户-服务器体系结构的更为复杂,因为分发时间取决于每个对等方如何向其他对等方分发该文件的各个部分。
具有PP体系结构的应用程序能够是自扩展的。这种扩展性的直接成因是:对等方除了是比特的消费者外还是它们的重新分发者。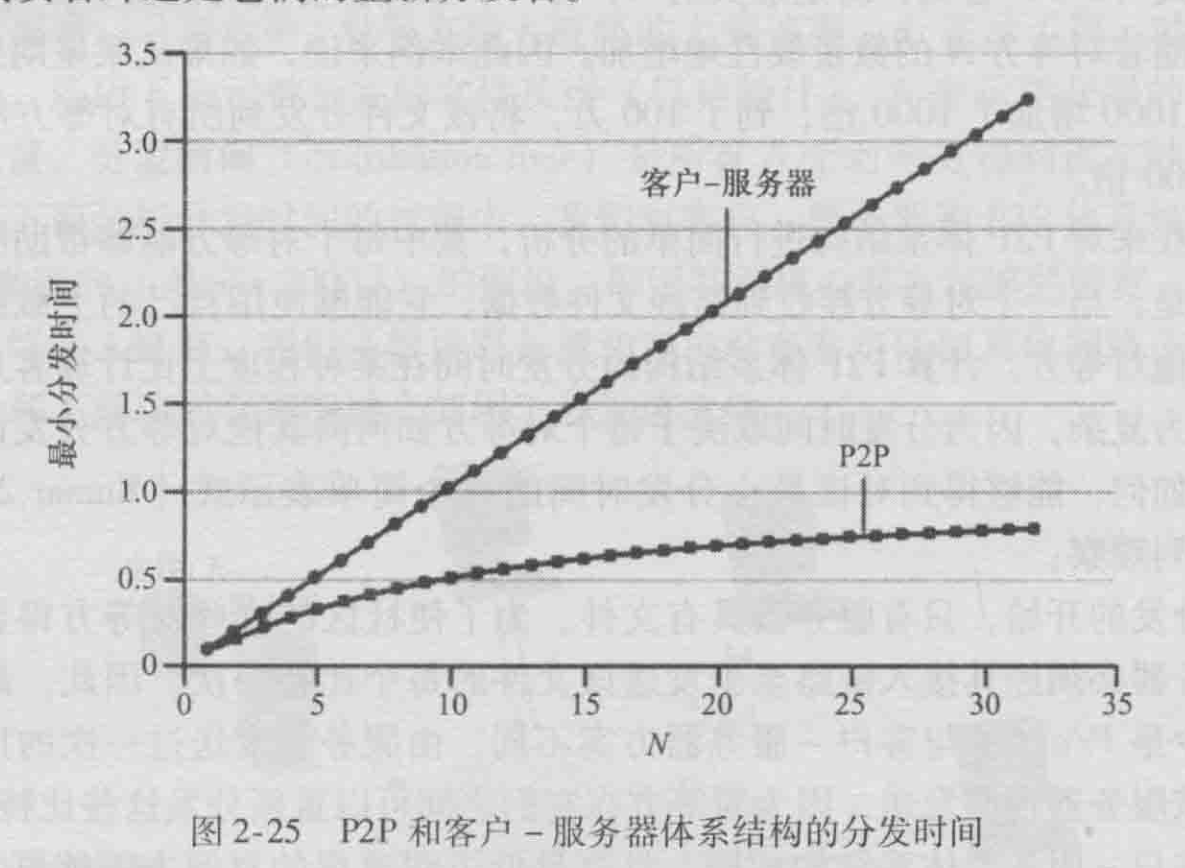
每个洪流具有一个基础设施结点,称为追踪器(tracker)。当一个对等方加人某洪流时,它向追踪器注册自己,并周期性地通知追踪器它仍在该洪流中。以这种方式,追踪器跟踪正参与在洪流中的对等方。一个给定的洪流可能在任何时刻具有数以百计或数以千计的对等方。
当一个新的对等方Alice加入该洪流时,追踪器随机地从参与对等方的集合中选择对等方的一个子集(为了具体起见,设有50个对等方),并将这50个对等方的P地址发送给 Alice。 Alice持有对等方的这张列表试图与该列表上的所有对等方创建并行的TCP连接。我们称所有这样与 Aliee成功地创建一个TCP 连接的对等方为“邻近对等方”(在图2-26中,Alice显示了仅有三个邻近对等方。通常,她应当有更多的对等方)。随着时间的流逝,这些对等方中的某些可能离开其他对等方(最初50个以外的)可能试图与Alice创建TCP 连接。因此一个对等方的邻近对等方将随时间而波动。
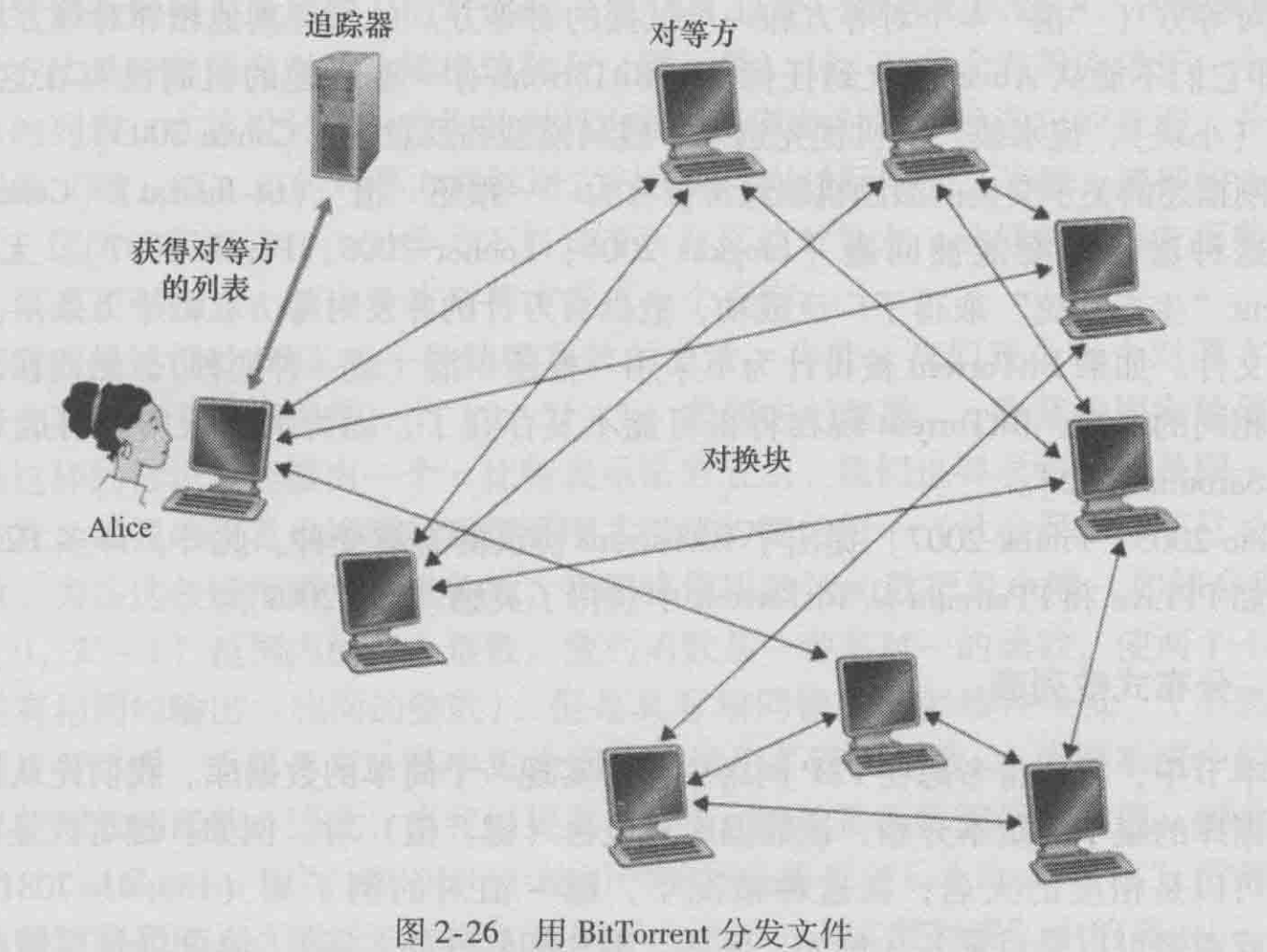
应当向哪些向她请求块的邻居发送?在决定请求哪些块的过程中,Alice使用一种称为最稀缺优先(rarest first)的技术。这种技术的思路是,针对她没有的块在她的邻居中决定最稀缺的块(最稀缺的块就是那些在她的邻居中副本数量最少的块),并首先请求那些最稀缺的块。这样,最稀缺块得到更为迅速的重新分发,其目标是(大致地)均衡每个块在洪流中的副本数量。
分布式散列表
在该P2P系统中,每个对等方将保持(键,值)对仅占总体的一个小子集。我们将允许任何对等方用一个特别的键来查询该分布式数据库。分布式数据库则将定位拥有该相应(键,值)对的对等方,然后向查询的对等方返回该(键,值)对。任何对等方也将允许在数据库中插入新键-值对。这样一种分布式数据库被称为分布式散列(Distributed Hash Table DHT)。
套接字编程
每一个套接字会分配一个端口
1.是否遵守RFC协议(不遵守则避开规定端口)
2.采用tcp还是udp
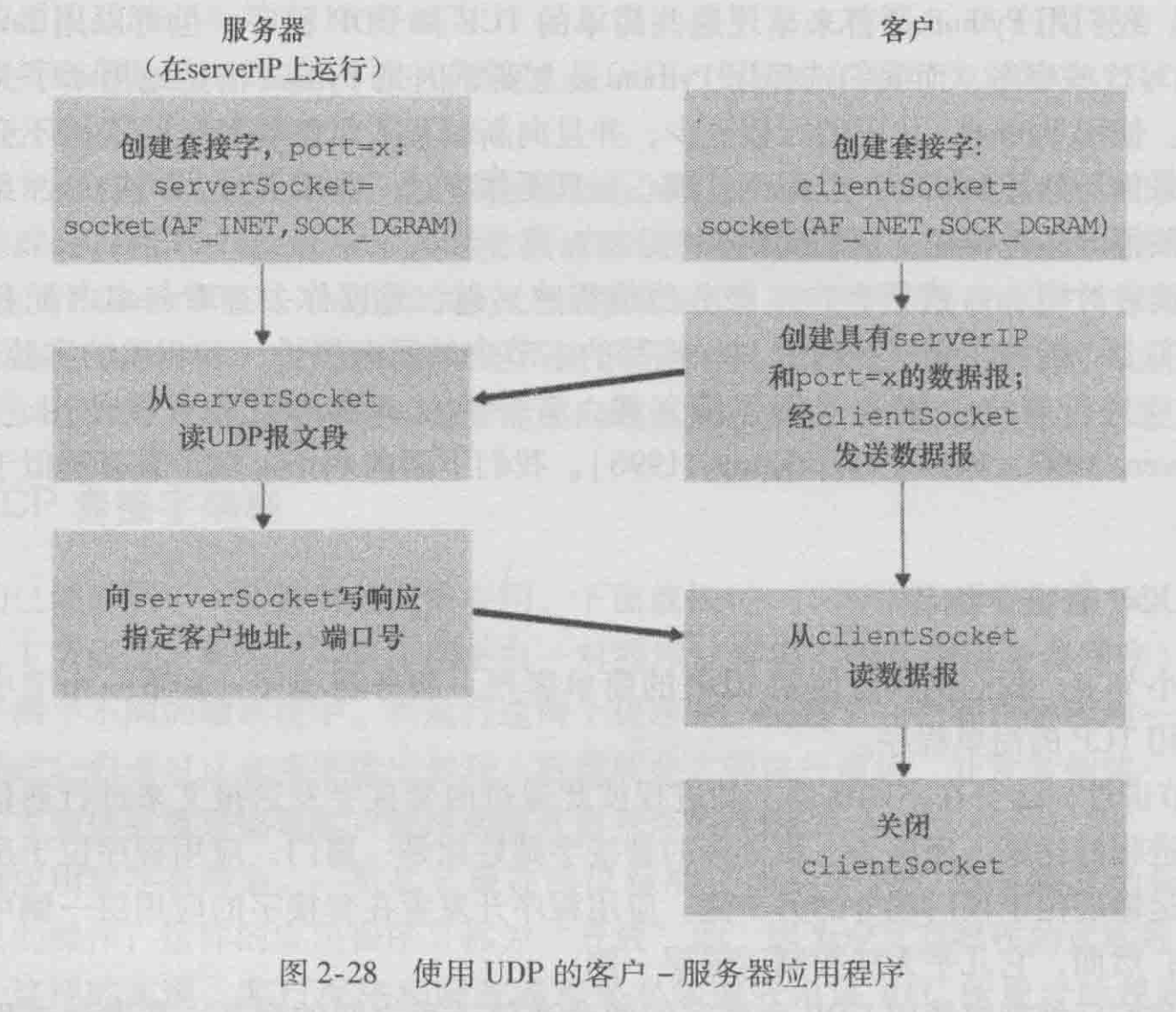
udp套接字编程
运行在不同机器上的进程彼此通过向套接字发送报文来进行通信。我们说过每个进程好比是一座房子,该进程的套接字则好比是一扇门。应用程序位于房子中门的一侧;运输层位于该门朝外的另一侧。应用程序开发者在套接字的应用层一侧可以控制所有东西;然而,它几乎无法控制运输层一侧。
我们将使用下列简单的客户-服务器应用程序来演示对于UDP和TCP的套接字编程:
1)客户从其键盘读取一行字符并将数据向服务器发送。
2)服务器接收该数据并将这些字符转换为大写。
3)服务器将修改的数据发送给客户。
4)客户接收修改的数据并在其监视器上将该行显示出
udpclient.py
1 | from socket import* |
udpserver.py
1 | from socket import * |
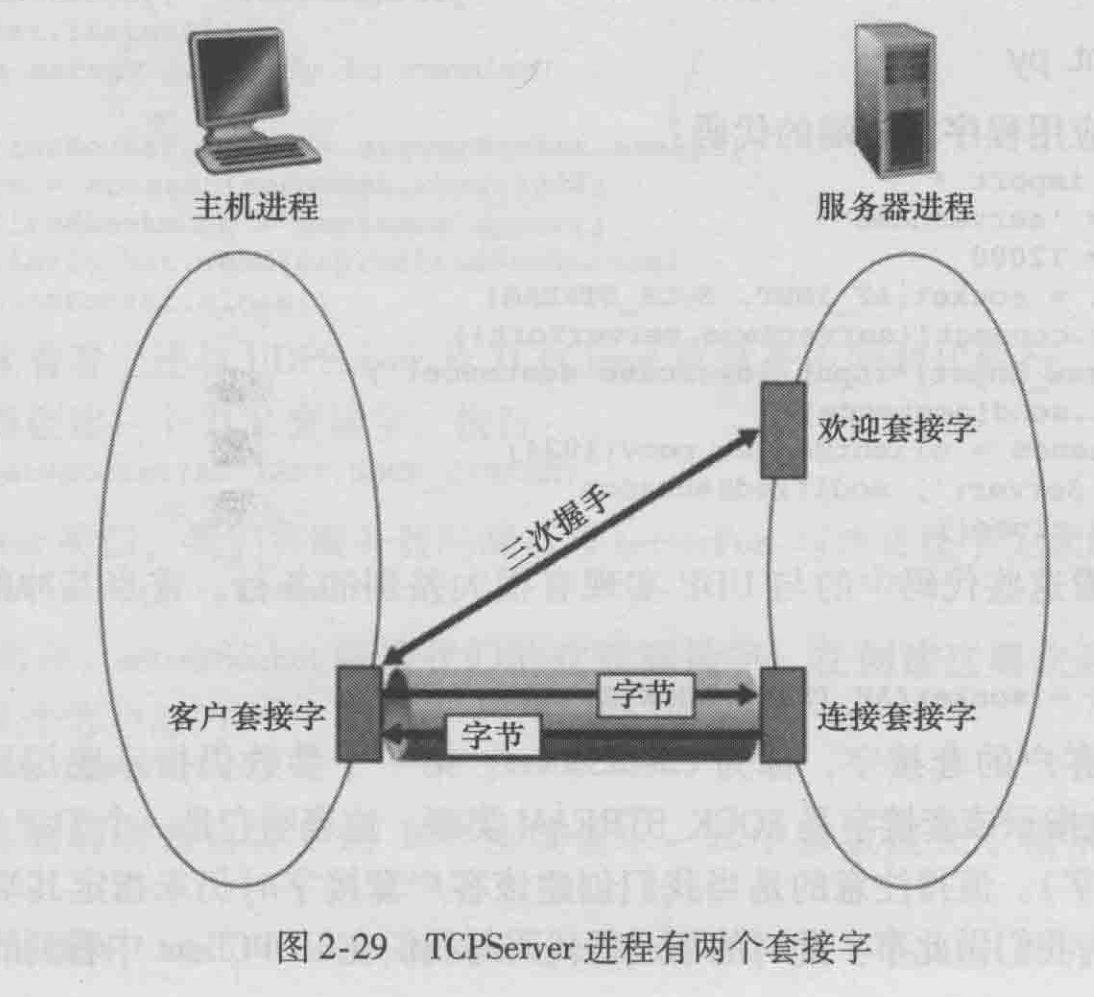
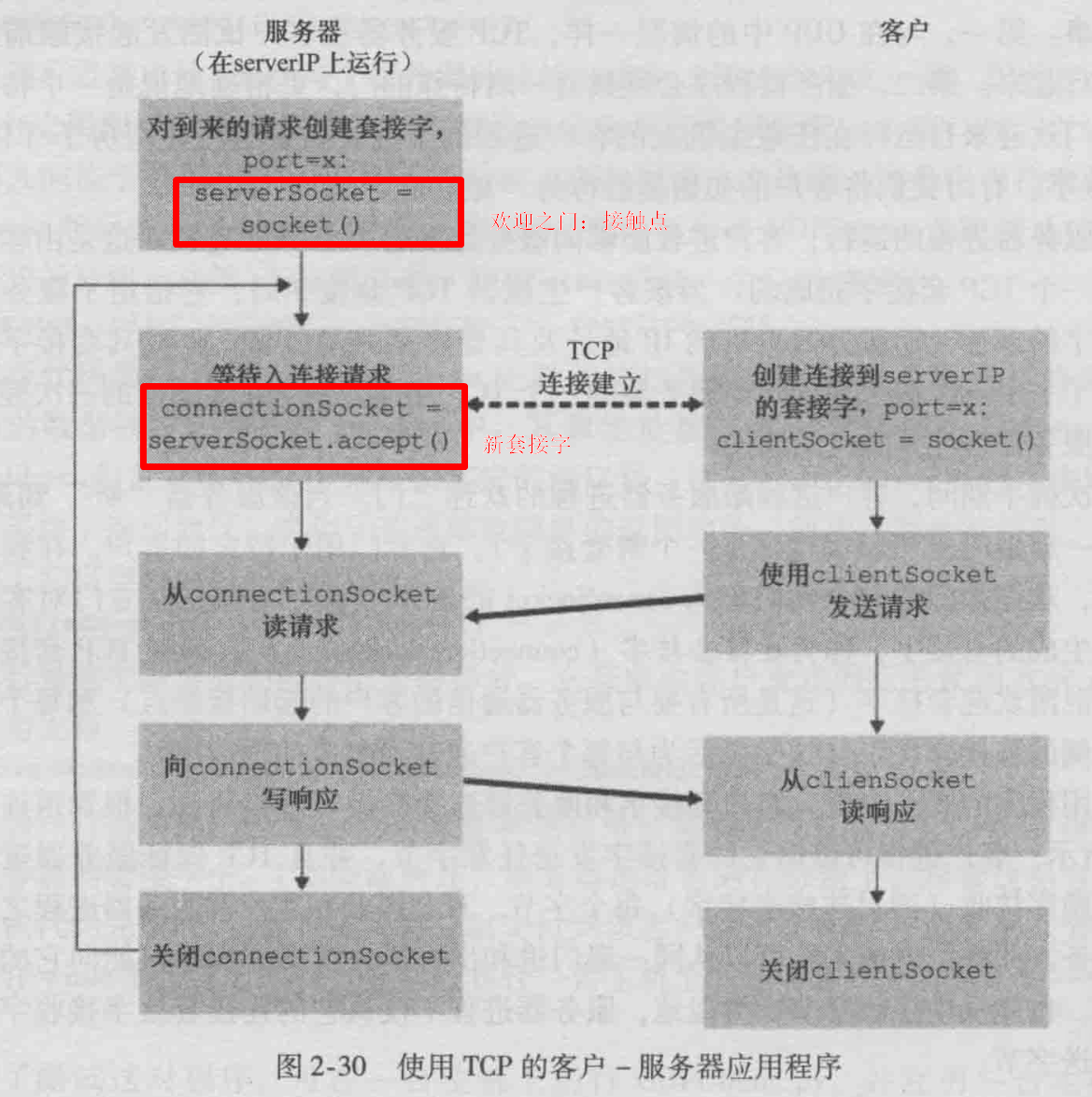
tcp套接字编程
与UDP 不同,TCP是一个面向连接的协议。这意味着在客户和服务器能够开始互相发送数据之前,它们先要握手和创建一个 TCP连接。
TCP连接的一端与客户套接字相联系,另一端与服务器套接字相联系。当创建该TCP连接时,我们将其与客户套接字地址(IP地址和端口号)和服务器套接字地址(IP地址和端口号) 关联起来。使用创建的TCP连接,当一侧要向另一侧发送数据时,它只需经过其套接字将数据丢给TCP连接。UDP 服务器在将分组丢进套接字之前必须为其附上一个
目的地地址。
随着服务器进程的运行,客户进程能够向服务器发起一个TCP连接。这是由客户程序通过创建一个 TCP套接字完成的。当该客户生成其 TCP
套接字时,它指定了服务器中的套接字的地址,即服务器主机的P地址及其套接字的端口号。生成其套接字后,该客户发起了一个三次握手并创建与服务器的一个TCP连接。发生在运输层的三次握手,对于客户和服务器程序是完全透明的。
在三次握手期间,客户进程敲服务器进程的欢迎之门。当该服务器“听”到敲门时,**它将生成一扇新门(更精确地讲是一个新套接字)**,它专门用于特定的客户。在我们下面的例子中,欢迎之门是一个我们称为 serverSocket 的 TCp套接字对象;它专门对客户进行连接的新生成的套接字,称为连接套接字(connection Socket)。初次遇到TCP套接字的学生有时会混淆欢迎套接字(这是所有要与服务器通信的客户的起始接触点)和每个新生成的服务器侧的连接套接字(这是随后为与每个客户通信而生成的套接字)。
tcpclient.py
1 | from socket import * |
tcpserver.py
1 | from socket import * |
复习和习题
前面讲过TCP能用SSL来强化,以提供进程到进程的安全性服务,包括加密。SSL 运行在运输层还是应用层?如果某应用程序研制者想要用SSL 来强化UDP,该研制者应当做些什么工作?
SSL在应用层运行。SSL套接字从应用层接收未加密的数据,对其进行加密,然后将其传递给TCP套接宇。如果应用程序开发人员希望使用SSL增强TCP,则必须在应用程序中包含SSL代码。
为什么 HTTP、FTP、SMTP 及POP3都运行在TCP,而不是 UDP上?
与这些协议相关联的应用程序要求以正确的顺序接收所有应用程序数据,并且不存在空白。TCP提供此服务,而UDP不提供此服务。
考虑一个电子商务网站需要保留每一个客户的购买记录。描述如何使用cookie来完成该功能?
当用户第一次访问站点时,服务器将创建一个唯一的标识号,在其后端数据库中创建一个条目,并将此标识号作为cokie编号返回。此cookie编号存储在用户的主机上,并由浏览器管理。在每次后续访问(和购买)期间,浏览器将cookie编号发送回站点。因此,站点知道这个用户(更准确地说,是这个浏览器)访问该站点的时间.
假定Alice使用一个基于Web的电子邮件账户(例如Hotmail或gmail)向Bob发报文,而Bob使用POP3从他的邮件服务器访问自己的邮件。讨论是怎样从 Alice 王机到 bob王机得到以报义的。安列出在两台主机间移动该报文时所使用的各种应用层协议。
该消息⾸先通过HTTP从Alice的主机发送到她的邮件服务器。然后,Alice的邮件服务器通过SMTP向Bob的邮件服务器发送消息。然后Bob通过POP3将消息从他的邮件服务器传输到他的主机。
从用户的观点看,POP3协议中下载并删除模式和下载并保留模式有什么区别吗?
通过下载和删除,⽤⼾从POP服务器检索其消息后,消息将被删除。这给游牧⽤⼾带来了⼀个问题,他们可能希望从许多不同的机器(办公PC、家庭PC等)访问消息。在下载和保存配置中,在⽤⼾检索消息后不会删除消息。这也可能不⽅便,因为每次⽤⼾从新机器检索存储的消息时,所有未删除的消息都将传输到新机器(包括⾮常旧的消息)。
UDP服务器仅需要一个套接字,而TCP服务器需要两个套接字。
为什么?如果TCP 服务器支持n个并行连接,每条连接来自不同的客户主机,那么TCP服务器将需要多少个套接字?UDP服务器只需要一个套接字,因为UDP是无连接的,它不需要维护连接状态。而TCP服务器需要两个套接字,一个用于监听客户端连接请求,另一个用于处理与客户端的通信.如果TCP服务器支持n个并行连接,每条连接来自不同的客户主机,那么TCP服务器将需要n+1个套接字,其中一个用于监听客户端连接请求,其余n+1个用于处理与客户端的通信。
7.运行在 TCP之上的客户-服务器应用程序,服务器程序为什么必须先于客户程序运行?对于运行在 UDP之上的客户-服务器应用程序,客户程序为什么可以先于服务器程序运行?
对于TCP应⽤程序,⼀旦客⼾端被执⾏,它就会尝试启动与服务器的TCP连接。如果TCP服务器没有运⾏,则客⼾端将⽆法建⽴连接。对于UDP应⽤程序,客⼾端在执⾏时不会⽴即启动连接(或尝试与UDP服务器通信)。
假设用户请求由某些文本和3幅图像组成的Web页面。对于这个页面,客户将发送一个请求报文并接收4个响应报文。
请求与响应必定成对.对于这个页面,客户端将发送一个请求报文并接收一个响应报文,该响应报文包含页面的文本内容和3幅图像的URL。之后,客户端将根据这些URL发送3个请求报文,并分别接收3个响应报文,这些响应报文包含3幅图像的内容。因此,客户端总共发送4个请求报文并接收4个响应报文。
两个不同的Web页面(例如,www.mit. edu/ research. html 及 www.mit. edu/ students. html)可以通过同一个持续连接发送。
是的,两个不同的Web页面可以通过同一个持续连接发送。HTTP/1.1支持持久连接(也称为持续连接或连接重用),这意味着在同一连接上可以发送多个HTTP请求和响应。当客户端通过TCP连接发送第一个HTTP请求时,它可以在请求头中指定“Connection: keep-alive”,以指示服务器在响应中保持连接打开状态。这样,客户端就可以通过同一个连接发送多个请求,而不必为每个请求都建立一个新的TCP连接。当客户端完成所有请求时,它可以在最后一个请求中发送“Connection: close”头,以指示服务器关闭连接。
在浏览器和初始服务器之间使用非持续连接的话,一个TCP报文段是可能携带两个不同的 HTTP服务请求报文的。
在非持续连接中,一个TCP报文段只能携带一个HTTP请求报文。因为在非持续连接中,每个HTTP请求都需要建立一个新的TCP连接,因此每个连接只能携带一个HTTP请求和响应。如果多个HTTP请求在短时间内发生,它们将会被分别发送到不同的TCP连接中。每个TCP连接只能处理一个HTTP请求和响应。
在HTTP 响应报文中的Date:首部指出了该响应中对象最后一次修改的时间。
在HTTP响应报文中,Date首部字段表示服务器发送响应的时间。它不指示响应中对象最后一次修改的时间。为了指示对象最后一次修改的时间,HTTP响应报文使用Last-Modified首部字段。Last-Modified首部字段表示服务器上响应对象最后一次修改的时间。当客户端再次请求同一对象时,可以使用If-Modified-Since请求首部字段将上次的Last-Modified时间发送到服务器。如果服务器上的对象自上次访问以来未被修改,则服务器将返回一个状态码为304的响应,表示客户端可以使用其本地缓存的对象。否则,服务器将返回新的对象并在响应头中更新Last-Modified时间。
考虑一个HTTP客户要获取一个给定 URL的Web页面。该HTTP服务器的P地址开始时并不知道。在这种情况下,除了HTTP外,还需要什么运输层和应用层协议?
应⽤层协议:DNS和HTTP传输层协议:UDP⽤于DNS;TCP⽤于HTTP

由浏览器请求的文档的URL是什么?文档请求是http://gaia.cs.umass.edu/cs453/index.html。host:字段表示服务器的名称,/cs453/index.html表示文件名。
该浏览器运行的是HTTP的何种版本?
浏览器正在运⾏HTTP1.1版本,就像第⼀对之前所指出的那样
该浏览器请求的是一条非持续连接还是一条持续连接?
connection 浏览器正在请求持久连接,如连接所⽰:保持-活动。
该浏览器所运行的主机的P地址是什么?
这是刁钻的问题。此信息不包含在任何地⽅的HTTP消息中。因此,仅看HTTP消息的交换就⽆法区分这⼀点。您需要从IP数据报(承载承载HTTPGET请求的TCP段)中获得信息来回答这个问题。
发起该报文的浏览器的类型是什么?在一个 HTTP 请求报文中,为什么需要浏览器类型?
Mozilla/5.0。服务器需要浏览器类型信息将同⼀对象的不同版本发送到不同类型的浏览器。
14.
服务器能否成功地找到那个文档?该文档提供回答是什么时间?
状态代码200和短语ok表⽰服务器能够找到⽂档成功。答复于2008年3⽉7⽇星期⼆提供格林威治标准时间12:39:45。
该文档最后修改是什么时间?
last-Modified 上⼀次修改index.html⽂档是在2005年12⽉10⽇星期六18:27:46 格林尼治时间。
文档中被返回的字节有多少?
返回的⽂档中有3874个字节。
文档被返回的前5个字节是什么?该服务器同意一条持续连接吗?
返回⽂件的前五个字节是:<!医⽣服务器同意持久连接,如connection:Keep Alive字段所⽰
15.
解释在客户和服务器之间用于指示关闭持续连接的信令机制。客户、服务器或两者都能发送信令通知连接关闭了吗?
在RFC 2616的第8节中讨论了持久连接(这⼀点的真正⽬的问题是让你检索并阅读⼀份RFC(第8.1.2和8.1.2.1节)rfc表⽰客⼾机或服务器可以向另⼀个表明它是将关闭永久连接。它通过包含连接令牌来实现“关闭”在http请求/回复的连接头字段中
HTTP提供了什么加密服务?
http不提供任何加密服务。
一个客户能够与一个给定的服务器打开3条或更多条并发连接吗?
“使⽤持久连接的客⼾端应该限制同时维护到给定服务器的连接。单⽤⼾客⼾端与任何服务器或代理服务器的连接不应超过2个。
如果一个服务器或一个客户检测到连接已经空闲一段时间,该服务器或客户可以关闭两者之间的传输连接。一侧开始关闭连接而另一侧通过该连接传输数据是可能的吗?请解释。
是。(来⾃RFC 2616)“在服务器决定关闭”空闲“连接的同时,客⼾端可能已经开始发送新请求。从服务器的⻆度来看,连接是在空闲时关闭的,但从客⼾端的⻆度来看,请求正在进⾏中。“
- 假定你在浏览器中点击一条超链接获得Web页面。相关联的URL 的IP地址没有缓存在本地主机上,因此必须使用 DNS lookup以获得该IP地址。如果主机从 DNS得到IP地址之前已经访问了n个 DNS服务器;相继产生的RTT依次为RTT1,、…、RTTn,。进一步假定与链路相关的Web页面只包含一个对象,即由少量的HTML文本组成。令RTT0,表示本地主机和包含对象的服务器之间的RTT值。假定该对象传输时间为零,则从客户点击该超链接到它接收到该对象需要多长时间?
RTT1+RTT2+…+RTTn为获取ip的时间
总时间为2RTT0+RTT1+RTT2+…+RTTn
因为一个 RTT 就是一个往返的时延,因此访问 DNS 的时延是 1~n 各 1 个,接着 HTTP 采取 TCP 连接,需要在第一个 RTT 内建立连接,第二个 RTT 内发送请求并接收应答,故有两个 RTT0
- 参照上题,假定在同一服务器上某HTML文件引用了8个非常小的对象。忽略发送时间,在下列情况下需要多长时间:
a没有并行 TCP 连接的非持续HTTP。18RTT0+RTT1+RTT2+…+RTTn
其他部分与第七题一样,然后客户发送一个 HTTP 请求,得到基本 HTML 文件后,经过解析这个 HTML 文件得到 8 个图像的地址,再继续同样的 HTTP 请求 8 次,即在第七题基础上多了 8 个图像的建立连接、请求响应,注意非持续性连接在发送响应后,TCP 连接就立刻断开了,需要继续发送则需要重新申请建立连接
b.配置有5个并行连接的非持续HTTP。
6RTT0+RTT1+…+RTTn
客户仍需先请求建立 TCP 连接、发送数据请求并接受 HTML基本文件,消耗 2 个 RTT0,接着解析 HTML 文件后同时申请建立 5 个 TCP 连接,消耗 1 个RTT0,请求并接收 5 个图像,消耗 1 个 RTT0,还余下 3 个 RTT0 仍需申请建立 3 个 TCP 连接、请求并接收 3 个图像
c.持续HTTP。
无并行) 10RTT0+RTT1+…+RTTn【持续性链接即 a 省掉后续 8 次申请 TCP 的 RTT0】
(5 并行) 3RTT0+RTT1+…+RTTn (不理解,我觉得是4rtt0不是3)
HTTP 响应报文绝不会具有空的报文体。
答:错误。HTTP 调用 TCP,必定有确认报文段,如果没有消息回复则无法捎带确认,就会发送一个空内容的报文用于确认
SMTP是怎样标识一个报文体结束的?HTTP是怎样做的呢?HTTP能够使用与SMTP标识一个报文体结束相同的方法吗?试解释。
SMTP使⽤仅包含句点的⾏来标记邮件正⽂的结束。http使⽤“内容⻓度标题字段”来表⽰消息正⽂的⻓度。
不,HTTP不能使⽤SMTP使⽤的⽅法,因为HTTP消息可以是⼆进制数据,⽽在SMTP中,消息主体必须是7位的ASCII格式。什么是 whois数据库?
对于给定的域名输⼊(如ccn.com)、IP地址或⽹络管理员名称,whois数据库可⽤于定位相应的注册服务器、whois服务器、DNS服务器等。

假设你所在系具有一台用于系里所有计算机的本地DNS服务器。你是普通用户(即你不是网络/系统管理员)。你能够确定是否在几秒钟前从你系里的一台计算机可能访问过一台外部Web站点吗?解释原因。
是的,我们可以在本地DNS服务器中使⽤DIG查询该⽹站。例如,digCNN.com将返回查找CNN.com的查询时间。如果CNN.com⼏秒钟前刚刚被访问,那么
CNN.com的条⽬将缓存在本地DNS缓存中,因此查询时间为0毫秒。否则,查询时间很⻓。
不知道他是怎么按这个公式算出来的

在一台主机上安装编译 TCPClient 和 UDPClient 的 Python 程序,在另一台主机上安装编译TCPServer 和 UDPServer 的程序。
a.假设在运行 TCPServer 之前运行 TCPClient,将会发生什么现象?为什么?答:如果首先运行 TCPClient,那么客户端将尝试与不存在的服务器进程进行 TCP 连接。无法进行 TCP 连接。
b.假设在运行 UDPServer 之前运行 UDPClient,将会发生什么现象?为什么?
答:UDPClient 没有与服务器建立 TCP 连接。 因此,如果首先运行 UDPClient,然后运行 UDPServer,然后在键盘上键入一些输入,那么一切都会正常工作
代码
在这个编程作业中,你将用Python语言开发一个简单的Web服务器,它仅能处理一个请求。具体而言,你的Web服务器将:
当一个客户(浏览器)联系时创建一个连接套接字;
从这个连接套接字接收HTTP请求;
解释该请求以确定所请求的特定文件;
从服务器的文件系统获得请求的文件;
创建一个由请求的文件组成的HTTP响应报文,报文前面有首部行;
经TCP连接向请求浏览器发送响应。如果浏览器请求一个在该服务器种不存在的文件,服务器应当返回一个“404 Not Found”差错报文。
webserver.py
在内网内可以进行交流
1 | from socket import * |
在这个编程作业中,你将用Python编写一个客户ping程序。该客户将发送一个简单的ping报文,接受一个从服务器返回的pong报文,并确定从该客户发送ping报文到接收到pong报文为止的时延。该时延称为往返时延(RTT)。由该客户和服务器提供的功能类似于在现代操作系统中可用的标准ping程序,然而,标准的ping使用互联网控制报文协议(ICMP)(我们将在第4章中学习ICMP)。此时我们将创建一个非标准(但简单)的基于UDP的ping程序。
你的ping程序经UDP向目标服务器发送10个ping报文,对于每个报文,当对应的pong报文返回时,你的客户要确定和打印RTT。因为UDP是一个不可靠协议,由客户发送的分组可能会丢失。为此,客户不能无限期地等待对ping报文的回答。客户等待服务器回答的时间至多为1秒;如果没有收到回答,客户假定该分组丢失并相应地打印一条报文。
UDPPinger.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20from socket import *
import time
serverName = '191.101.232.165' # 服务器地址,本例中使用一台远程主机
serverPort = 12000 # 服务器指定的端口
clientSocket = socket(AF_INET, SOCK_DGRAM) # 创建UDP套接字,使用IPv4协议
clientSocket.settimeout(1) # 设置套接字超时值1秒
for i in range(0, 10):
sendTime = time.time()
message = ('Ping %d %s' % (i+1, sendTime)).encode() # 生成数据报,编码为bytes以便发送
try:
clientSocket.sendto(message, (serverName, serverPort)) # 将信息发送到服务器
modifiedMessage, serverAddress = clientSocket.recvfrom(1024) # 从服务器接收信息,同时也能得到服务器地址
rtt = time.time() - sendTime # 计算往返时间
print('Sequence %d: Reply from %s RTT = %.3fs' % (i+1, serverName, rtt)) # 显示信息
except Exception as e:
print('Sequence %d: Request timed out' % (i+1))
clientSocket.close() # 关闭套接字
UDPPingerServer.py
1 | # UDPPingerServer.py |
在这个编程作业中,你将研发一个简单的Web代理服务器。当你的代理服务器从一个浏览器收到某对象的HTTP请求,它生成对相同对象的一个新HTTP请求并向初始服务器发送。当该代理从初始服务器接收到具有该对象的HTTP响应时,它生成一个包括该对象的新HTTP响应,并发送给该客户。这个代理将是多线程的,使其在相同时间能够处理多个请求。
讲解
WebProxy.py
1 | #coding:utf-8 |
- nslookup www.mit.edu
说这个命令是说,请告诉我主机 www.mit.edu 的IP地址。如屏幕截图所示,此命令的响应提供两条信息:(1)提供响应的DNS服务器的名称和IP地址;(2)响应本身,即 www.mit.edu 的主机名和IP地址。虽然响应来自理工大学的本地DNS服务器,但本地DNS服务器很可能会迭代地联系其他几个DNS服务器来获得结果,如书中第2.4节所述。

